eBPF学习实践系列(一) -- 初识eBPF
eBPF学习实践,初步整理学习。
1. 背景
在“TCP半连接全连接(一) – 全连接队列相关过程”这篇文章中,进行了全连接队列溢出的实验,准备后续用eBPF跟踪过程。
eBPF名声在外,之前没用过时简单翻完了《Linux内核观测技术BPF》这本动物书,正好趁这个机会掌握熟悉这个技能,祛魅。
在基本学习eBPF之后尝试用libbpf-bootstrap写跟踪程序,发现还差些火候。先把学习过程整理一下单独作为一篇博客,初步技术储备。索性后续eBPF学习过程作为一个系列,此为第一篇。
1.1. 初学建议参考
eBPF学习实践记录包含下面几篇(另外各篇里的参考链接文章很值得一看),其中也包含捣腾的”弯路”。回顾并结合自己学习实践过程,给一些初学的建议参考。
- eBPF学习实践系列(一) – 初识eBPF
- eBPF学习实践系列(二) – bcc tools网络工具集
- eBPF学习实践系列(三) – 基于libbpf开发实践
- eBPF学习实践系列(四) – eBPF的各种追踪类型
- eBPF学习实践系列(五) – 分析tcplife.bpf.c程序
- TCP半连接全连接(三) – eBPF跟踪全连接队列溢出(上)
- TCP发送接收过程 – 学习netfilter和iptables
eBPF初学建议顺序:
- 可从
eBPF学习实践系列(一),先大致了解eBPF概念,理解大概功能- bcc/bpftrace/libbpf-bootstrap/cilium等都可以用来开发eBPF程序,一般也提供了现成可用的工具或者脚本。以前看这个也是eBPF那个也是eBPF有点迷惑,其实都是eBPF的上层开发框架,类比日志和日志库:底层记日志文件,但有各种类型的日志库封装。
- 本篇
libbpf-bootstrap开发框架了解即可,不需要上手就去跟着hello world实操demo。只要理解不管上面哪种框架,都是分内核态和用户态两部分文件。 eBPF学习实践系列(三) -- 基于libbpf开发实践和eBPF学习实践系列(五) -- 分析tcplife.bpf.c程序可以先跳过,最后需要理解内部流程再回头看。libbpf及其CO-RE机制是开发可移植eBPF程序的利器。
- 对于大多数人来说,感觉
bcc tools和bpftrace已经能满足大部分的需要了。- 从
eBPF学习实践系列(二) -- bcc tools网络工具集里了解bcc tools提供的现成工具能干什么,体会eBPF的强大 - 利用
bpftrace只要一行命令就可以实现自定义追踪,从eBPF学习实践系列(六) -- bpftrace学习和使用里可了解用法(或参考链接里的官网教程)
- 从
- 用
bpftrace要自定义追踪时,自然会疑惑要用什么追踪点、怎么查看追踪点对应的数据结构、系统支持哪些eBPF类型和追踪点(tracepoint/kprobe等)- 那就可以从
eBPF学习实践系列(四) -- eBPF的各种追踪类型里了解怎么查看系统支持的eBPF程序类型、追踪点及对应结构 tracepoint、kprobe是比较常用的,uprobe和USDT自己还没用过
- 那就可以从
- 后面几篇是问题实验场景里的eBPF相关使用情况
TCP半连接全连接(三) -- eBPF跟踪全连接队列溢出(上)bcc tools跟踪实验过程中的TCP状态变化TCP半连接全连接(四) -- eBPF跟踪全连接队列溢出(下)bpftrace跟踪全连接队列溢出(还有个libbpf程序开发失败的示例)TCP发送接收过程 -- 学习netfilter和iptablesbpftrace跟踪内核中网络的调用栈
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. eBPF基本介绍
