TCP半连接全连接(二) -- 半连接队列代码逻辑
半连接队列相关过程分析及实验,并用工具跟踪。本文先分析半连接相关代码逻辑。
1. 背景
在“TCP半连接全连接(一) – 全连接队列相关过程”这篇文章中,进行了全连接队列溢出的实验,并且遗留了几个问题。
本博客跟踪分析半连接队列相关过程,并探究上述文章中的遗留问题。
- 半连接队列溢出情况分析,服务端接收具体处理逻辑
- 内核drop包的时机,以及跟抓包的关系。哪些情况可能会抓不到drop的包?
- systemtap/ebpf跟踪TCP状态变化,跟踪上述drop事件
- 上述全连接实验case1中,2MSL内没观察到客户端连接
FIN_WAIT2状态,为什么?
本文先分析梳理代码逻辑。
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 前置说明
主要基于这篇文章:”从一次线上问题说起,详解 TCP 半连接队列、全连接队列“,进行学习和扩展。
基于5.10内核代码跟踪流程,上下文均基于IPV4,暂不考虑IPV6
3. 先认识几种不同种类的sock结构
网络初始化、处理接口逻辑等过程中,涉及到几种不同的sock结构,前置了解再梳理代码流程会清晰很多。
下述几种sock类型,可以当作是父类-子类关系,C语言中结构体里的内存是连续的,将要继承的”父类”,放到结构体的第一位,然后就可以通过强制转换进行继承访问。
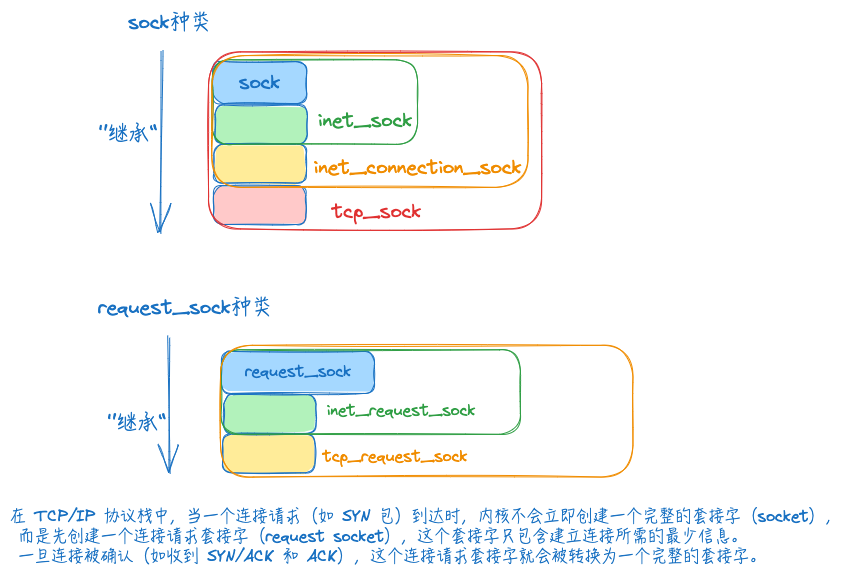
对于TCP的socket来说,sock对象实际上是一个tcp_sock。因此TCP中的sock对象随时可以强制类型转化为tcp_sock((struct tcp_sock *)sk形式)、inet_connection_sock、inet_sock来使用。
1、sock是最基础的结构,维护一些任何协议都有可能会用到的收发数据缓冲区。
1
2
3
4
5
6
7
8
9
10
11
12
13
// linux-5.10.176\include\net\sock.h
struct sock {
struct sock_common __sk_common;
socket_lock_t sk_lock;
atomic_t sk_drops;
int sk_rcvlowat;
struct sk_buff_head sk_error_queue;
struct sk_buff *sk_rx_skb_cache;
struct sk_buff_head sk_receive_queue;
...
struct proto *skc_prot;
...
}
socket创建流程中,涉及创建struct sock结构
__sys_socket -> sock_create -> __sock_create -> (net_proto_family结构)pf->create,实际调用到inet_create
其中会创建struct socket *sock,里面会进行struct sock和struct file的创建和映射操作
代码逻辑里面涉及的RCU概念,贴一下相关解释,辅助代码理解:
- RCU(Read-Copy Update)是一种用于实现高效读取和并发更新数据结构的同步机制。
- 在网络内核中,它允许多个线程或进程同时读取共享数据,而不需要获取锁,从而提高了并发性能。
- 读:允许多个线程或进程同时读取共享数据,而不需要获取锁
- 写:确保了在写操作进行时,读操作能够访问到一致的数据
- 应用场景:路由表、套接字数据结构、网络缓冲区
2、inet_sock,特指用了网络传输功能的sock,在sock的基础上还加入了TTL,端口,IP地址这些跟网络传输相关的字段信息。
相对的,有些sock不是用网络传输的,比如Unix domain socket,用于本机进程之间的通信,直接读写文件,不需要经过网络协议栈。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// linux-5.10.10/include/net/inet_sock.h
struct inet_sock {
/* sk and pinet6 has to be the first two members of inet_sock */
struct sock sk;
#if IS_ENABLED(CONFIG_IPV6)
struct ipv6_pinfo *pinet6;
#endif
/* Socket demultiplex comparisons on incoming packets. */
#define inet_daddr sk.__sk_common.skc_daddr
#define inet_rcv_saddr sk.__sk_common.skc_rcv_saddr
#define inet_dport sk.__sk_common.skc_dport
#define inet_num sk.__sk_common.skc_num
...
__u8 min_ttl;
__u8 mc_ttl;
...
};
3、inet_connection_sock 是指面向连接的sock,在inet_sock的基础上加入面向连接的协议里相关字段,比如accept队列,数据包分片大小,握手失败重试次数等。
从其成员变量的命名形式:icsk_xxx可看出其为inet connection sock的简写,按变量命名能知道其所属的sock层级
1
2
3
4
5
6
7
8
9
10
// linux-5.10.10/include/net/inet_connection_sock.h
struct inet_connection_sock {
/* inet_sock has to be the first member! */
struct inet_sock icsk_inet;
// 里面包含全连接队列、以及半连接队列长度等信息
struct request_sock_queue icsk_accept_queue;
struct inet_bind_bucket *icsk_bind_hash;
unsigned long icsk_timeout;
...
