TCP半连接全连接(一) -- 全连接队列相关过程
梳理学习TCP建立连接相关过程和全连接队列,结合相关配置进行实验。
1. 背景
最近碰到一个服务端程序处理请求时没有响应的问题,协助尝试定位。初步抓包和ss/netstat定位是服务端一直没对第一次SYN做响应,也能观察到listen队列溢出了。服务端基于python框架,通过多进程进行监听处理。
在另一个环境进行复现后,发现出问题的子进程有连接一直处于CLOSE_WAIT且不响应其他请求,全连接队列也是满的。pstack/strace/ltrace一通下来只跟踪到基本都在等条件变量,也没有死锁之类的。
平时都写C++,涉及到python的只是一些胶水脚本,所以暂时阻塞在怀疑业务逻辑某处卡死导致没最后发FIN关闭进而丢弃新的SYN,具体哪里出问题受限于python方面学艺不精就没辙定位了。
另一个背景是 知识星球-程序员踩坑案例分享(宝藏星球)里正好有个案例,涉及定位过程中一些知识点和工具,一些概念发现自己还是掌握得不够清晰和深入。
趁此机会,重新全面梳理一下网络相关流程,加之近期也折腾学习过了一些工具(systemtap/ebpf/packagedrill/scapy),进行一些实验。
本篇先说明TCP三次握手相关过程。
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 前置说明
主要基于这篇文章:”从一次线上问题说起,详解 TCP 半连接队列、全连接队列“,进行学习和扩展。
环境:起两个阿里云抢占式实例,Alibaba Cloud Linux 3.2104 LTS 64位(内核版本:5.10.134-16.1.al8.x86_64)
基于5.10内核代码跟踪流程
3. TCP握手和断开总体流程
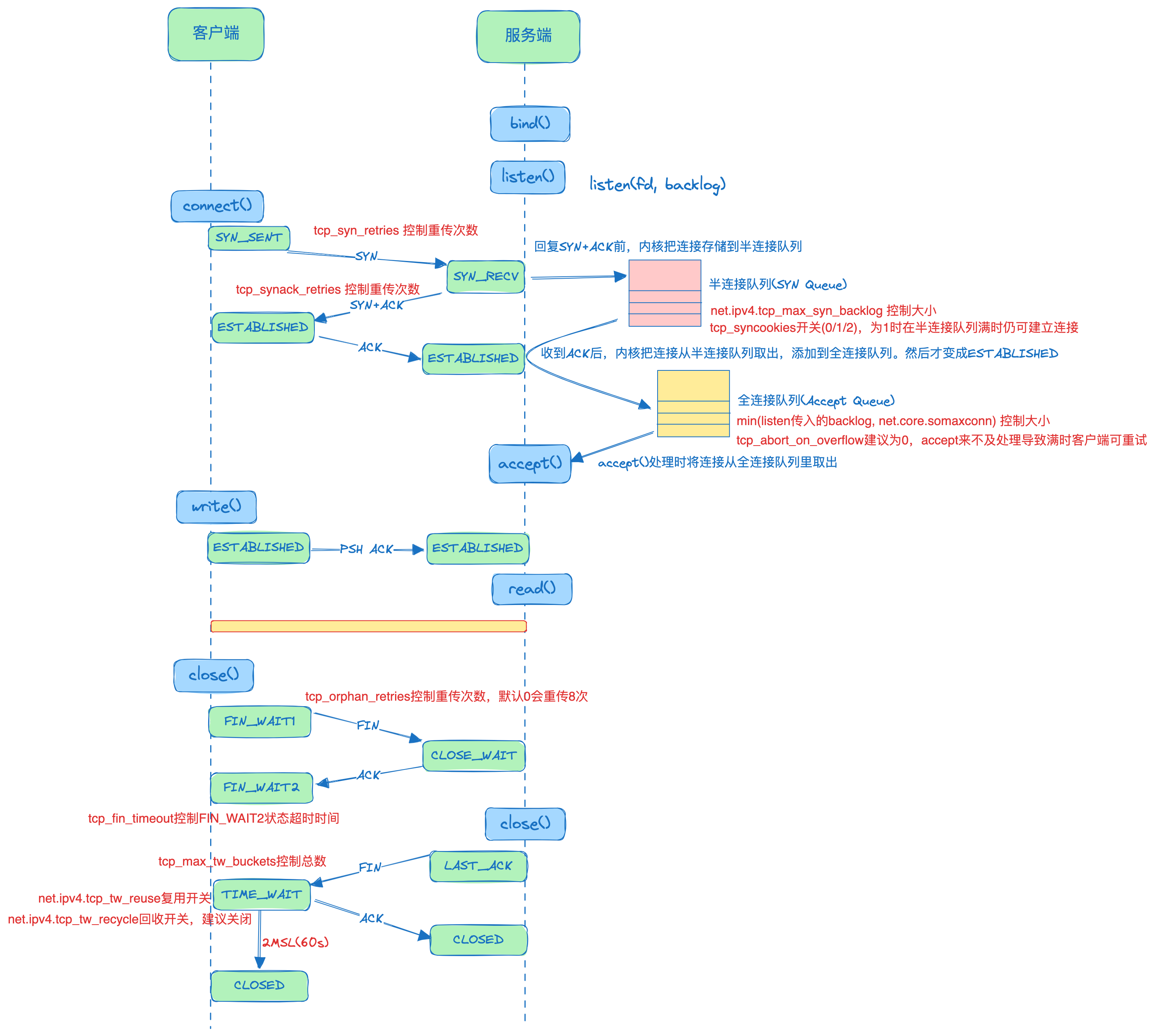
说明:三次握手时,客户端先设置SYN_SENT状态再发SYN
上图中TCP相关参数配置说明: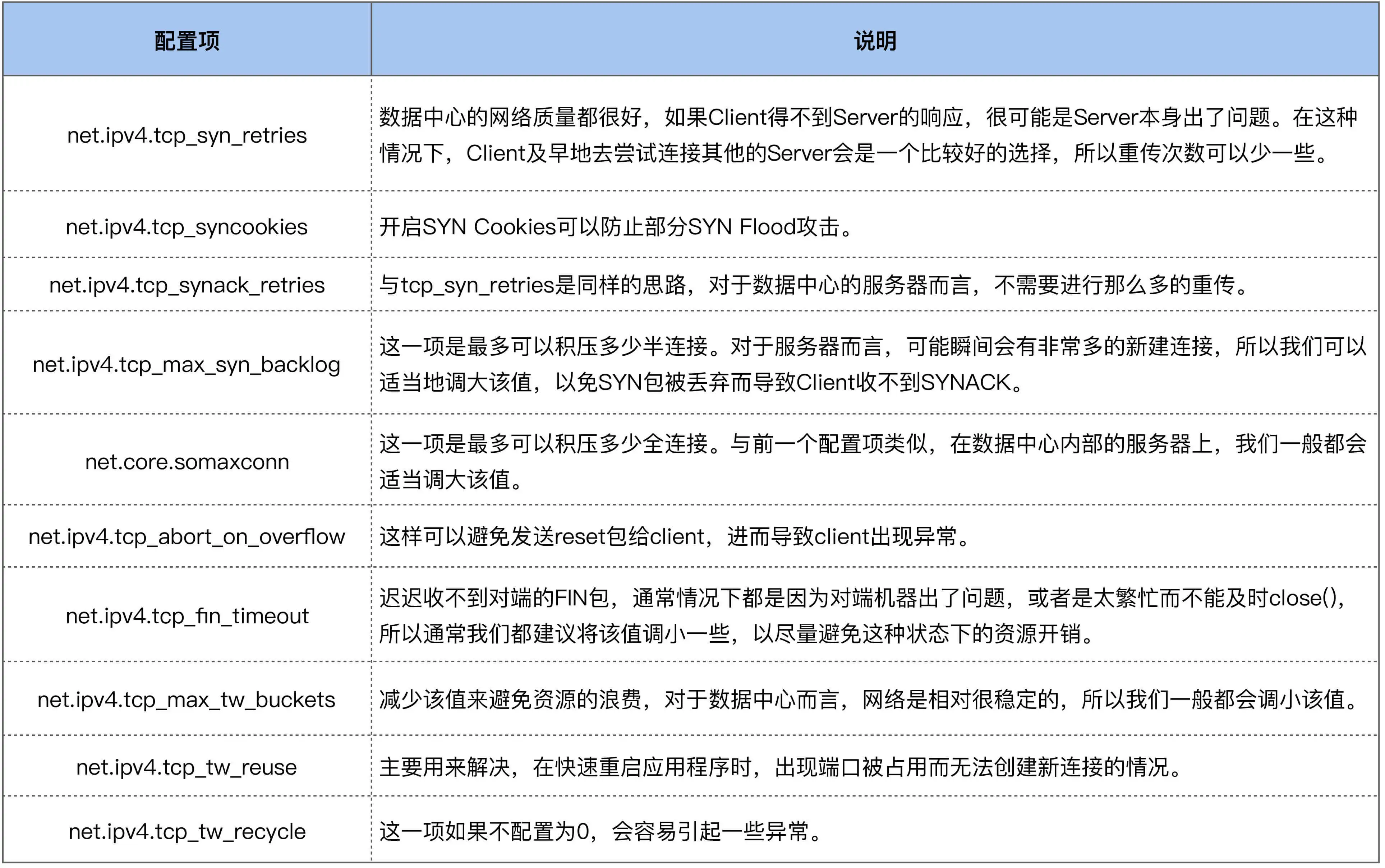
出处
4. netstat/ss简单监测实验
4.1. Recv-Q和Send-Q
1、服务端起一个简单http服务,python2 -m SimpleHTTPServer(python2,python3上用python -m http.server),默认8000端口
2、观察netstat和ss展示的各列信息
netstat:
1
2
3
4
5
6
[root@iZ2ze45jbqveelsasuub53Z ~]# netstat -atnp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN 1910/python
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1258/sshd
...
ss:
1
2
3
4
5
[root@iZ2ze45jbqveelsasuub53Z ~]# ss -atnp
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 5 0.0.0.0:8000 0.0.0.0:* users:(("python",pid=1910,fd=3))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1258,fd=3))
...
netstat和ss里展示的Recv-Q和Send-Q含义是不一样的,可以看到上述两者的值不同。
在netstat中:
Recv-Q- 对于 LISTEN状态 的socket,表示全连接队列大小
- 对于 非LISTEN状态 的socket,表示已收到但未被应用程序读取的字节数,表示在接收缓冲区中等待处理的数据量。
Send-Q- 已发送但未收到确认的字节数
- 疑问:针对监听和非监听端口,netstat中的
Recv-Q和Send-Q的含义是否有区别?待定,后续分析netstat的源码(TODO)- 已更新上述描述,参考分析netstat中的Send-Q和Recv-Q
在ss中:
- 对于 LISTEN 状态的 socket
Recv-Q:当前全连接队列的大小,即已完成三次握手等待应用程序 accept() 的 TCP 链接Send-Q:全连接队列的最大长度,即全连接队列的大小
- 对于非 LISTEN 状态的 socket
Recv-Q:已收到但未被应用程序读取的字节数,表示在接收缓冲区中等待处理的数据量。Send-Q:已发送但未收到确认的字节数
上面SimpleHTTPServer服务的全连接队列最大长度只有5,可以查看其源码:/usr/lib64/python2.7/SimpleHTTPServer.py。一步步跟踪代码可以看到其默认队列长度就是5,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# /usr/lib64/python2.7/SocketServer.py
class TCPServer(BaseServer):
...
request_queue_size = 5
...
def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True):
"""Constructor. May be extended, do not override."""
BaseServer.__init__(self, server_address, RequestHandlerClass)
self.socket = socket.socket(self.address_family,