eBPF(Extended Berkeley Packet Filter)是一个在Linux内核中实现的强大工具,允许用户空间程序通过加载BPF(Berkeley Packet Filter)字节码到内核,安全地执行各种网络、追踪和安全相关的任务。
2.1. eBPF提供了四种不同的操作机制
- 内核跟踪点(Kernel Tracepoints):内核跟踪点是由内核开发人员预定义的事件,可以使用
TRACE_EVENT宏在内核代码中设置。这些跟踪点允许 eBPF 程序挂接到特定的内核事件,并捕获相关数据进行分析和监控。 - USDT(User Statically Defined Tracing):USDT 是一种机制,允许开发人员在应用程序代码中设置预定义的跟踪点。通过在代码中插入特定的标记,eBPF 程序可以挂接到这些跟踪点,并捕获与应用程序相关的数据,以实现更细粒度的观测和分析。
- Kprobes(Kernel Probes):Kprobes 是一种内核探针机制,允许 eBPF 程序在运行时动态挂接到内核代码的任何部分。通过在目标内核函数的入口或出口处插入探针,eBPF 程序可以捕获函数调用和返回的参数、返回值等信息,从而实现对内核行为的监控和分析。
- Uprobes(User Probes):Uprobes 是一种用户探针机制,允许 eBPF 程序在运行时动态挂接到用户空间应用程序的任何部分。通过在目标用户空间函数的入口或出口处插入探针,eBPF 程序可以捕获函数调用和返回的参数、返回值等信息,以实现对应用程序的可观察性和调试能力。
2.2. eBPF内核版本支持及实用工具
由于 eBPF 还在快速发展期,内核中的功能也日趋增强,一般推荐基于
Linux 4.4+ (4.9 以上会更好)内核的来使用 eBPF。
部分 Linux Event 和 BPF 版本支持见下图:
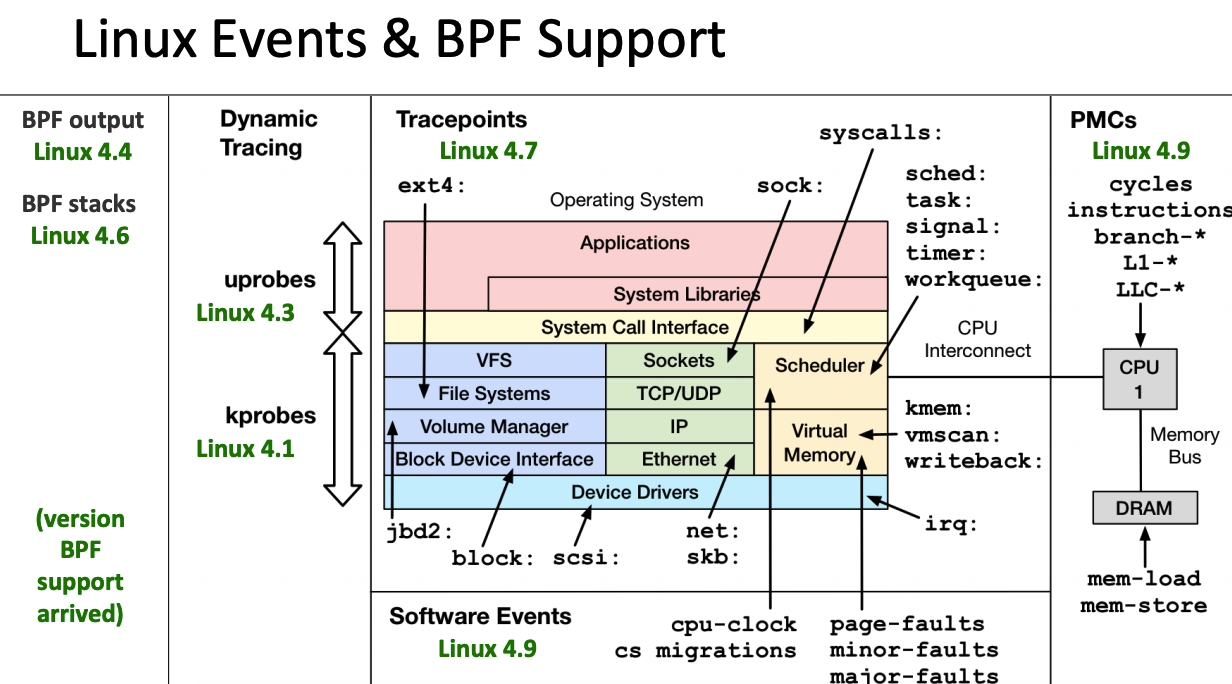
2.2.1. bcc tools:
性能分析大师 Brendan Gregg 等编写了诸多的 BCC 或 BPFTrace 的工具集可以拿来直接使用,可以满足很多我们日常问题分析和排查。
CentOS安装:yum install bcc,而后在/usr/share/bcc/tools/可查看。bcc中工具集示意图如下:
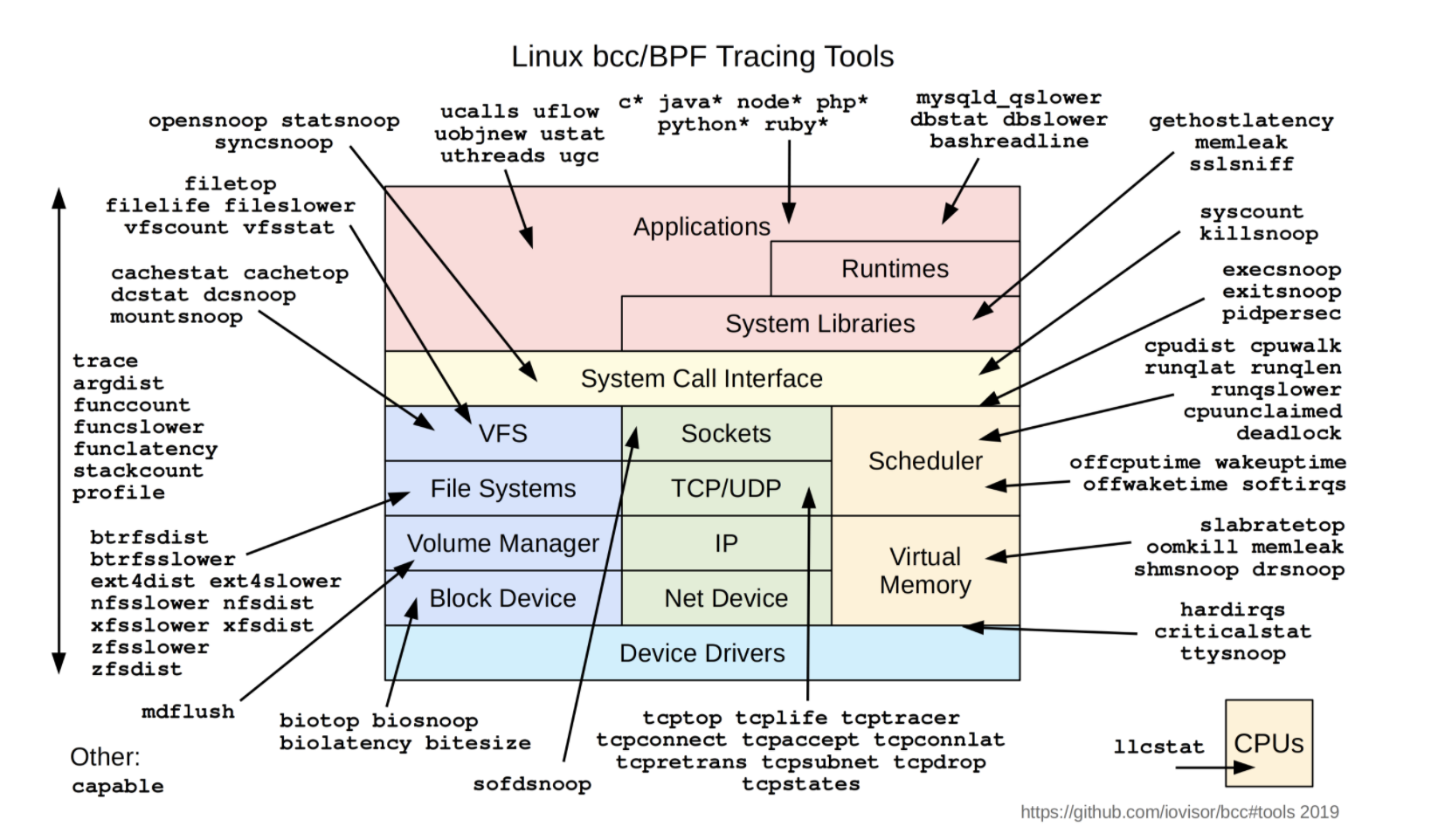
{kind=link}
起一个ECS实例,安装bcc,可看到bcc-tools等依赖及大小(单独安装bcc-tools大概也要300多M),安装后可看到上述工具(里面内容为python)
2.2.2. perf-tools:
说到Brendan Gregg,这里也提一下他创建的perf-tools,这是一个基于ftrace和perf的Linux性能分析工具集(上面的bcc tools是基于eBPF),提供如下工具(里面内容为shell):
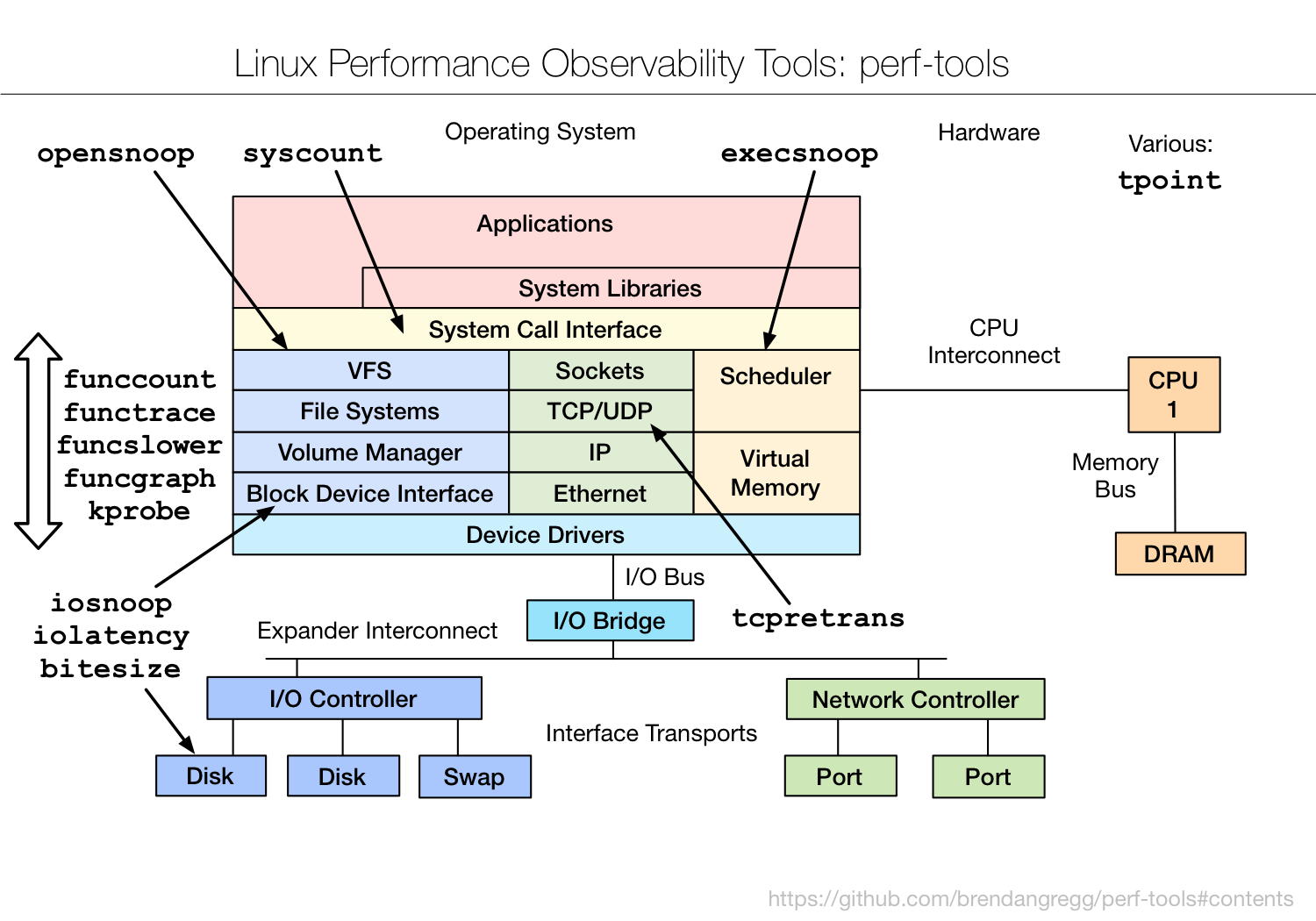
可以看到perf tools里面有些工具和上面的bcc tools功能相同,也有不同的,如:funcgraph(可跟踪内核函数的调用子流程)。
这里有个结合两者定位问题的案例:eBPF/Ftrace 双剑合璧:no space left on device 无处遁形
2.3. BPF程序的开发方式
参考:使用C语言从头开发一个Hello World级别的eBPF程序
(后续如无特别指出,BPF指的就是新一代的eBPF技术,传统BPF称为cBPF)
BPF演进了这么多年,虽然一直在努力提高,但BPF程序的开发与构建体验依然不够理想。为此社区也创建了像BPF Compiler Collection(BCC)这样的用于简化BPF开发的框架和库集合,以及像bpftrace这样的提供高级BPF开发语言的项目(可以理解是开发BPF的DSL语言,Domain Specific Language)。