};
注意>=4.4的内核版本,相比之前的版本,struct request_sock_queue icsk_accept_queue;差异比较大。
4、tcp_sock就是tcp协议专用的sock结构,在inet_connection_sock基础上还加入了tcp特有的滑动窗口、拥塞避免等功能。
该结构中内容很多,近250多行(5.10.10内核)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// linux-5.10.10/include/linux/tcp.h
struct tcp_sock {
/* inet_connection_sock has to be the first member of tcp_sock */
struct inet_connection_sock inet_conn;
u16 tcp_header_len; /* Bytes of tcp header to send */
u16 gso_segs; /* Max number of segs per GSO packet */
...
u32 snd_wnd; /* The window we expect to receive */
u32 max_window; /* Maximal window ever seen from peer */
...
u32 snd_cwnd; /* Sending congestion window */
u32 snd_cwnd_cnt; /* Linear increase counter */
...
}
4. 不同内核版本半连接队列的特别说明
4.1. 新内核中是否还有半连接队列?
网上很多文章关于半连接都是基于3.x的内核,跟踪5.10内核过程中一直疑惑icsk_accept_queue算是全连接还是半连接队列。
自我感觉:对比3.10内核中request_sock_queue里既有全连接又有半连接,5.10内核里似乎没有单独的半连接,而是通过引用计数加1减1,共享同一个队列。
带着怀疑在技术讨论群搜半连接队列,碰巧历史记录里有人提到:4.4之后的内核改了syn_queue半连接队列逻辑,半连接队列成为一个概念没有了,统一保存到ehash table 中,维护半连接长度就放到icsk_accept_queue->qlen,并附了一篇陈硕大佬关于这块介绍的文章链接:Linux 4.4 之后 TCP 三路握手的新流程
Linux 网络协议栈中的 TCP 协议控制块(protocol control block)有三种:tcp_request_sock、tcp_sock、tcp_timewait_sock。
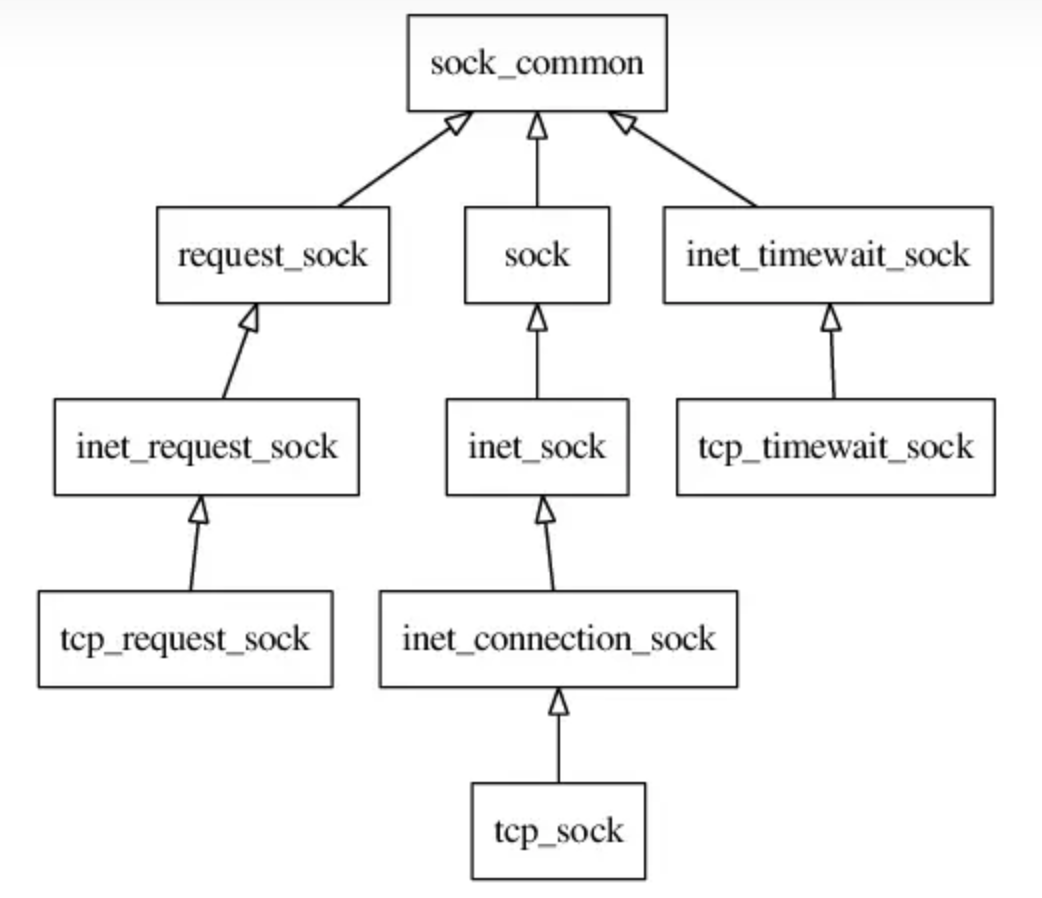
Linux 的 TCP 协议栈用全局的 3 个哈希表(位于 tcp_hashinfo 对象,定义于 net/ipv4/tcp_ipv4.c)来管理全部的 TCP 协议控制块。
- ehash负责established的 socket
- bhash 负责端口分配,b表示bind
- listening_hash 负责侦听(listening) socket
差异:
原来是把 tcp_request_sock 挂在 listen socket 下,收到 ACK 之后从 listening_hash 找到 listen socket 再进一步找到 tcp_request_sock;新的做法是直接把 tcp_request_sock 挂在 ehash 中,这样收到 ACK 之后可以直接找到 tcp_request_sock,减少了锁的争用(contention)。
另外参考 [内核源码] tcp 连接队列 这篇文章对连接队列的跟踪分析(自己当前的博客风格就是fork自这位博主)。这篇文章中也描述了TCP_NEW_SYN_RECV状态,以及内核中连接队列相关字段说明。对自己理解内核代码挺有帮助。
结合起来可以理解为半连接队列还是存在,只是不像之前明显。且sk_max_ack_backlog变成了全连接和半连接队列的共同最大长度,半连接队列也受该参数直接限制,并有一个变量icsk_accept_queue.qlen记录半连接队列长度
listen socket 的 struct sock 数据结构 inet_connection_sock。
- 全连接队列和半连接队列最大长度: inet_connection_sock.icsk_inet.sock.sk_max_ack_backlog
- 全连接队列: inet_connection_sock.icsk_accept_queue.rskq_accept_head
- 当前全连接队列长度: inet_connection_sock.icsk_inet.sock.sk_ack_backlog
- 半连接队列(哈希表): inet_hashinfo.inet_ehash_bucket
- 当前半连接队列长度: inet_connection_sock.icsk_accept_queue.qlen
4.2. (扩展)用户态是否可观察到TCP_NEW_SYN_RECV状态
三次握手第一次收到SYN后,服务端socket状态是TCP_NEW_SYN_RECV,netstat等用户态是否能观察到呢?