self.socket_type)
if bind_and_activate:
self.server_bind()
self.server_activate()
...
def server_activate(self):
# 此处listen指定的backlog全连接最大长度默认就是5
self.socket.listen(self.request_queue_size)
...
4.2. listen队列溢出
另外:netstat -s里可以查看listen队列溢出的情况
1、客户端上安装ab压测工具:yum install httpd-tools
2、向上述http服务进行并发请求,请求前开启两端的抓包
ab -n 100 -c 10 http://172.23.133.138:8000/
-n 100 表示总共发送100个请求。
-c 10 表示并发数为10,也就是同时尝试建立1000个连接
客户端:tcpdump -i eth0 port 8000 -w 8000_client139.cap -v
服务端:tcpdump -i eth0 port 8000 -w 8000_server138.cap -v
3、服务端查看统计情况netstat -s|grep -i listen
1
2
3
[root@iZ2ze45jbqveelsasuub53Z ~]# netstat -s|grep -i listen
6 times the listen queue of a socket overflowed
6 SYNs to LISTEN sockets dropped
times the listen queue of a socket overflowed这是全连接队列溢出(listen queue)SYNs to LISTEN sockets dropped这是半连接队列溢出- 此处说半连接drop(SYN drop)其实不准确,SYN drop不只是半连接满才累加。
- 具体分析见:TCP半连接全连接(二) – 半连接队列代码逻辑。
4、查看抓包情况
只能看到几个PSH, ACK的重传,请求应答最后还是正常的。ab工具应该有自己的重试机制。稍后参考原博客的方式构造场景。
5、备份修改python中SocketServer.py里的默认为2048,可看到Send-Q变成了2048
/usr/lib64/python2.7/SocketServer.py
1
2
3
4
[root@iZ2ze76owg090hoj8a5bpqZ ~]# ss -anlt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:*
LISTEN 0 2048 *:8000
而后继续进行一次ab测试,ab -n 100 -c 10 http://172.23.133.138:8000/,查看统计信息后,这次没有再出现队列溢出的情况了。
- 本次ECS上的对应参数:
1
2
3
4
5
6
7
8
9
10
[root@iZ2zejee6e4h8ysmmjwj1nZ ~]# sysctl -a|grep -E "syn_backlog|somaxconn|syn_retries|synack_retries|syncookies|abort_on_overflow|net.ipv4.tcp_fin_timeout|tw_buckets|tw_reuse|tw_recycle"
net.core.somaxconn = 4096
net.ipv4.tcp_abort_on_overflow = 0
net.ipv4.tcp_fin_timeout = 60
net.ipv4.tcp_max_syn_backlog = 128
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syn_retries = 6
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 2
之前CentOS7.7(3.10内核)上的默认参数也贴到这里:
1
2
3
4
5
6
7
[root@iZ2ze76owg090hoj8a5bpqZ ~]# sysctl -a|grep -E "syn_backlog|somaxconn|syn_retries|synack_retries|syncookies|abort_on_overflow"
net.core.somaxconn = 128
net.ipv4.tcp_abort_on_overflow = 0
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_syn_retries = 6
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syncookies = 1
所以上述两个溢出打印,是由于服务端处理不过来导致全连接队列满,不去取出半连接队列进而导致半连接队列满?这个待定(TODO)
4.3. ss中关于监听和非监听端口的区别说明
1、ss和netstat数据获取的方式不同,ss用的是tcp_diag模块通过网络获取,而netstat是直接解析/proc/net/tcp文件,ltrace可以大致看出其过程差别。
1
2
3
4
5
6
7
8
9
10
11
[root@iZ2ze76owg090hoj8a5bpqZ ~]# ltrace netstat -ntl
__libc_start_main(0x55bffcd51aa0, 2, 0x7ffed430ef98, 0x55bffcd64340 <unfinished ...>
...