很多时候我们无需自己开发BPF程序,像bcc和bpftrace这样的开源项目给我们提供了很多高质量的BPF程序。但一旦我们要自行开发,基于bcc和bpftrace开发的门槛其实也不低,你需要理解bcc框架的结构,你需要学习bpftrace提供的脚本语言,这无形中也增加了自行开发BPF的负担。
BPF的移植性问题:
- Linux不同版本内核的数据结构字段可能不同,对于不需要查看这些信息的BPF程序可能不存在问题,但是需要的BPF程序则会存在移植性问题,需要考虑不同内核版本内部数据结构变化的影响
- 最初解决方式是在要运行的目标机器上编译BPF程序,以保证BPF访问的内核类型布局和目标主机内核一致。但这样每次需要在目标机器安装BPF依赖的开发包、编译器,显然比较麻烦。
- 为了解决BPF可移植性问题,内核引入了
BTF(BPF Type Format)和CO-RE(Compile Once - Run Everywhere)两种新技术。BTF提供结构信息以避免对Clang和内核头文件的依赖。CO-RE使得编译出的BPF字节码是可重定位(relocatable)的,避免了LLVM重新编译的需要。- 使用这些新技术构建的BPF程序可以在不同linux内核版本中正常工作,无需为目标机器上的特定内核而重新编译它。目标机器上也无需再像之前那样安装数百兆的LLVM、Clang和kernel头文件依赖了。
- 这些新技术(
BTF、CO-RE)对于BPF程序自身是透明的,Linux内核源码提供的libbpf用户API将上述新技术都封装了起来,只要用户态加载程序基于libbpf开发,那么libbpf就会悄悄地帮助BPF程序在目标主机内核中重新定位到其所需要的内核结构的相应字段,这让libbpf成为开发BPF加载程序的首选。 libbpf究竟是什么?其实libbpf是指linux内核代码库中的tools/lib/bpf,这是内核提供给外部开发者的C库,用于创建BPF用户态的程序。
在开发eBPF程序时,有多种开发框架可供选择,如 bcc(BPF Compiler Collection)libbpf、cilium/ebpf、eunomia-bpf 等。虽然不同工具的特点各异,但它们的基本开发流程大致相同。
libbpf-bootstrap- 内核BPF开发者Andrii Nakryiko在github上开源了一个直接基于
libbpf开发BPF程序与加载器的引导项目libbpf-bootstrap。这个项目中包含使用c和rust开发BPF程序和用户态程序的例子。 “这也是我目前看到的体验最好的基于C语言的BPF程序和加载器的开发方式。”
- 内核BPF开发者Andrii Nakryiko在github上开源了一个直接基于
eunomia-bpf是一个开源的 eBPF 动态加载运行时和开发工具链,它的目的是简化 eBPF 程序的开发、构建、分发、运行。- 它基于
libbpf的CO-RE(Compile Once – Run Everywhere) 轻量级开发框架,支持通过用户态 WASM 虚拟机控制 eBPF 程序的加载和执行,并将预编译的 eBPF 程序打包为通用的 JSON 或 WASM 模块进行分发。 - 网站:eunomia-bpf 用户手册: 让 eBPF 程序的开发和部署尽可能简单
- 它基于
- 下面是一个关于eBPF不错的教程
- 系列教程链接:eBPF 开发实践教程:基于 CO-RE,通过小工具快速上手 eBPF 开发
- 提供了从入门到进阶的 eBPF 开发实践,包括基本概念、代码实例、实际应用等内容。和 BCC 不同的是,我们使用
libbpf、Cilium、libbpf-rs、eunomia-bpf等框架进行开发,包含 C、Go、Rust 等语言的示例。 - 其中的学习建议:关于如何学习 eBPF 相关的开发的一些建议
- 里面也有:
bcc和bpftrace相关简单教程