1、自己先用bcc tools中的tcpstates跟踪(特意用了bcc最新仓库),看只会看到SYN_RECV状态(在CentOS8.5环境,内核4.18.0-348.7.1)
1
2
3
4
5
6
7
8
9
10
# 192.168.1.150上:python -m http.server 起8000端口,并起tcpstates跟踪
# 192.168.1.3上`curl 192.168.1.150:8000`请求
[root@xdlinux ➜ /home/workspace/bcc/tools git:(v0.19.0) ✗ ]$ ./tcpstates.py
SKADDR C-PID C-COMM LADDR LPORT RADDR RPORT OLDSTATE -> NEWSTATE MS
ffff9f2032491d40 0 swapper/9 0.0.0.0 8000 0.0.0.0 0 LISTEN -> SYN_RECV 0.000
ffff9f2032491d40 0 swapper/9 192.168.1.150 8000 192.168.1.3 26365 SYN_RECV -> ESTABLISHED 0.009
ffff9f2032491d40 64594 python 192.168.1.150 8000 192.168.1.3 26365 ESTABLISHED -> FIN_WAIT1 0.869
ffff9f2032491d40 64594 python 192.168.1.150 8000 192.168.1.3 26365 FIN_WAIT1 -> FIN_WAIT1 0.018
ffff9f2032491d40 0 swapper/9 192.168.1.150 8000 192.168.1.3 26365 FIN_WAIT1 -> FIN_WAIT2 1.871
ffff9f2032491d40 0 swapper/9 192.168.1.150 8000 192.168.1.3 26365 FIN_WAIT2 -> CLOSE 0.003
2、重新看第一篇里面留的链接:一张图感受真实的 TCP 状态转移,里面用eBPF跟踪到TCP_NEW_SYN_RECV状态,里面的测试内核是 6.1.11版本。
内核中 TCP_SYN_RECV 已经不是原始 TCP 协议中 server 收到第一个 syn 包的状态了,取而代之的是 TCP_NEW_SYN_RECV,TCP_SYN_RECV 本身主要被用于支持 fastopen 特性了。
疑问(TODO):内核里收到三次握手第一个SYN时状态是TCP_NEW_SYN_RECV了?只是各观测工具展示时为了兼容性还是按老的方式?
以及参考这篇文章:TCP_NEW_SYN_RECV 里相关的描述
新增TCP_NEW_SYN_RECV状态是在这个patch:10feb428a5045d5eb18a5d755fbb8f0cc9645626
对应的commit为:commit_10feb428a5045d5eb18a5d755fbb8f0cc9645626
试下高版本内核的情况看。
1)系统:Alibaba Cloud Linux 3.2104 LTS 64位,内核:5.10.134-16.3.al8.x86_64
只观察到 SYN_RECV
1
2
3
4
5
6
7
8
9
10
11
# 本地curl 8000
[root@iZ2zefl9zh4dqju3vo1a4uZ tools]# ./tcpstates -L 8000
SKADDR C-PID C-COMM LADDR LPORT RADDR RPORT OLDSTATE -> NEWSTATE MS
ffff8af4c3a28000 3360 python 0.0.0.0 8000 0.0.0.0 0 CLOSE -> LISTEN 0.000
ffff8af4c3a2a900 3675 curl 0.0.0.0 8000 0.0.0.0 0 LISTEN -> SYN_RECV 0.000
ffff8af4c3a2a900 3675 curl 172.23.133.146 8000 172.23.133.146 51068 SYN_RECV -> ESTABLISHED 0.004
ffff8af4c3a2a900 3675 curl 172.23.133.146 8000 172.23.133.146 51068 FIN_WAIT1 -> FIN_WAIT2 0.020
ffff8af4c3a2a900 3675 curl 172.23.133.146 8000 172.23.133.146 51068 FIN_WAIT2 -> CLOSE 0.003
ffff8af4c3a2a900 3360 python 172.23.133.146 8000 172.23.133.146 51068 ESTABLISHED -> FIN_WAIT1 0.796
ffff8af4c3a2a900 3360 python 172.23.133.146 8000 172.23.133.146 51068 FIN_WAIT1 -> FIN_WAIT1 0.008
2)找更高版本内核,找到个6.x的。系统:debian_12_2_x64,内核:6.1.0-13-amd64
参考bcc官网apt-get install bcc方式安装,版本为0.16.17-3.4
另外安装apt-get install clang llvm、apt-get install python3-bpfcc
手动上传个bcc包,最后都执行失败了,算了不折腾了。
3、跟踪netstat代码,查看状态展示
先说结论:只有SYN_RECV,没有TCP_NEW_SYN_RECV
之前 分析netstat中的Send-Q和Recv-Q 中我们分析过netstat源码,快速找到解析逻辑所在位置:main->tcp_info->tcp_do_one
1
2
3
4
[root@xdlinux ➜ /root ]$ netstat -anp|head -n4
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 9218/docker-proxy
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// net-tools-2.10/netstat.c
// sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode
// 0: 00000000:0016 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 22556 1 ffff8a4f35c39480 100 0 0 10 0
static void tcp_do_one(int lnr, const char *line, const char *prot)
{
...
// /proc/net/tcp中的行解析
num = sscanf(line,
"%d: %64[0-9A-Fa-f]:%X %64[0-9A-Fa-f]:%X %X %lX:%lX %X:%lX %lX %d %d %lu %*s\n",
&d, local_addr, &local_port, rem_addr, &rem_port, &state,
&txq, &rxq, &timer_run, &time_len, &retr, &uid, &timeout, &inode);
...
// 对应:Proto Recv-Q Send-Q Local Address Foreign Address State
printf("%-4s %6ld %6ld %-*s %-*s %-11s",
prot, rxq, txq, (int)netmax(23,strlen(local_addr)), local_addr, (int)netmax(23,strlen(rem_addr)), rem_addr, _(tcp_state[state]));
...