__printf_chk(1, 0x55bffcd65480, 1, 1Active Internet connections (only servers)
) = 80
putchar(10, 0x7fc9aca9aa00, 80, 0Proto Recv-Q Send-Q Local Address Foreign Address State
) = 10
fopen("/proc/net/tcp", "r") = 0x55bffe70b390
getpagesize() = 4096
malloc(4096) = 0x55bffe70b5d0
...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
[root@iZ2ze76owg090hoj8a5bpqZ ~]# ltrace ss -ntl
__libc_start_main(0x4024d0, 2, 0x7fff6f428268, 0x412d40 <unfinished ...>
...
__printf_chk(1, 0x4138fe, 49, 0x4138f0State Recv-Q Send-Q Local Address:Port Peer Address:Port
) = 138
fflush(0x7fcdb4e80400) = 0
getenv("TCPDIAG_FILE") = nil
getenv("PROC_NET_TCP") = nil
getenv("PROC_ROOT") = nil
socket(16, 524291, 4) = 3
setsockopt(3, 1, 7, 0x7fff6f427e20) = 0
setsockopt(3, 1, 8, 0x61b37c) = 0
setsockopt(3, 270, 11, 0x7fff6f427e24) = -1
bind(3, 0x7fff6f427ef4, 12, -384) = 0
getsockname(3, 0x7fff6f427ef4, 0x7fff6f427e1c, -1) = 0
time(nil) = 1716102416
sendmsg(3, 0x7fff6f427f70, 0, 0) = 72
recvmsg(3, 0x7fff6f427d80, 34, 0) = 192
malloc(192) = 0x1329010
recvmsg(3, 0x7fff6f427d80, 0, 14) = 192
memset(0x7fff6f427b40, '\0', 152) = 0x7fff6f427b40
2、ss命令位于iproute这个库,若要具体分析过程需要找这个库的源码。
1
2
3
4
5
6
[root@iZ2ze45jbqveelsasuub53Z ~]# rpm -qf /usr/sbin/ss
iproute-5.18.0-1.1.0.1.al8.x86_64
# netstat位于net-tools中
[root@iZ2ze45jbqveelsasuub53Z ~]# rpm -qf /usr/bin/netstat
net-tools-2.0-0.52.20160912git.1.al8.x86_64
3、tcp_diag中,获取信息的代码位置:tcp_diag_get_info(linux-5.10.10/net/ipv4/tcp_diag.c)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// linux-5.10.10/net/ipv4/tcp_diag.c
static void tcp_diag_get_info(struct sock *sk, struct inet_diag_msg *r,
void *_info)
{
struct tcp_info *info = _info;
if (inet_sk_state_load(sk) == TCP_LISTEN) {
// socket 状态是 LISTEN 时
// 当前全连接队列个数 (RECV-Q会用这个)
r->idiag_rqueue = READ_ONCE(sk->sk_ack_backlog);
// 当前全连接队列最大个数 (SEND-Q会用这个)
r->idiag_wqueue = READ_ONCE(sk->sk_max_ack_backlog);
} else if (sk->sk_type == SOCK_STREAM) {
// SOCK_STREAM(典型如TCP) socket 状态是其他状态时,
const struct tcp_sock *tp = tcp_sk(sk);
// 已收到但未被应用程序读取处理的字节数
r->idiag_rqueue = max_t(int, READ_ONCE(tp->rcv_nxt) -
READ_ONCE(tp->copied_seq), 0);
// 已发送但未收到确认的字节数
r->idiag_wqueue = READ_ONCE(tp->write_seq) - tp->snd_una;
}
if (info)
tcp_get_info(sk, info);
}
5. 全连接队列溢出实验