小结:为简化eBPF开发,发展出了bcc、bpftrace。为解决移植性问题,内核提供了BTF、CO-RE技术,封装在libbpf中。在这之上又有多种基于libbpf框架可选择(当前bcc中也集成了libbpf?)。
下面基于 libbpf-bootstrap 学习梳理,并进行实验。
3. 基于libbpf-bootstrap基本开发示例
一个以开发BPF程序为目的的工程通常由两类源文件组成
- 一类是运行于内核态的BPF程序的源代码文件
- 另外一类则是用于向内核加载BPF程序、从内核卸载BPF程序、与内核态进行数据交互、展现用户态程序逻辑的用户态程序的源代码文件
目前运行于内核态的BPF程序只能用C语言开发(对应于第一类源代码文件),更准确地说只能用受限制的C语法进行开发,并且可以完善地将C源码编译成BPF目标文件的只有clang编译器(clang是一个C、C++、Objective-C等编程语言的编译器前端,采用LLVM作为后端)。
3.1. 安装依赖
安装clang (上面安装bcc只是有clang的lib库)
1
2
3
4
[root@iZ2zeh7m46vtyf29xmdw90Z tools]# clang -v
clang version 15.0.7 ( 15.0.7-1.0.3.al8)
Target: x86_64-koji-linux-gnu
Thread model: posix
3.2. 下载libbpf-bootstrap
临时开的ECS里连不上github,下面操作在本地搞完打包传ECS了。
1、下载 libbpf-bootstrap
git clone https://github.com/libbpf/libbpf-bootstrap.git
2、初始化和更新libbpf-bootstrap的依赖
libbpf-bootstrap将其依赖的libbpf、bpftool以git submodule的形式配置到其项目中,可查看.gitmodules
git submodule update --init --recursive
3.3. hello world级BPF程序
到 libbpf-bootstrap/examples/c 下创建文件
具体结构说明,参考:Building BPF applications with libbpf-bootstrap
3.3.1. helloworld.bpf.c (BPF侧代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// <linux/bpf.h>包含一些BPF相关的、使用内核侧BPF API时必要的类型和常量
#include <linux/bpf.h>
// bpf_helpers.h是libbpf提供的,包含最常使用的一些宏、变量、BPF帮助函数定义
#include <bpf/bpf_helpers.h>
// `SEC(xxx) int bpf_prog(xxx){xxx}` 共同定义将被加载到内核中的BPF程序
// SEC名 会定义libbpf将会创建的BPF程序类型 和 在内核挂载的方式。tracepoint有时简写成tp
// sys_enter_xxx,表示调用到xxx系统调用时会触发此函数。此处即每次调用`execve`时都会调用`bpf_prog`
SEC("tracepoint/syscalls/sys_enter_execve")
// 这里的函数名无所谓,主要是上下文入参的类型,不同eBPF程序类型有对应的上下文结构。
int bpf_prog(void *ctx) {
char msg[] = "Hello, World!";
// bpf中的printf,会打印到 /sys/kernel/debug/tracing/trace_pipe
bpf_printk("invoke bpf_prog: %s\n", msg);
return 0;
}
// SEC("license")注解,license 定义BPF代码的开源协议,内核中要求必须指定许可协议