}
// 其中,tcp_state数组转换如下,并没有 TCP_NEW_SYN_RECV
// net-tools-2.10/netstat.c
static const char *tcp_state[] =
{
"",
N_("ESTABLISHED"),
N_("SYN_SENT"),
N_("SYN_RECV"),
N_("FIN_WAIT1"),
N_("FIN_WAIT2"),
N_("TIME_WAIT"),
N_("CLOSE"),
N_("CLOSE_WAIT"),
N_("LAST_ACK"),
N_("LISTEN"),
N_("CLOSING")
};
4、跟踪内核代码,服务端(内核)侧的state状态更新
由上可知客户端netstat不会展示TCP_NEW_SYN_RECV状态。继续跟踪下内核中往/proc/net/tcp里写的state状态
上面那篇netstat博客也分析过其调用路径为:序列文件的.show->实际注册的是tcp4_seq_show->get_tcp4_sock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// linux-5.10.10/net/ipv4/tcp_ipv4.c
static void get_tcp4_sock(struct sock *sk, struct seq_file *f, int i)
{
...
// 获取struct sock结构中的: sk->sk_state,实际为:__sk_common.skc_state
state = inet_sk_state_load(sk);
...
// /proc/net/tcp文件中,tx_queue:rx_queue
seq_printf(f, "%4d: %08X:%04X %08X:%04X %02X %08X:%08X %02X:%08lX "
"%08X %5u %8d %lu %d %pK %lu %lu %u %u %d",
i, src, srcp, dest, destp, state,
READ_ONCE(tp->write_seq) - tp->snd_una,
rx_queue,
timer_active,
...);
}
再看下面TCP_NEW_SYN_RECV的更新,对比可知:
- 写到proc序列文件中的是取
struct sock中的__sk_common.skc_state - 而
TCP_NEW_SYN_RECV状态是在struct inet_request_sock中的req.__req_common.skc_state中初始化的 - tips:
__sk_common和__req_common的结构都是struct sock_common,关键是要区分其所属的具体结构
根据上面协议控制块的图,可直观看到两者是不同的TCP协议控制块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// linux-5.10.10/net/ipv4/tcp_input.c
// 根据请求sock申请并初始化一个 request_sock,状态为 TCP_NEW_SYN_RECV
struct request_sock *inet_reqsk_alloc(const struct request_sock_ops *ops,
struct sock *sk_listener,
bool attach_listener)
{
// 分配一个 request_sock,注册ops为 struct request_sock_ops tcp_request_sock_ops
// 开了 cookies 则 attach_listener传入的是 false
struct request_sock *req = reqsk_alloc(ops, sk_listener,
attach_listener);
if (req) {
// 转变为 inet_request_sock
struct inet_request_sock *ireq = inet_rsk(req);
...
// #define ireq_state req.__req_common.skc_state
// 对应 request_sock中`struct sock_common __req_common;`成员中的 `volatile unsigned char skc_state;`变量
ireq->ireq_state = TCP_NEW_SYN_RECV;
write_pnet(&ireq->ireq_net, sock_net(sk_listener));
ireq->ireq_family = sk_listener->sk_family;
}
return req;
}
于是可以得到结论(待确定TODO):
/proc/net/tcp序列文件里不会体现TCP_NEW_SYN_RECV状态,netstat也观测不到。
另外回头看一下上面eBPF跟踪逻辑,本身就萃取了sock和request_sock两者的信息,所以跟踪到了TCP_NEW_SYN_RECV状态,而并不是在同一个结构处监测到的。
request_sock和sock间的状态流转,暂时先不关注,后续其他博客中再跟踪。基本过程是:
在服务器接收了SYN之后,会调用
tcp_conn_request来处理连接请求,其中调用inet_reqsk_alloc来创建请求控制块,可见请求控制块的ireq_state被初始化为TCP_NEW_SYN_RECV;
tcp_v4_rcv函数中会对TCP_NEW_SYN_RECV进行处理,如果连接检查成功,则需要新建控制块来处理连接,这个新建控制块的状态将会使用TCP_SYN_RECV状态;
简单看了下tcp_v4_rcv的逻辑,里面的struct sock结构貌似用到了TCP_NEW_SYN_RECV状态。所以上述结论还要进一步确认,先待定。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// linux-5.10.10/net/ipv4/tcp_ipv4.c
int tcp_v4_rcv(struct sk_buff *skb)
{
...
struct sock *sk;
...
// 从`struct sk_buff *skb`里返回 `struct sock *`信息
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,
th->dest, sdif, &refcounted);
...
process:
...
if (sk->sk_state == TCP_NEW_SYN_RECV) {
struct request_sock *req = inet_reqsk(sk);
bool req_stolen = false;
...
}
...
}
5. inet_listen监听流程
在说明全连接队列最大长度时,简单提到过listen系统调用,会调用到TCP协议注册的inet_listen,此处进一步分析其逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
// linux-5.10.10/net/socket.c(不同内核版本可能有部分差异,不影响流程)
int __sys_listen(int fd, int backlog)
{
...
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
// 获取sysctl配置的 net.core.somaxconn 参数
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
// 取min(传入的backlog, 系统net.core.somaxconn)
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
// ops里是一系列socket操作的函数指针(如bind/accept),inet_init(void)网络协议初始化时会设置
// 其中,tcp协议的结构是 inet_stream_ops,里面的listen函数指针赋值为:inet_listen
err = sock->ops->listen(sock, backlog);
...
}
...
}
// linux-5.10.10/net/ipv4/af_inet.c
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
lock_sock(sk);
...
// __sys_listen(linux-5.10.176\net\socket.c)调用时,传进来的的backlog值是`min(调__sys_listen传入的backlog, 系统net.core.somaxconn)`
// 此处设置到struct socket中struct sock相应成员中: sk_max_ack_backlog
WRITE_ONCE(sk->sk_max_ack_backlog, backlog);
if (old_state != TCP_LISTEN) {
...
// 监听操作的核心逻辑
err = inet_csk_listen_start(sk, backlog);
if (err)
goto out;
...
}
...
}
下面具体分析调用到的inet_csk_listen_start函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// linux-5.10.10/net/ipv4/inet_connection_sock.c
int inet_csk_listen_start(struct sock *sk, int backlog)
{
// 转换成面向连接的sock
struct inet_connection_sock *icsk = inet_csk(sk);
// 转换成基于网络的sock
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
// icsk_accept_queue里面包含全连接队列、以及半连接队列长度等信息
// 此处仅初始化了一些成员变量,不同版本内核实现有差异(参考链接里是3.10,里面做了内存申请,实现差异较大)
reqsk_queue_alloc(&icsk->icsk_accept_queue);
...