TCP 全连接队列的最大长度由 min(somaxconn, backlog) 控制,对应内核代码见下面的listen流程小节。
两个ip分别为:172.23.133.140、172.23.133.141,下述把140作为服务端,141作为客户端
当前环境中:net.core.somaxconn = 4096
5.1. 构造方法及代码
通过让服务端应用只负责listen对应端口而不执行accept() TCP 连接,使 TCP 全连接队列溢出。
- 服务端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
#include <iostream>
#include <sys/socket.h>
#include <netinet/in.h>
#include <unistd.h>
#include <string.h>
const int PORT = 8080;
const int BACKLOG = 5;
int main() {
int server_fd, new_socket;
struct sockaddr_in address;
int addrlen = sizeof(address);
// 创建socket
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == 0) {
perror("socket failed");
exit(EXIT_FAILURE);
}
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
// 绑定
if (bind(server_fd, (struct sockaddr *)&address, sizeof(address)) < 0) {
perror("bind failed");
exit(EXIT_FAILURE);
}
// 监听
if (listen(server_fd, BACKLOG) < 0) {
perror("listen");
exit(EXIT_FAILURE);
}
std::cout << "Server listening on port " << PORT << std::endl;
// 注意:服务器不会接受连接,而是保持监听状态
// 您可以添加代码来让服务器持续运行,例如:
while (true) {
sleep(1); // 模拟服务器持续运行
}
return 0;
}
编译:g++ server.cpp -o server
- 客户端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
#include <iostream>
#include <thread>
#include <vector>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <string.h>
char SERVER_IP[64] = "";
const int PORT = 8080;
void send_message(int num_requests) {
for (int i = 0; i < num_requests; ++i) {
int sock = 0;
struct sockaddr_in serv_addr;
// 创建socket
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
std::cerr << "Socket creation error" << std::endl;
return;
}
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
// 将服务器的IP地址转换为网络字节序
if (inet_pton(AF_INET, SERVER_IP, &serv_addr.sin_addr) <= 0) {
std::cerr << "Invalid address/ Address not supported" << std::endl;
close(sock);
return;
}
// 连接到服务器
if (connect(sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) < 0) {
std::cerr << "Connection Failed" << std::endl;
close(sock);
return;
}
std::string message = "helloworld";
// 发送消息
if (send(sock, message.c_str(), message.length(), 0) < 0) {
std::cerr << "Send failed" << std::endl;
} else {
std::cout << "Message sent: " << message << std::endl;
}
close(sock);
}
}
int main(int argc, char *argv[]) {
if (argc != 3) {