// SEC() 是bpf_helpers.h提供的
char LICENSE[] SEC("license") = "Dual BSD/GPL";
3.3.2. helloworld.c (用户空间侧代码)
上述BPF侧代码make过程中自动生成骨架,这里将两者集成在一起
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
// 包含上述 helloworld.bpf.c 中BPF的骨架,是基于`bpftool`在makefile某个步骤里自动生成的
// 该文件还通过把编译的BPF目标文件的内容嵌入进来,简化了BPF代码部署,只要包含该头文件即可
#include "helloworld.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
// 这里不管libbpf日志级别,都进行打印了
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
// 生成的helloworld.skel.h中的骨架结构
struct helloworld_bpf *skel;
int err;
libbpf_set_strict_mode(LIBBPF_STRICT_ALL);
/* Set up libbpf errors and debug info callback */
// 设置一个用户自定义的回调函数,处理 libbpf 的日志。
// libbpf默认log函数只记录error级别日志;这个回调设置很有用,可自定义记录各类debug日志
libbpf_set_print(libbpf_print_fn);
// 下面理解原来的注释即可
/* Open BPF application */
skel = helloworld_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* Load & verify BPF programs */
err = helloworld_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
/* Attach tracepoint handler */
err = helloworld_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
/* trigger our BPF program */
fprintf(stderr, ".");
sleep(1);
}
cleanup:
helloworld_bpf__destroy(skel);
return -err;
}
3.3.3. Makefile修改,编译并执行
1、libbpf_bootstrap/examples/c/Makefile 里的APPS,加个helloworld
1
APPS = helloworld minimal minimal_legacy bootstrap uprobe kprobe fentry
2、make进行编译,编译报错:
1
2
3
4
5
6
7
In file included from bpf.c:37:
libbpf_internal.h:19:10: fatal error: libelf.h: No such file or directory
19 | #include <libelf.h>
| ^~~~~~~~~~
compilation terminated.
make[1]: *** [Makefile:134: /home/xd/libbpf-bootstrap/examples/c/.output//libbpf/staticobjs/bpf.o] Error 1