// 设置 socket 状态为 LISTEN
inet_sk_state_store(sk, TCP_LISTEN);
// TCP协议初始化时,注册的函数为 inet_csk_get_port
// 用来处理TCP端口绑定操作,里面逻辑比较复杂,本文先不涉及
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
// TCP注册的函数是 inet_hash
err = sk->sk_prot->hash(sk);
if (likely(!err))
return 0;
}
...
}
5.10内核的request_sock_queue结构里,包含全连接队列、以及半连接队列长度等信息(网络上的文章很多是3.10内核,注意版本对应),和3.10内核的对比,见下面”3.10内核对比“小节。
如上面半连接队列特殊说明所述,半连接队列(哈希表)维护在inet_hashinfo.inet_ehash_bucket中,而这里是包含半连接队列的长度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// linux-5.10.10/net/core/request_sock.c
void reqsk_queue_alloc(struct request_sock_queue *queue)
{
spin_lock_init(&queue->rskq_lock);
spin_lock_init(&queue->fastopenq.lock);
queue->fastopenq.rskq_rst_head = NULL;
queue->fastopenq.rskq_rst_tail = NULL;
// 半连接队列长度初始化
queue->fastopenq.qlen = 0;
// 全连接队列,链表头初始化
queue->rskq_accept_head = NULL;
}
可查看request_sock_queue具体结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// linux-5.10.10/include/net/request_sock.h
// 而3.10中,还包含了显式表示半连接队列的:`struct listen_sock *listen_opt;`
struct request_sock_queue {
spinlock_t rskq_lock;
u8 rskq_defer_accept;
u32 synflood_warned;
// 半连接队列长度
atomic_t qlen;
atomic_t young;
// 全连接队列,链表头
struct request_sock *rskq_accept_head;
struct request_sock *rskq_accept_tail;
struct fastopen_queue fastopenq;
};
6. TCP连接请求处理
6.1. SYN接收处理接口是哪个?何时注册的?
对于TCP,第一次接收处理时即处理三次握手的第一次SYN,先梳理其注册的处理接口
inet_init初始化网络协议->注册TCP协议(struct proto tcp_prot)
注册的init接口为: .init = tcp_v4_init_sock,,其中会指定tcp协议socket连接的处理接口ipv4_specific
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// linux-5.10.10/net/ipv4/tcp_ipv4.c
static int tcp_v4_init_sock(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
tcp_init_sock(sk);
icsk->icsk_af_ops = &ipv4_specific;
#ifdef CONFIG_TCP_MD5SIG
tcp_sk(sk)->af_specific = &tcp_sock_ipv4_specific;
#endif
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// linux-5.10.10/net/ipv4/tcp_ipv4.c
const struct inet_connection_sock_af_ops ipv4_specific = {
// 发送数据的函数。用于将数据从传输层(TCP)发送到网络层(IP)
.queue_xmit = ip_queue_xmit,
// 用于计算校验和的函数
.send_check = tcp_v4_send_check,
.rebuild_header = inet_sk_rebuild_header,
.sk_rx_dst_set = inet_sk_rx_dst_set,
// 处理SYN段的函数。在TCP三次握手的开始阶段被调用,用于处理来自客户端的SYN包
.conn_request = tcp_v4_conn_request,
// 创建和初始化新socket的函数。在TCP三次握手完成后被调用,用于为新的连接创建一个传输控制块(TCB)并初始化它
.syn_recv_sock = tcp_v4_syn_recv_sock,
.net_header_len = sizeof(struct iphdr),
...
};
所以解答小标题问题:初始化网络协议时,注册SYN处理函数为tcp_v4_conn_request
6.2. SYN请求处理流程
然后看下三次握手时第一次请求SYN的处理函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
// linux-5.10.10/net/ipv4/tcp_ipv4.c
// 初始化时注册的处理第一次SYN的函数
// sk是socket, skb是数据包
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
// 如果是广播或者组播的SYN请求包,直接drop
/* Never answer to SYNs send to broadcast or multicast */
if (skb_rtable(skb)->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST))
goto drop;
// 处理请求,处理类通过参数传入(结构体指针模拟多态) tcp_request_sock_ops 和 tcp_request_sock_ipv4_ops
// 具体初始化分别为:`struct request_sock_ops tcp_request_sock_ops` 和 `const struct tcp_request_sock_ops tcp_request_sock_ipv4_ops`
return tcp_conn_request(&tcp_request_sock_ops,
&tcp_request_sock_ipv4_ops, sk, skb);
drop:
tcp_listendrop(sk);
return 0;
}
// request_sock_ops是用于定义连接请求(request socket)操作的结构体
/*
在 TCP/IP 协议栈中,当一个连接请求(如 SYN 包)到达时,内核不会立即创建一个完整的套接字(socket),
而是先创建一个连接请求套接字(request socket),这个套接字只包含建立连接所需的最少信息。
一旦连接被确认(如收到 SYN/ACK 和 ACK),这个连接请求套接字就会被转换为一个完整的套接字。
*/
struct request_sock_ops tcp_request_sock_ops __read_mostly = {
.family = PF_INET,
.obj_size = sizeof(struct tcp_request_sock),
// 当需要重传 SYN/ACK 响应时调用的函数
.rtx_syn_ack = tcp_rtx_synack,
// 发送ACK响应的函数
.send_ack = tcp_v4_reqsk_send_ack,
// 当请求套接字不再需要时调用的析构函数,用于释放资源
.destructor = tcp_v4_reqsk_destructor,
// 发送RST响应的函数,即拒绝连接请求
.send_reset = tcp_v4_send_reset,
// 当SYN/ACK超时时调用
.syn_ack_timeout = tcp_syn_ack_timeout,
};
// 虽然跟上面全局变量重名,但这里是一个结构体
/*
该结构是 TCP 协议栈用于扩展 struct request_sock_ops 结构体以处理 TCP 特定的连接请求操作的结构体。
由于 TCP 连接建立过程比一些其他协议(如 UDP)更复杂,因此 TCP 需要额外的函数和逻辑来处理 SYN 包的接收、确认、超时等情况。
*/
const struct tcp_request_sock_ops tcp_request_sock_ipv4_ops = {
.mss_clamp = TCP_MSS_DEFAULT,
#ifdef CONFIG_TCP_MD5SIG
.req_md5_lookup = tcp_v4_md5_lookup,
.calc_md5_hash = tcp_v4_md5_hash_skb,
#endif
// 初始化TCP请求套接字的函数
.init_req = tcp_v4_init_req,
#ifdef CONFIG_SYN_COOKIES
.cookie_init_seq = cookie_v4_init_sequence,
#endif
.route_req = tcp_v4_route_req,
// 初始化TCP序列号的函数
.init_seq = tcp_v4_init_seq,
// 初始化TCP时间戳偏移的函数,时间戳用于计算往返时间(RTT)和防止被包裹的序列号
.init_ts_off = tcp_v4_init_ts_off,
// 发送SYN/ACK响应的函数
.send_synack = tcp_v4_send_synack,
};
具体处理逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
// linux-5.10.10/net/ipv4/tcp_input.c
// 处理第一次SYN请求
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
...