std::cerr << "Usage: " << argv[0] << " <server_ip> <num_requests>" << std::endl;
return 1;
}
strncpy(SERVER_IP, argv[1], sizeof(SERVER_IP));
int num_requests = std::stoi(argv[2]);
if (num_requests <= 0) {
std::cerr << "Invalid number of requests" << std::endl;
return 1;
}
std::vector<std::thread> threads;
// 假设我们想要限制并发线程数,这里为了简单起见,我们直接创建num_requests个线程
for (int i = 0; i < num_requests; ++i) {
threads.emplace_back(send_message, 1); // 每个线程只发送一个请求
}
// 等待所有线程完成
for (auto& t : threads) {
t.join();
}
return 0;
}
编译:g++ client.cpp -o client -std=c++11 -lpthread
上述代码和编译脚本也可从 github处 获取。
5.2. 观察过程
5.2.1. 程序运行并抓包
1、服务端代码编译后运行,./server
1
2
3
4
5
6
7
[root@iZ2ze45jbqveelsasuub53Z ~]# netstat -anpt|grep 8080
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 18330/./server
[root@iZ2ze45jbqveelsasuub53Z ~]# ss -anpt|grep 8080
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 5 0.0.0.0:8080 0.0.0.0:* users:(("server",pid=18330,fd=3))
2、开启两端抓包
服务端:tcpdump -i eth0 port 8080 -w 8080_server140.cap -v
客户端:tcpdump -i eth0 port 8080 -w 8080_client141.cap -v
3、客户端并发10个请求,./client 172.23.133.140 10,结束后查看客户端和服务端信息
请求结束后,在客户端grep查看8080,没有任何连接了。
服务端信息如下:
- 可看到当前全连接队列中当前还有6个连接,全连接最大值为5(实际允许5+1),且有6个
CLOSE_WAIT状态的连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 客户端发请求前,服务端的统计信息,没有溢出信息
[root@iZ2ze45jbqveelsasuub53Z ~]# netstat -s|grep -i list
[root@iZ2ze45jbqveelsasuub53Z ~]#
# 客户端请求结束后,服务端netstat
[root@iZ2zejee6e4h8ysmmjwj1nZ ~]# netstat -anp|grep 8080
tcp 6 0 0.0.0.0:8080 0.0.0.0:* LISTEN 2774/./server
tcp 11 0 172.23.133.140:8080 172.23.133.141:41718 CLOSE_WAIT -
tcp 11 0 172.23.133.140:8080 172.23.133.141:41680 CLOSE_WAIT -
tcp 11 0 172.23.133.140:8080 172.23.133.141:41706 CLOSE_WAIT -
tcp 11 0 172.23.133.140:8080 172.23.133.141:41702 CLOSE_WAIT -
tcp 11 0 172.23.133.140:8080 172.23.133.141:41780 CLOSE_WAIT -
tcp 11 0 172.23.133.140:8080 172.23.133.141:41674 CLOSE_WAIT -
# 客户端请求结束后,服务端ss
[root@iZ2zejee6e4h8ysmmjwj1nZ ~]# ss -anp|grep 8080
tcp LISTEN 6 5 0.0.0.0:8080 0.0.0.0:* users:(("server",pid=2774,fd=3))
tcp CLOSE-WAIT 11 0 172.23.133.140:8080 172.23.133.141:41718
tcp CLOSE-WAIT 11 0 172.23.133.140:8080 172.23.133.141:41680
tcp CLOSE-WAIT 11 0 172.23.133.140:8080 172.23.133.141:41706
tcp CLOSE-WAIT 11 0 172.23.133.140:8080 172.23.133.141:41702