make: *** [Makefile:87: /home/xd/libbpf-bootstrap/examples/c/.output/libbpf.a] Error 2
需要依赖zlib和libelf
Your system should also have zlib (libz-dev or zlib-devel package) and libelf (libelf-dev or elfutils-libelf-devel package) installed. Those are dependencies of libbpf necessary to compile and run it properly. (Building BPF applications with libbpf-bootstrap)
安装:yum install zlib-devel elfutils-libelf-devel
重新编译成功。
3、执行
1
2
3
4
5
6
7
8
9
10
11
12
13
[root@iZ2ze8x6ziml84sbvfcx20Z c]# ./helloworld
libbpf: loading object 'helloworld_bpf' from buffer
libbpf: elf: section(2) .symtab, size 168, link 1, flags 0, type=2
libbpf: elf: section(3) tracepoint/syscalls/sys_enter_execve, size 120, link 0, flags 6, type=1
libbpf: sec 'tracepoint/syscalls/sys_enter_execve': found program 'bpf_prog' at insn offset 0 (0 bytes), code size 15 insns (120 bytes)
libbpf: elf: section(4) .rodata.str1.1, size 14, link 0, flags 32, type=1
...
libbpf: prog 'bpf_prog': found data map 1 (hellowor.rodata, sec 5, off 0) for insn 9
libbpf: object 'helloworld_bpf': failed (-22) to create BPF token from '/sys/fs/bpf', skipping optional step...
libbpf: map '.rodata.str1.1': created successfully, fd=3
libbpf: map 'hellowor.rodata': created successfully, fd=4
Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` to see output of the BPF programs.
..................................................
查看输出:
1
2
3
4
5
[root@iZ2ze8x6ziml84sbvfcx20Z ~]# cat /sys/kernel/debug/tracing/trace_pipe
<...>-7041 [000] d... 1386.056674: bpf_trace_printk: invoke bpf_prog: Hello, World!
bash-7045 [000] d... 1386.387547: bpf_trace_printk: invoke bpf_prog: Hello, World!
bash-7047 [000] d... 1386.390160: bpf_trace_printk: invoke bpf_prog: Hello, World!