// tcp_syncookies:1表示当半连接队列满时才开启;2表示无条件开启功能,此处可看到就算半连接队列满了也不drop
// inet_csk_reqsk_queue_is_full:判断半连接队列是否满(相对于4.4之前的内核,之后内核中半连接队列最大长度也和全连接队列一样)
if ((net->ipv4.sysctl_tcp_syncookies == 2 ||
inet_csk_reqsk_queue_is_full(sk)) && !isn) {
want_cookie = tcp_syn_flood_action(sk, rsk_ops->slab_name);
if (!want_cookie)
goto drop;
}
...
// 检查当前 sock 的全连接队列是否满
/*
上面是:inet_csk(sk)->icsk_accept_queue->qlen,判断的是半连接队列长度
下面是:sk->sk_ack_backlog
*/
if (sk_acceptq_is_full(sk)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
// 创建一个request_sock,socket状态为:TCP_NEW_SYN_RECV;
// 里面包含一个引用计数,涉及sock的管理,4.4做的内存优化,暂忽略
// 这里第3个参数,如果没开启cookie则传入true,一般是开的,所以传false
req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie);
if (!req)
goto drop;
...
if (!want_cookie && !isn) {
// 没开启syncookies时,若 `max_syn_backlog - 半连接长度` < max_syn_backlog>>2,则丢弃请求包
if (!net->ipv4.sysctl_tcp_syncookies &&
(net->ipv4.sysctl_max_syn_backlog - inet_csk_reqsk_queue_len(sk) <
(net->ipv4.sysctl_max_syn_backlog >> 2)) &&
!tcp_peer_is_proven(req, dst)) {
...
goto drop_and_release;
}
...
}
...
// 发送SYN+ACK,TCP协议注册的是 tcp_v4_send_synack 里面会生成应答报文
if (fastopen_sk) {
...
af_ops->send_synack(fastopen_sk, dst, &fl, req,
&foc, TCP_SYNACK_FASTOPEN, skb);
...
}else {
...
af_ops->send_synack(sk, dst, &fl, req, &foc,
!want_cookie ? TCP_SYNACK_NORMAL : TCP_SYNACK_COOKIE, skb);
...
}
// 减少一个引用
// 5.10新内核 共用一份空间 ?
reqsk_put(req);
return 0;
drop_and_release:
dst_release(dst);
drop_and_free:
__reqsk_free(req);
drop:
// 丢弃包
tcp_listendrop(sk);
return 0;
}
1
2
3
4
5
6
7
8
9
// linux-5.10.10/include/net/inet_connection_sock.h
// 判断半连接队列是否已满
static inline int inet_csk_reqsk_queue_is_full(const struct sock *sk)
{
// sk->sk_max_ack_backlog,之前跟踪listen,可以看到是将 min(backlog,somaxconn) 赋值给了它
// 半连接队列 >= 最大半连接队列数量(相对于4.4之前内核,新内核的全连接队列和半连接队列最大长度一样。队列是同一个,根据状态区分?)
// 半连接队列的长度,这里取的是inet_connection_sock.icsk_accept_queue.qlen
return inet_csk_reqsk_queue_len(sk) >= sk->sk_max_ack_backlog;
}
7. 3.10内核对比
7.1. inet_listen流程
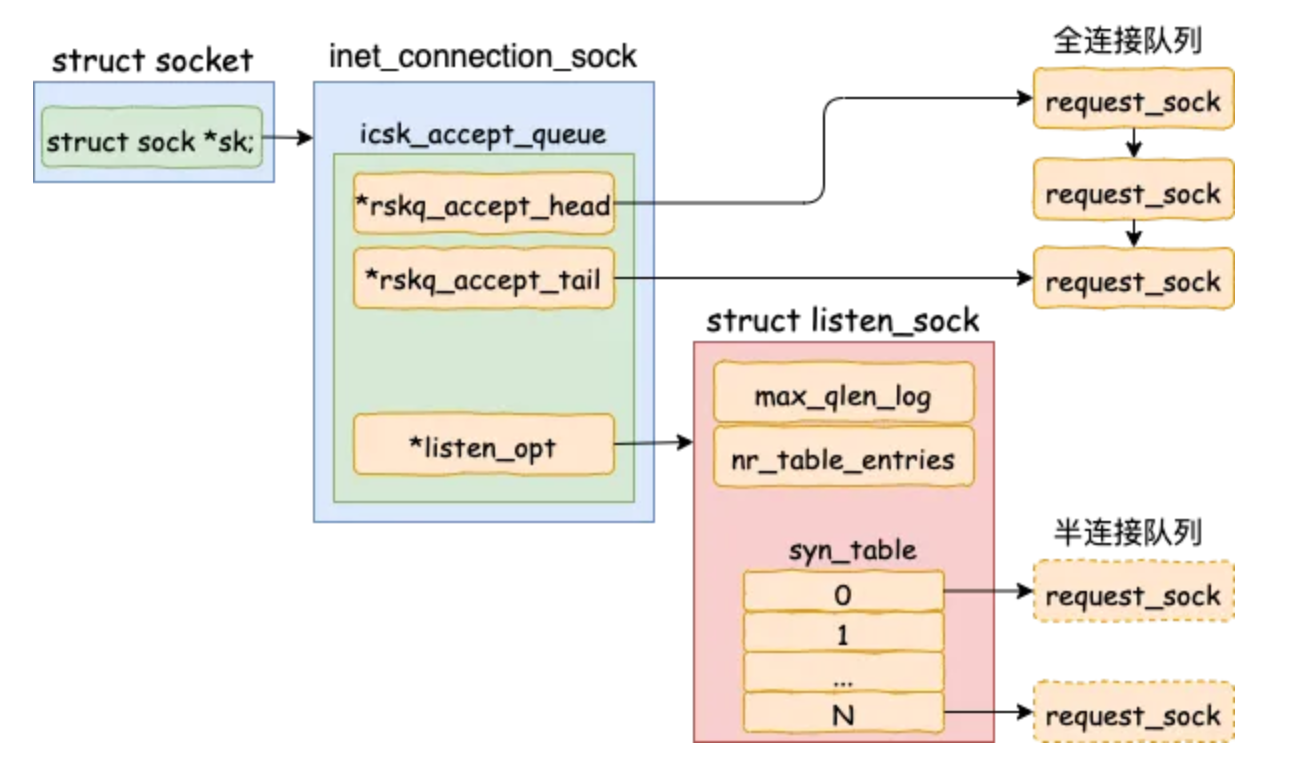
下述逻辑可用下图概括:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// linux-3.10.89/net/ipv4/af_inet.c
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
unsigned char old_state;
int err;
...