tcp CLOSE-WAIT 11 0 172.23.133.140:8080 172.23.133.141:41780
tcp CLOSE-WAIT 11 0 172.23.133.140:8080 172.23.133.141:41674
# 客户端请求结束后,服务端统计信息
# 多了17个drop
[root@iZ2zejee6e4h8ysmmjwj1nZ ~]# netstat -s|grep -i listen
17 times the listen queue of a socket overflowed
17 SYNs to LISTEN sockets dropped
5.2.2. 抓包分析
先看客户端抓包结果,能观察到下面几种情况。
- 1、情况1:成功建立连接,客户端发送FIN关闭成功
由于只有10次请求,都查看一下,其中tcp.stream 0/1/2/4/5/9均是这种情况。(和上述6个CLOSE_WAIT对应)
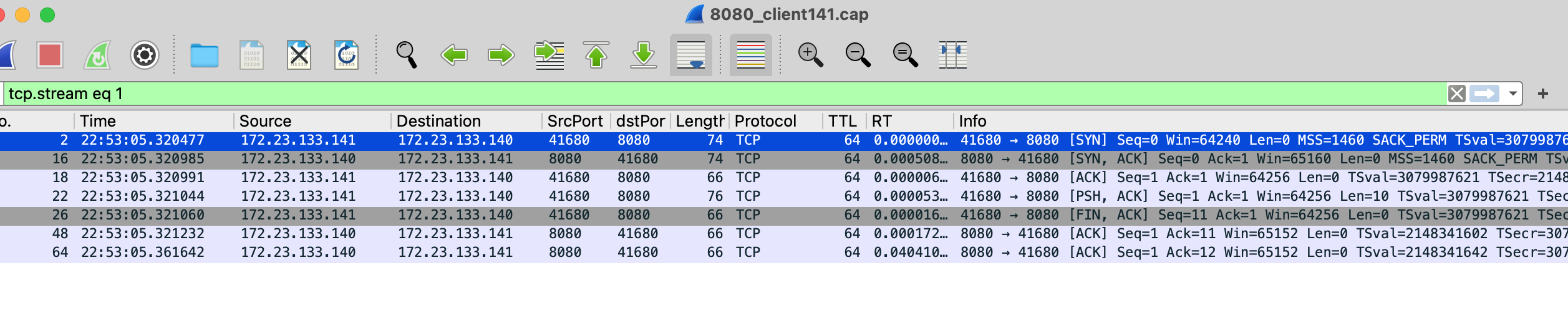
有时FIN可能隐藏在某个PSH包里,通过Flow Graph查看具体发包过程:
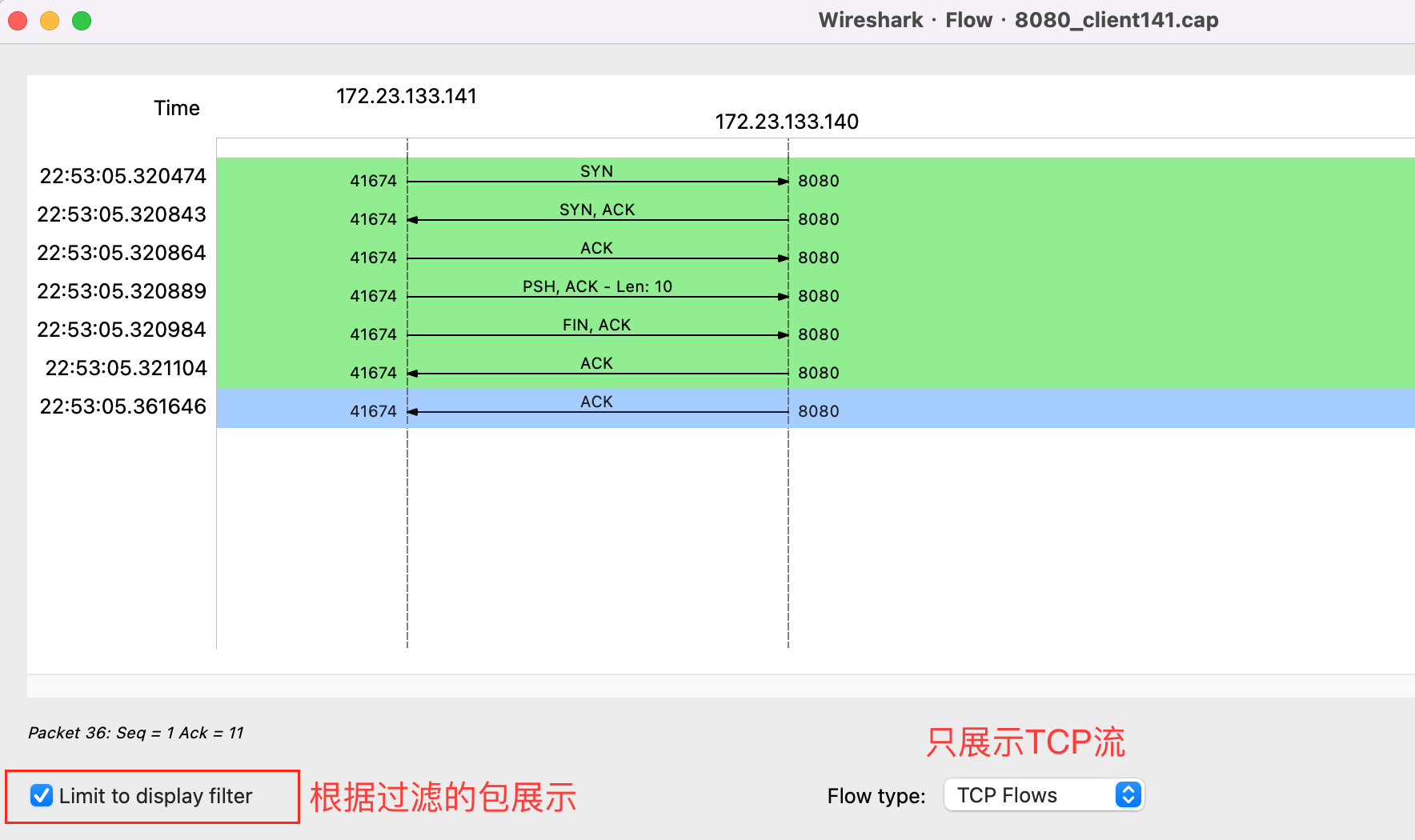
如上所示,客户端正常发起三次握手,发送完数据后客户端进行close,主动发起FIN。但是由于服务端没有accept,所以全连接队列中并不会移除连接。
交互过程如下:
- 客户端发起SYN(SYN_SENT),服务端接收到SYN后(SYN_RECV)将连接存到
半连接队列,而后应答SYN+ACK 客户端收到后(ESTABLISHED),应答ACK,服务端收到ACK后(ESTABLISHED),把连接从基于case2分析更正:半连接队列取出,放入全连接队列
客户端收到后(ESTABLISHED),应答ACK,服务端收到ACK后,把连接从半连接队列取出,放入全连接队列,然后才ESTABLISHED完成完整三次握手- 服务端没有
accept(),全连接队列中并不会移除连接 - 客户端发送数据;发送完成后,
close()发起关闭,发送FIN - 服务端收到FIN后应答ACK
- 服务端没有
accept()处理请求,所以也不会close()这次连接,服务端连接一直保持CLOSE_WAIT状态 - 客户端收到ACK后,按开头的tcp流程应该处于FIN_WAIT2,并等待该状态超时(也为2MSL),不过60s内netstat看客户端已经没8080相关的连接了(原因待定,TODO)
- 2、情况2:成功建立连接,客户端重传FIN+PSH+ACK,最后收到服务端的RST
由于只有10次请求,都查看一下,其中tcp.stream 3是这种情况。
客户端抓包:
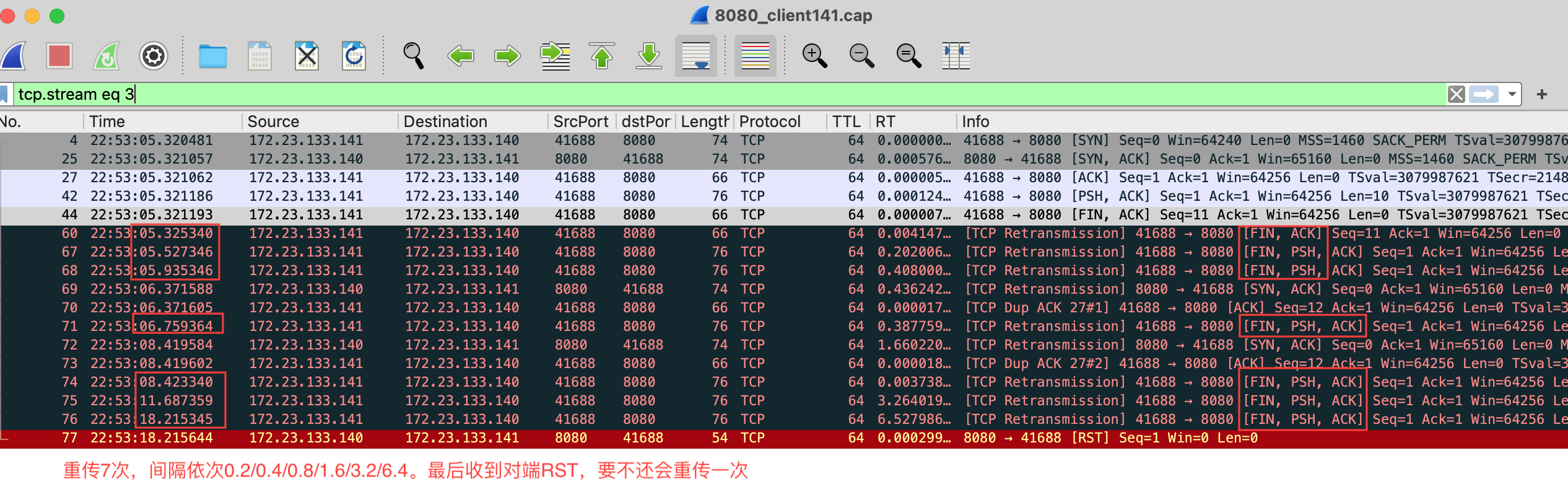
如上所示,客户端发完数据后,发起FIN关闭,但是服务端没应答ACK,于是重传FIN。
FIN重传次数由tcp_orphan_retries控制,可以看到环境里为0(默认值),默认时会重传8次。
抓包中可看到重传间隔每次翻倍(0.2/0.4/0.8/1.6/3.2/6.4),只重传了7次,最后一次没重传是由于重传间隔(12.8s)前,收到服务端的RST,于是客户端关闭连接。
1
2
[root@iZ2zejee6e4h8ysmmjwj1nZ ~]# sysctl -a|grep tcp_orphan_retries
net.ipv4.tcp_orphan_retries = 0
抓包中另外两种异常包:
- 服务端(133.140)重传两次了
SYN+ACK包 - 客户端(133.141)两次提示重复接收了
ACK
TCP协议的Seq显示修改成原始值(Protocol->TCP->取消相对Seq),能更明确看出来这些包的关系:
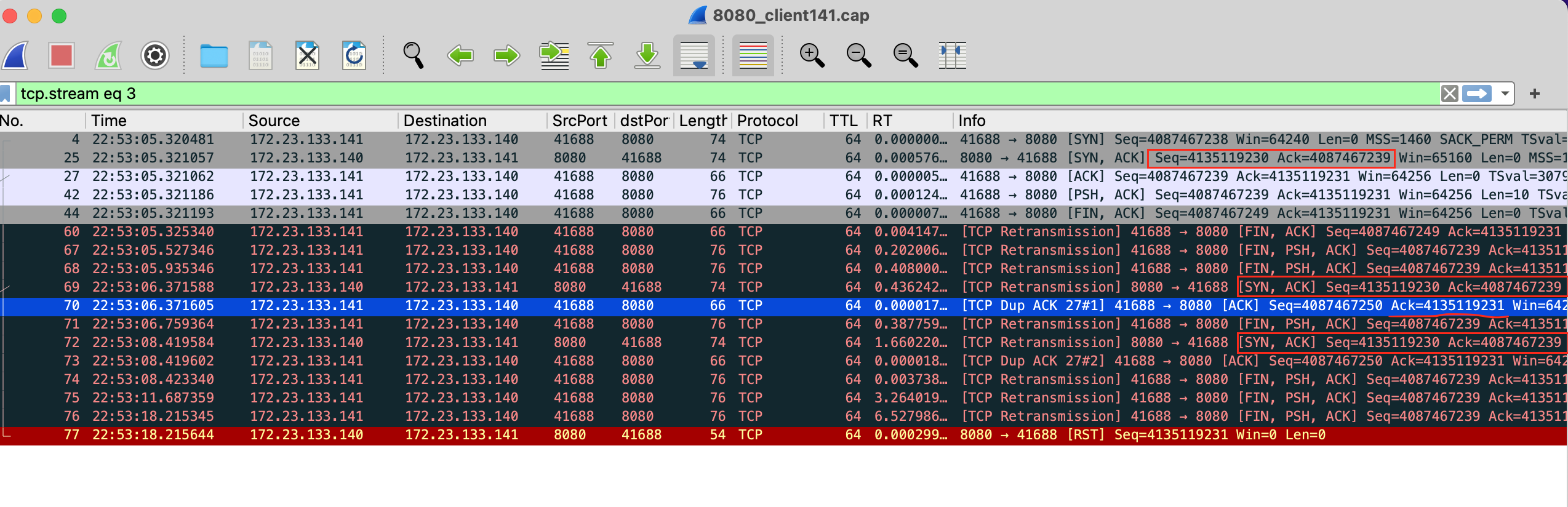
通过Seq和Ack值可以看出,此处重传的包是三次握手时服务端应答的SYN+ACK,重复接收ACK也是针对这个重传包的提示,重传两次是由于net.ipv4.tcp_synack_retries = 2
再看一下服务端抓包中对应的这个tcp stream处理(根据tcp.seq eq 4135119230找一下然后follow流):
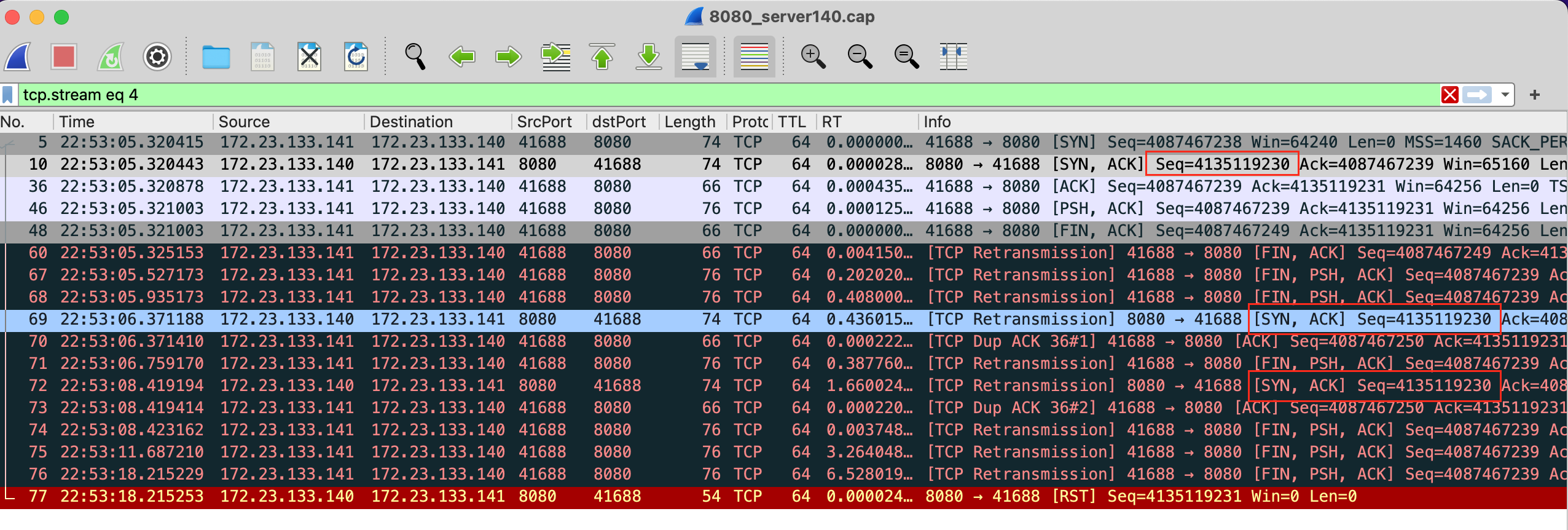
抓到的包是一样的,一样的三次握手过程,也有重传SYN+ACK。此处疑问:
- 内核drop掉的包,是否会被tcpdump抓到?(待定,TODO)
- 全连接队列溢出导致内核drop掉的包,是否会被tcpdump抓到?
(后续更新:得分是接收过程还是发送过程。接收过程先过tcpdump挂接的协议,是可以抓到的;而发送过程的丢包由于先过netfilter再经过tcpdump挂接的协议,抓取不到。具体可见此篇博客笔记:TCP发送接收过程 – 学习netfilter和iptables)
查资料上述两种情况若是drop了包,应该就抓不到包,所以包没有被drop掉。问题是服务端既然收到了客户端对于其SYN+ACK的ACK确认包,就应该是握手成功两端都ESTABLISHED了,为什么还要重传SYN+ACK呢?