<...>-7058 [000] d... 1386.399166: bpf_trace_printk: invoke bpf_prog: Hello, World!
3.3.4. 附1:生成的骨架文件说明
骨架文件 helloworld.skel.h (.skel.h和.o都生成在.output目录里)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
// helloworld.skel.h
/* SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) */
/* THIS FILE IS AUTOGENERATED BY BPFTOOL! */
#ifndef __HELLOWORLD_BPF_SKEL_H__
#define __HELLOWORLD_BPF_SKEL_H__
#include <errno.h>
#include <stdlib.h>
#include <bpf/libbpf.h>
// 骨架结构,构造了 libbpf 所需结构
struct helloworld_bpf {
struct bpf_object_skeleton *skeleton;
// 可传给 libbpf 相关API函数
struct bpf_object *obj;
// 下述这些段(sections,还可以有bss, data, rodata等段)提供`BPF侧代码`中,用户空间的直接访问,不需要通过系统调用
// maps段
struct {
struct bpf_map *rodata_str1_1;
struct bpf_map *rodata;
} maps;
// progs段
struct {
struct bpf_program *bpf_prog;
} progs;
// links段
struct {
struct bpf_link *bpf_prog;
} links;
#ifdef __cplusplus
static inline struct helloworld_bpf *open(const struct bpf_object_open_opts *opts = nullptr);
static inline struct helloworld_bpf *open_and_load();
static inline int load(struct helloworld_bpf *skel);
static inline int attach(struct helloworld_bpf *skel);
static inline void detach(struct helloworld_bpf *skel);
static inline void destroy(struct helloworld_bpf *skel);
static inline const void *elf_bytes(size_t *sz);
#endif /* __cplusplus */
};
// 中间是对各个接口的具体实现(如helloworld_bpf__load)
...
#ifdef __cplusplus
struct helloworld_bpf *helloworld_bpf::open(const struct bpf_object_open_opts *opts) { return helloworld_bpf__open_opts(opts); }
struct helloworld_bpf *helloworld_bpf::open_and_load() { return helloworld_bpf__open_and_load(); }
int helloworld_bpf::load(struct helloworld_bpf *skel) { return helloworld_bpf__load(skel); }
int helloworld_bpf::attach(struct helloworld_bpf *skel) { return helloworld_bpf__attach(skel); }
void helloworld_bpf::detach(struct helloworld_bpf *skel) { helloworld_bpf__detach(skel); }
void helloworld_bpf::destroy(struct helloworld_bpf *skel) { helloworld_bpf__destroy(skel); }
const void *helloworld_bpf::elf_bytes(size_t *sz) { return helloworld_bpf__elf_bytes(sz); }
#endif /* __cplusplus */
...
#endif /* __HELLOWORLD_BPF_SKEL_H__ */
3.3.5. 附2:Makefile说明
路径:examples/c/Makefile,该示例直接在原来基础上加了一个helloworld成员
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause)
# 中间过程文件输出到.output/
OUTPUT := .output
CLANG ?= clang
LIBBPF_SRC := $(abspath ../../libbpf/src)
BPFTOOL_SRC := $(abspath ../../bpftool/src)
LIBBPF_OBJ := $(abspath $(OUTPUT)/libbpf.a)
BPFTOOL_OUTPUT ?= $(abspath $(OUTPUT)/bpftool)
BPFTOOL ?= $(BPFTOOL_OUTPUT)/bootstrap/bpftool
...
# 架构里面还有龙芯(国产化)
ARCH ?= $(shell uname -m | sed 's/x86_64/x86/' \
| sed 's/arm.*/arm/' \
| sed 's/aarch64/arm64/' \
| sed 's/ppc64le/powerpc/' \
| sed 's/mips.*/mips/' \
| sed 's/riscv64/riscv/' \
| sed 's/loongarch64/loongarch/')
VMLINUX := ../../vmlinux/$(ARCH)/vmlinux.h
# Use our own libbpf API headers and Linux UAPI headers distributed with
# libbpf to avoid dependency on system-wide headers, which could be missing or
# outdated
# 生成的骨架文件(.skel.h)在.output里,所以-I也包含了$OUTPUT
INCLUDES := -I$(OUTPUT) -I../../libbpf/include/uapi -I$(dir $(VMLINUX)) -I$(LIBBLAZESYM_INC)
# 默认开启了`-g`调试信息,且不加任何`-O`优化便于调试
CFLAGS := -g -Wall
ALL_LDFLAGS := $(LDFLAGS) $(EXTRA_LDFLAGS)
# 在此处新加一个app应用即可,也可以`make minimal`方式构建单个应用
APPS = helloworld minimal minimal_legacy minimal_ns bootstrap uprobe kprobe fentry \
usdt sockfilter tc ksyscall task_iter lsm
...