if (old_state != TCP_LISTEN) {
...
// 初始化半连接队列和
err = inet_csk_listen_start(sk, backlog);
if (err)
goto out;
}
sk->sk_max_ack_backlog = backlog;
err = 0;
...
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// linux-3.10.89/net/ipv4/inet_connection_sock.c
// nr_table_entries传入的是 backlog
int inet_csk_listen_start(struct sock *sk, const int nr_table_entries)
{
struct inet_sock *inet = inet_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
// 申请半连接队列的空间,初始化全连接队列为NULL
int rc = reqsk_queue_alloc(&icsk->icsk_accept_queue, nr_table_entries);
...
// 设置socket状态为 LISTEN
sk->sk_state = TCP_LISTEN;
// TCP协议初始化时指定了: inet_csk_get_port
// 用来处理TCP端口绑定操作,里面逻辑比较复杂,本文先不涉及
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
// inet_hash
sk->sk_prot->hash(sk);
return 0;
}
...
}
先说明下上述icsk->icsk_accept_queue队列,其定义为:struct request_sock_queue icsk_accept_queue;队列结构,里面包含了全连接和半连接队列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// linux-3.10.89/include/net/request_sock.h
struct request_sock_queue {
// 全连接队列,是一个先进先出(FIFO)的链表结构
struct request_sock *rskq_accept_head;
struct request_sock *rskq_accept_tail;
rwlock_t syn_wait_lock;
u8 rskq_defer_accept;
/* 3 bytes hole, try to pack */
// 里面包含了半连接队列
struct listen_sock *listen_opt;
struct fastopen_queue *fastopenq;
};
struct listen_sock {
// 半连接队列长度的log2对数
u8 max_qlen_log;
u8 synflood_warned;
/* 2 bytes hole, try to use */
int qlen;
int qlen_young;
int clock_hand;
u32 hash_rnd;
// 半连接队列长度
u32 nr_table_entries;
// 此处实际以hash表方式管理,用于第三次握手时快速地查找出来第一次握手时留存的`request_sock`对象
struct request_sock *syn_table[0];
};
继续看上面inet_csk_listen_start里初始化半连接队列的具体操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
// linux-3.10.89/net/core/request_sock.c
// nr_table_entries传入的是 backlog(listen时传入的参数)
int reqsk_queue_alloc(struct request_sock_queue *queue,
unsigned int nr_table_entries)
{
size_t lopt_size = sizeof(struct listen_sock);
struct listen_sock *lopt;
// min(backlog, tcp_max_syn_backlog)
nr_table_entries = min_t(u32, nr_table_entries, sysctl_max_syn_backlog);
// 取 max(8, nr_table_entries)
nr_table_entries = max_t(u32, nr_table_entries, 8);
// 2倍(结果按2^n取整)
nr_table_entries = roundup_pow_of_two(nr_table_entries + 1);
// 申请空间
lopt_size += nr_table_entries * sizeof(struct request_sock *);
if (lopt_size > PAGE_SIZE)
lopt = vzalloc(lopt_size);
else
lopt = kzalloc(lopt_size, GFP_KERNEL);
if (lopt == NULL)
return -ENOMEM;
// 此处含义:取 max( 3, log2(nr_table_entries) )
// 每次 1<<max_qlen_log即乘2,直到>=nr_table_entries,即nr_table_entries以2为底
for (lopt->max_qlen_log = 3;
(1 << lopt->max_qlen_log) < nr_table_entries;
lopt->max_qlen_log++);
get_random_bytes(&lopt->hash_rnd, sizeof(lopt->hash_rnd));
rwlock_init(&queue->syn_wait_lock);
// 全连接队列 链表头
queue->rskq_accept_head = NULL;
// 上述计算的半连接长度限制
lopt->nr_table_entries = nr_table_entries;
write_lock_bh(&queue->syn_wait_lock);
// struct listen_sock *lopt; 即我们常说的 半连接队列
queue->listen_opt = lopt;
write_unlock_bh(&queue->syn_wait_lock);
return 0;
}
可看到,相比于5.10内核,此处额外申请了一个半连接队列的空间。
上面计算描述有点抽象,举个例子(来自参考链接里的:为什么服务端程序都需要先 listen 一下?):
- 假设:某服务器上内核参数
net.core.somaxconn为 128,net.ipv4.tcp_max_syn_backlog为 8192。那么当用户 backlog 传入 5 时,半连接队列到底是多长呢?
和代码一样,我们还把计算分为四步,最终结果为 16。
1
2
3
4
min (backlog, somaxconn) = min (5, 128) = 5
min (5, tcp_max_syn_backlog) = min (5, 8192) = 5
max (5, 8) = 8
roundup_pow_of_two (8 + 1) = 16
- somaxconn 和
tcp_max_syn_backlog保持不变,listen 时的 backlog 加大到512,再算一遍,结果为256。
1
2
3
4
min (backlog, somaxconn) = min (512, 128) = 128
min (128, tcp_max_syn_backlog) = min (128, 8192) = 128
max (128, 8) = 128
roundup_pow_of_two (128 + 1) = 256
把半连接队列长度的计算归纳成一句话,半连接队列的长度是
min(backlog, somaxconn, tcp_max_syn_backlog) + 1 再上取整到 2 的幂次,但最小不能小于16。
7.2. SYN请求处理流程
和5.10内核一样,SYN处理接口在ipv4_specific中指定为tcp_v4_conn_request
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
// linux-3.10.89/net/ipv4/tcp_ipv4.c
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
...
struct request_sock *req;
struct inet_request_sock *ireq;
struct tcp_sock *tp = tcp_sk(sk);
...
struct sk_buff *skb_synack;
...