再理解了一下参考文章,所以还是我理解后画的图有问题,应该明确客户端回应ACK后服务端处理的先后顺序:此处应该为收到ACK->从半连接取连接放到全连接->状态ESTABLISHED,完成三次握手。如果是这样就理顺了。 (待定:跟踪源码确定这块的逻辑 TODO)
所以交互过程如下:
- 客户端发起SYN(SYN_SENT),服务端接收到SYN后(SYN_RECV)将连接存到
半连接队列,而后应答SYN+ACK - 客户端收到后(ESTABLISHED),应答ACK,客户端侧当作握手成功;服务端收到ACK后,本应把连接从
半连接队列取出,放入全连接队列,此处应该由于全连接队列满导致服务端未完成握手成功。 - 于是客户端发送数据,发送完成后便发送FIN结束。而实际上服务端均未处理,于是客户端进行重传(都计入drop? TODO)。
重传报文中Seq并未加10,说明PSH那个10长度的包未成功,展开看重传包中包含Len=10的数据也可以看出
下面的FIN+PSH+ACK是由于发送数据及发送FIN都未处理,所以一起重传了,且两者ACK一样的。
Info信息:[TCP Retransmission] 41688 → 8080 [FIN, PSH, ACK] Seq=4087467239 Ack=4135119231 Win=64256 Len=10 TSval=3079987828 TSecr=2148341601 - 对于服务端侧,由于一直没握手成功变成ESTABLISHED,重传
SYN+ACK尝试继续握手。而客户端侧认为TCP连接已建立完成,收到的SYN+ACK当作重复包并不继续按握手处理(计入drop? TODO) - 于是服务端重传2次
SYN+ACK(net.ipv4.tcp_synack_retries = 2),均未继续握手 - 最后,服务端发送
RST,客户端收到后关闭客户端侧的连接
至此,第2种情况流程分析结束。这个情况并不会产生服务端的CLOSE_WAIT状态,会发生包drop
(待定,ebpf跟踪下包drop TODO,可参考:一张图感受真实的 TCP 状态转移)
- 3、情况3:收到服务端的RST
由于只有10次请求,都查看一下,其中tcp.stream 6/7/8是这种情况。
查看抓包,客户端和服务端抓到的包也一样:
客户端抓包:

服务端抓包:
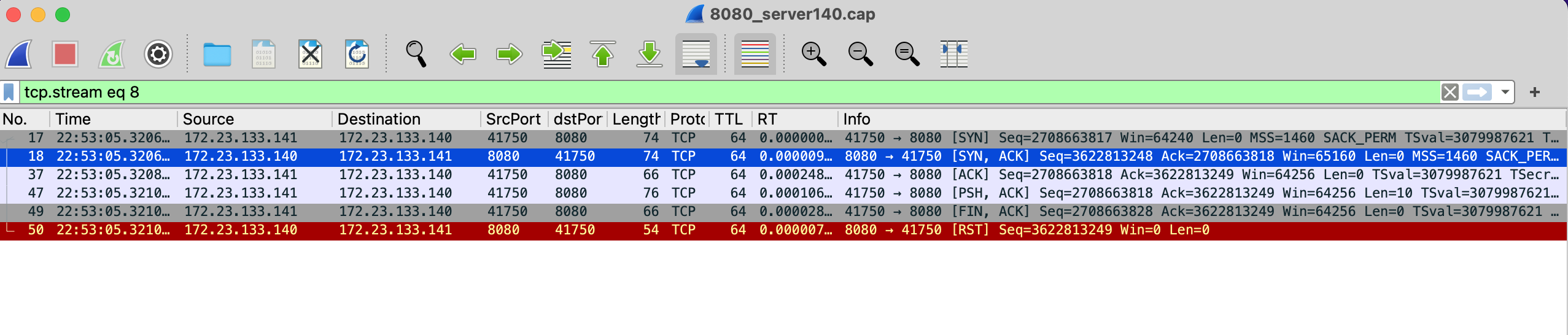
可看到客户端三次握手后,发送数据,发送完成后发FIN关闭连接。不过服务端并没有任何确认包,并且在1ms不到的时间,就送了RST让客户端关闭连接,没有等到客户端重传。
作为对比:case2中在间隔4ms之后开始重传FIN+ACK并重传多次。
所以交互过程类似case2:
- 服务端发送
SYN+ACK后没有成功操作全连接队列变成ESTABLISHED - 客户端发送的数据,服务端当然也没有处理(服务端没完成握手,没初始化好连接)
- 服务端发送
RST的触发条件,需要单独分析(和参考链接中略有不同,不过看来也是判断半连接队列满导致的),TODO
6. 源码中各阶段简要流程
stream类型协议相关的op接口,截取部分如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// linux-5.10.10/net/ipv4/af_inet.c
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
...
.bind = inet_bind,
.connect = inet_stream_connect,
.accept = inet_accept,
.poll = tcp_poll,
.ioctl = inet_ioctl,
.listen = inet_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
...
}
6.1. listen流程
结合内核源码跟踪流程,具体见:笔记记录
代码位置:__sys_listen,linux-5.10.10/net/socket.c (Linux的系统调用在内核中的入口函数都是 sys_xxx ,但是如果我们拿着内核源码去搜索的话,就会发现根本找不到 sys_xxx 的函数定义,这是因为Linux的系统调用对应的函数全部都是由 SYSCALL_DEFINE 相关的宏来定义的。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// linux-5.10.10/net/socket.c(不同内核版本可能有部分差异,不影响流程)
int __sys_listen(int fd, int backlog)
{
// socket 定义在 include\linux\net.h
struct socket *sock;
int err, fput_needed;
int somaxconn;
// 根据fd从fdtable里找到对应struct fd(file.h中定义),并返回其中的socket相关数据成员(file结构的void* private_data成员),此处即struct socket结构
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
// 获取sysctl配置的 net.core.somaxconn 参数
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
// 取min(传入的backlog, 系统net.core.somaxconn)
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
// ops里是一系列socket操作的函数指针(如bind/accept),inet_init(void)网络协议初始化时会设置
// 其中,tcp协议的结构是 inet_stream_ops,里面的listen函数指针赋值为:inet_listen
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
// linux-5.10.10/net/ipv4/af_inet.c
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
lock_sock(sk);
...
// __sys_listen(linux-5.10.10/net/socket.c)调用时,传进来的的backlog值是min(调__sys_listen传入的backlog, 系统net.core.somaxconn)
// 此处设置到struct socket中struct sock相应成员中: sk_max_ack_backlog
WRITE_ONCE(sk->sk_max_ack_backlog, backlog);
...
}
6.2. connect 流程
按__sys_xxx方式搜索系统调用,connect调用如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// linux-5.10.10/net/socket.c
int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen)
{
int ret = -EBADF;
struct fd f;
f = fdget(fd);
if (f.file) {
struct sockaddr_storage address;
// 用户态结构:sockaddr,拷贝到内核空间结构:sockaddr_storage
ret = move_addr_to_kernel(uservaddr, addrlen, &address);
if (!ret)
// 里面调用对应协议注册的 connect op操作,对于tcp是 inet_stream_connect
ret = __sys_connect_file(f.file, &address, addrlen, 0);
fdput(f);
}
return ret;
}
1
2
3
4
5
6
7
8
9
10
11
// linux-5.10.10/net/ipv4/af_inet.c
int inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags)
{
int err;
lock_sock(sock->sk);
err = __inet_stream_connect(sock, uaddr, addr_len, flags, 0);
release_sock(sock->sk);
return err;
}
跟踪__inet_stream_connect及socket创建等过程,可知tcp协议实际会调用 tcp_v4_connect (具体跟踪过程可参考:Linux内核学习笔记)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// linux-5.10.10/net/ipv4/tcp_ipv4.c
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
...