# Required by libblazesym
ALL_LDFLAGS += -lrt -ldl -lpthread -lm
...
# Build libbpf
# libbpf编译成静态库
$(LIBBPF_OBJ): $(wildcard $(LIBBPF_SRC)/*.[ch] $(LIBBPF_SRC)/Makefile) | $(OUTPUT)/libbpf
$(call msg,LIB,$@)
$(Q)$(MAKE) -C $(LIBBPF_SRC) BUILD_STATIC_ONLY=1 \
OBJDIR=$(dir $@)/libbpf DESTDIR=$(dir $@) \
INCLUDEDIR= LIBDIR= UAPIDIR= \
install
...
# Build BPF code
# 编译BPF侧C语言代码,使用`clang`进行编译。-g -O2,减小bpf.o大小,其会嵌入在最后的bin里
$(OUTPUT)/%.bpf.o: %.bpf.c $(LIBBPF_OBJ) $(wildcard %.h) $(VMLINUX) | $(OUTPUT) $(BPFTOOL)
$(call msg,BPF,$@)
$(Q)$(CLANG) -g -O2 -target bpf -D__TARGET_ARCH_$(ARCH) \
$(INCLUDES) $(CLANG_BPF_SYS_INCLUDES) \
-c $(filter %.c,$^) -o $(patsubst %.bpf.o,%.tmp.bpf.o,$@)
$(Q)$(BPFTOOL) gen object $@ $(patsubst %.bpf.o,%.tmp.bpf.o,$@)
# Generate BPF skeletons
# 用`bpftool gen skeleton`生成BPF骨架头文件(.skel.h)
$(OUTPUT)/%.skel.h: $(OUTPUT)/%.bpf.o | $(OUTPUT) $(BPFTOOL)
$(call msg,GEN-SKEL,$@)
$(Q)$(BPFTOOL) gen skeleton $< > $@
# Build user-space code
# 编译用户空间代码
$(patsubst %,$(OUTPUT)/%.o,$(APPS)): %.o: %.skel.h
$(OUTPUT)/%.o: %.c $(wildcard %.h) | $(OUTPUT)
$(call msg,CC,$@)
$(Q)$(CC) $(CFLAGS) $(INCLUDES) -c $(filter %.c,$^) -o $@
...
# Build application binary
# 最后,使用用户空间的.o 和 libbpf.a (此外需链接-lelf -lz),生成应用bin。不依赖系统的libbpf
$(APPS): %: $(OUTPUT)/%.o $(LIBBPF_OBJ) | $(OUTPUT)
$(call msg,BINARY,$@)
$(Q)$(CC) $(CFLAGS) $^ $(ALL_LDFLAGS) -lelf -lz -o $@
...
3.3.6. 附3:系统tracepoint说明
内核提供的所有tracepoint在/sys/kernel/debug/tracing/下。
当前内核支持的event如下(找了个CentOS Linux release 8.5.2111的环境),可以看到网络相关的tcp/net/skb/sock
1
2
3
4
5
6
7
8
9
10
11
12
13
[root@anonymous ➜ /sys/kernel/debug/tracing/events ]$ ls
alarmtimer context_tracking ftrace iomap mdio page_isolation resctrl syscalls writeback
amdgpu cpuhp gpu_scheduler iommu migrate page_pool rpm task x86_fpu
amdgpu_dm devlink hda irq module pagemap rseq tcp xdp
avc dma_fence hda_controller irq_matrix mptcp percpu rtc thermal xen
block drm hda_intel irq_vectors msr power sched timer xfs
bpf_test_run enable header_event kmem napi printk scsi tlb xhci-hcd
bpf_trace exceptions header_page kvm neigh qdisc signal ucsi
bridge fib huge_memory kvmmmu net random skb udp
cfg80211 fib6 hyperv kyber netlink ras smbus vmscan
cgroup filelock i2c libata nmi raw_syscalls sock vsyscall
clk filemap initcall mac80211 nvme rcu spi wbt
compaction fs_dax intel_iommu mce oom regmap swiotlb workqueue
4. 小结
初步学习eBPF,简单了解了其演变过程,存在的移植性问题及为此推出的CO-RE和BTF技术。
了解了常用的几种开发框架,跟着libbpf-bootstrap练习了一个hello world示例。
准备上手发现离实际开发还有点距离,框架封装了很多信息。下一步带着问题“自底向上”学习,先熟悉下基本eBPF的机制。
5. 参考
1、使用C语言从头开发一个Hello World级别的eBPF程序
3、eBPF 开发实践教程:基于 CO-RE,通过小工具快速上手 eBPF 开发
4、eBPF 入门开发实践教程一:Hello World,基本框架和开发流程
5、Building BPF applications with libbpf-bootstrap
7、BPF 二进制文件:BTF,CO-RE 和 BPF 性能工具的未来【译】
8、GPT