// 半连接队列是否满了
// queue->listen_opt->qlen >> queue->listen_opt->max_qlen_log
// queue是指:&inet_csk(sk)->icsk_accept_queue
if (inet_csk_reqsk_queue_is_full(sk) && !isn) {
want_cookie = tcp_syn_flood_action(sk, skb, "TCP");
if (!want_cookie)
goto drop;
}
// 全连接队列是否满了 (若满,且有 young_ack,则直接丢弃)
// sk->sk_ack_backlog > sk->sk_max_ack_backlog
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
// 都未超出限制,则申请空间
req = inet_reqsk_alloc(&tcp_request_sock_ops);
if (!req)
goto drop;
...
// 生成需要应答的SYN+ACK报文
skb_synack = tcp_make_synack(sk, dst, req,
fastopen_cookie_present(&valid_foc) ? &valid_foc : NULL);
if (skb_synack) {
// 检查报文
__tcp_v4_send_check(skb_synack, ireq->loc_addr, ireq->rmt_addr);
skb_set_queue_mapping(skb_synack, skb_get_queue_mapping(skb));
} else
goto drop_and_free;
if (likely(!do_fastopen)) {
int err;
// 发送报文,IP层
err = ip_build_and_send_pkt(skb_synack, sk, ireq->loc_addr,
ireq->rmt_addr, ireq->opt);
err = net_xmit_eval(err);
if (err || want_cookie)
goto drop_and_free;
tcp_rsk(req)->snt_synack = tcp_time_stamp;
tcp_rsk(req)->listener = NULL;
// 加到半连接队列中 (SYN队列,实际是hash表)
inet_csk_reqsk_queue_hash_add(sk, req, TCP_TIMEOUT_INIT);
...
}
...
return 0;
drop_and_release:
dst_release(dst);
drop_and_free:
reqsk_free(req);
drop:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
return 0;
}
7.3. netstat -s中的溢出统计说明(纠错)
之前提到netstat -s里统计的溢出和drop,一个是全连接一个是半连接,其实是不准确的。
先说结论:
times the listen queue of a socket overflowed,全连接队列溢出,统计是正确的SYNs to LISTEN sockets dropped,不仅仅只是在半连接队列发生溢出的时候会增加该值(比如全连接队列溢出时也增加)
1
2
3
[root@iZ2ze45jbqveelsasuub53Z ~]# netstat -s|grep -i listen
6 times the listen queue of a socket overflowed
6 SYNs to LISTEN sockets dropped
上面SYN处理函数tcp_v4_conn_request里面,NET_INC_STATS_BH(5.10中为NET_INC_STATS)函数用于统计SNMP信息,netstat根据SNMP进行解析打印。
伪代码简化如下。
- 全连接队列满时,累加
LINUX_MIB_LISTENOVERFLOWS和LINUX_MIB_LISTENDROPS - 半连接队列满时,只累加
LINUX_MIB_LISTENDROPS
1
2
3
4
5
6
7
8
9
10
11
12
13
// 3.10
tcp_v4_conn_request()
{
...
if 半连接队列满 && 不开cookie
goto drop;
if 全连接队列满
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
drop:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
return 0;
}
1
2
3
4
5
6
7
8
9
10
// linux-3.10.89/include/uapi/linux/snmp.h
/* linux mib definitions */
enum
{
LINUX_MIB_NUM = 0,
...
LINUX_MIB_LISTENOVERFLOWS, /* ListenOverflows */
LINUX_MIB_LISTENDROPS, /* ListenDrops */
...
}
netstat代码在net-tools中,按上述key搜索可知
1
2
3
4
5
6
7
8
9
// statistics.c
struct entry Tcpexttab[] =
{
...
{ "ListenOverflows", N_("%u times the listen queue of a socket overflowed"),
opt_number },
{ "ListenDrops", N_("%u SYNs to LISTEN sockets dropped"), opt_number },
...
}
所以:
全连接队列溢出:
ListenOverflows,对应netstat -s里的times the listen queue of a socket overflowed- linux内核代码中全局搜索
LINUX_MIB_LISTENOVERFLOWS,另一个场景累加是在tcp_v4_syn_recv_sock(三次握手成功后的处理)中,也是判断全连接队列满才累加 netstat -s统计的全连接队列溢出次数是准确的
半连接队列溢出:
ListenDrops,对应netstat -s里的SYNs to LISTEN sockets dropped- 全局搜索
LINUX_MIB_LISTENDROPS,除了tcp_v4_conn_request和tcp_v4_syn_recv_sock中类似情况,还有tcp_v4_err - 可看到全连接队列溢出时,该值也会累加,所以不能简单当作半连接队列溢出。且4.4之后内核中,没有明确的半连接队列了。
对于半连接队列来说,只要保证
tcp_syncookies这个内核参数是1就能保证不会有因为半连接队列满而发生的丢包。
如果确实较真就想看一看,
netstat -s | grep "SYNs"这个是没有办法说明问题的。还需要你自己计算一下半连接队列的长度,再看下当前SYN_RECV状态的连接的数量。
生产环境中,tcp_syncookies一般是开启的,关闭的观察实验就先不做了。后续用ebpf跟踪其他关键过程。
8. 小结
跟踪代码,梳理了服务端监听和处理SYN请求的大概流程。3.10和5.10版本内核在半连接这块的差异比较大,而差异点在之前版本(如linux 4.4)就引入了。
本想一篇文章中介绍半连接队列并简单实验,过程中发现梳理起来没那么简单。另外过程中发现了不少高质量的文章,还需要持续学习。
本文当作第1、2个问题的部分解答,不过只涉及服务端接收SYN后的部分处理流程,及全连接半连接队列drop包的场景,”具体”逻辑待持续深入。
- 半连接队列溢出情况分析,服务端接收
具体概要处理逻辑 - 内核drop包的时机,以及跟抓包的关系。哪些情况可能会抓不到drop的包?
- systemtap/ebpf跟踪TCP状态变化,跟踪上述drop事件
- 上述全连接实验case1中,2MSL内没观察到客户端连接
FIN_WAIT2状态,为什么?
9. 参考
1、从一次线上问题说起,详解 TCP 半连接队列、全连接队列
2、不为人知的网络编程(十五):深入操作系统,一文搞懂Socket到底是什么
10、GPT