// 先设置SYN_SENT
tcp_set_state(sk, TCP_SYN_SENT);
err = inet_hash_connect(tcp_death_row, sk);
if (err)
goto failure;
...
// 再发起实际数据发送
// Build a SYN and send it off
err = tcp_connect(sk);
...
}
所以开头中的流程图中,三次握手时应该调整成先设置SYN_SENT再发送SYN。
6.3. 接收流程
在网络协议inet_init初始化时,(inet_add_protocol(&tcp_protocol, IPPROTO_TCP)注册了TCP协议的接收处理api:tcp_v4_rcv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// linux-5.10.10/net/ipv4/tcp_ipv4.c
int tcp_v4_rcv(struct sk_buff *skb)
{
...
// TCP协议头
// sk_buff结构里的data是`unsigned char*` 类型
th = (const struct tcphdr *)skb->data;
// IP协议头
iph = ip_hdr(skb);
...
process:
// TIME_WAIT状态处理
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;
if (sk->sk_state == TCP_NEW_SYN_RECV) {
...
}
...
}
关于上面的TCP协议头和IP协议头,可在wireshark中对照查看(设置->Appearance->Layout->Pane3选Packet Diagram):
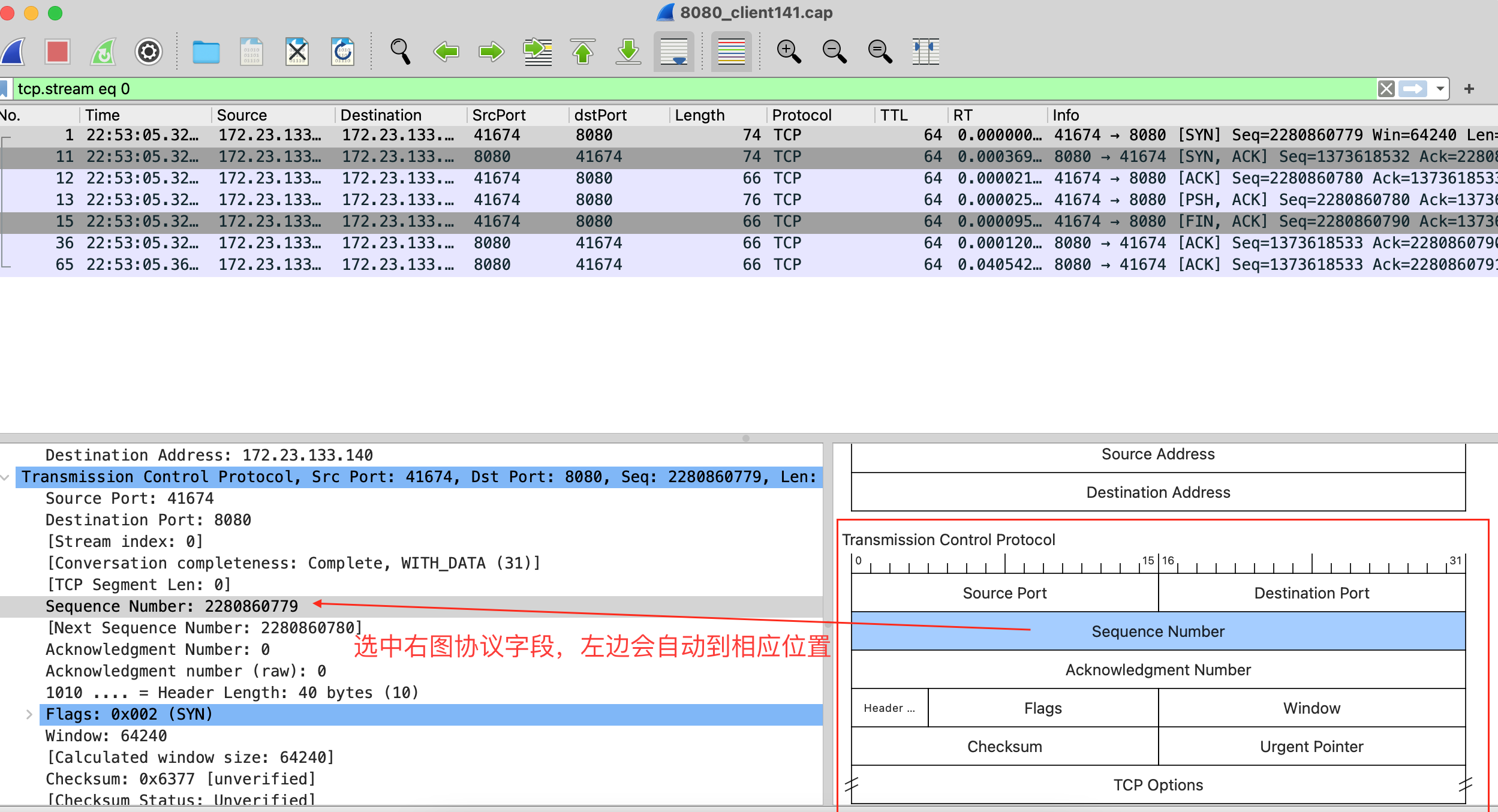
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// linux-5.10.10/include/uapi/linux/tcp.h
// TCP协议头信息
struct tcphdr {
__be16 source;
__be16 dest;
__be32 seq;
__be32 ack_seq;
// 大小端字节序,flag位置不同(网络字节序为大端)
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4,
...
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4,
...
#endif
__be16 window;
__sum16 check;
__be16 urg_ptr;
};
可以看到里面已经是对各种状态的处理,那么SYN_RECV状态是哪里设置的?
查资料后,流程如下:
在服务器接收了SYN之后,会调用
tcp_conn_request来处理连接请求,其中调用inet_reqsk_alloc来创建请求控制块,可见请求控制块的ireq_state被初始化为TCP_NEW_SYN_RECV;
tcp_v4_rcv函数中会对TCP_NEW_SYN_RECV进行处理,如果连接检查成功,则需要新建控制块来处理连接,这个新建控制块的状态将会使用TCP_SYN_RECV状态;
IPv4携带的TCP报文最终会进入到
tcp_v4_do_rcv函数
流程比较复杂,本文先有个概念,后续再具体跟踪梳理流程。
7. 小结
1、实验演示了ss、netstat结果中Recv-Q、Send-Q的含义
2、介绍了TCP全连接队列、半连接队列和简要处理过程,并实验分析了全连接溢出的情况
3、遗留了几个待定TODO项,后续单独再分析
- 半连接队列溢出情况分析,服务端接收具体处理逻辑
- 内核drop包的时机,以及跟抓包的关系。哪些情况可能会抓不到drop的包?
- systemtap/ebpf跟踪TCP状态变化,跟踪上述drop事件
- 上述全连接实验case1中,2MSL内没观察到客户端连接
FIN_WAIT2状态,为什么?