eBPF学习实践系列(四) -- eBPF的各种追踪类型
eBPF追踪类型学习整理
1. 背景
前面涉及了helloworld级别程序的开发流程,本文梳理学习梳理各种追踪机制及使用方式。
并结合BCC和libbpf-bootstrap中的示例进行学习。
几种追踪机制:
- Tracepoints(Kernel Tracepoints),内核预定义跟踪点,跟踪特定事件或操作,是静态定义的
- Kprobes(Kernel Probes),内核探针,运行时动态挂接到内核代码
- Uprobes(User Probes),用户探针,运行时动态挂接到用户空间应用程序
- USDT(User Statically Defined Tracing),用户预定义跟踪点
此外还有不少其他类型,如:
- Socket Filter
- 允许在网络层面对数据包进行过滤和分析。通过编写eBPF程序并附加到网络套接字上,可以实时捕获和分析网络流量,实现如流量分类、性能监控等任务
- Syscall Tracing
- 追踪系统调用的执行情况
“最佳”实践tips:
- 怎么确认 SEC(xxx) -> eBPF类型 的对应关系
- 通过libbpf库中
libbpf.c的struct bpf_sec_def section_defs[]定义查看对应关系
- 通过libbpf库中
- 怎么确认 eBPF类型 -> 上下文结构
- 通过eBPF Docs查看:program types (Linux)
- 上面有该类型是哪个内核版本开始新增的,还有该类型对应的具体上下文结构,以及支持的helper函数、内核侧函数等
- 系统libbpf的include下的bpf.h里可以看到各helper函数功能介绍(linux-5.10.10\include\uapi\linux\bpf.h)
比如SEC(“socket”)对应的类型:
找libbpf.c的section_defs后,发现是BPF_PROG_TYPE_SOCKET_FILTER,然后到eBPF Docs:Program type BPF_PROG_TYPE_SOCKET_FILTER 上展开分类并搜索这个type,上面会有个3.19的内核标签,并给出了其上下文(context)为__sk_buff
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. eBPF程序类型
eBPF 程序通常包含用户态和内核态两部分:用户态程序通过 BPF 系统调用,完成 eBPF 程序的加载、事件挂载以及映射创建和更新,而内核态中的 eBPF 程序则需要通过 BPF 辅助函数完成所需的任务。
并不是所有的辅助函数都可以在 eBPF 程序中随意使用,不同类型的 eBPF 程序所支持的辅助函数是不同的。
在libbpf的include/uapi/linux/bpf.h中,查看bpf_prog_type即可看到类型。
5.10.10内核(LIBBPF_0.2.0)中的类型定义如下,这里多达30种,高版本可能更多。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# linux-5.10.10/tools/include/uapi/linux/bpf.h
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
BPF_PROG_TYPE_CGROUP_DEVICE,
BPF_PROG_TYPE_SK_MSG,
BPF_PROG_TYPE_RAW_TRACEPOINT,
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
BPF_PROG_TYPE_LWT_SEG6LOCAL,
BPF_PROG_TYPE_LIRC_MODE2,
BPF_PROG_TYPE_SK_REUSEPORT,
BPF_PROG_TYPE_FLOW_DISSECTOR,
BPF_PROG_TYPE_CGROUP_SYSCTL,
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
BPF_PROG_TYPE_CGROUP_SOCKOPT,
BPF_PROG_TYPE_TRACING,
BPF_PROG_TYPE_STRUCT_OPS,
BPF_PROG_TYPE_EXT,
BPF_PROG_TYPE_LSM,
BPF_PROG_TYPE_SK_LOOKUP,
};
因为不同内核的版本和编译配置选项不同,一个内核并不会支持所有的程序类型。可以通过 bpftool feature probe | grep program_type 查询当前系统支持的程序类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# CentOS8.5系统
[root@xdlinux ➜ /root ]$ bpftool feature probe | grep program_type
eBPF program_type socket_filter is available
eBPF program_type kprobe is available
eBPF program_type sched_cls is available
eBPF program_type sched_act is available
eBPF program_type tracepoint is available
eBPF program_type xdp is available
eBPF program_type perf_event is available
eBPF program_type cgroup_skb is available
eBPF program_type cgroup_sock is available
eBPF program_type lwt_in is available
eBPF program_type lwt_out is available
eBPF program_type lwt_xmit is available
eBPF program_type sock_ops is available
eBPF program_type sk_skb is available
eBPF program_type cgroup_device is available
eBPF program_type sk_msg is available
eBPF program_type raw_tracepoint is available
eBPF program_type cgroup_sock_addr is available
eBPF program_type lwt_seg6local is available
eBPF program_type lirc_mode2 is NOT available
eBPF program_type sk_reuseport is available
eBPF program_type flow_dissector is available
eBPF program_type cgroup_sysctl is available
eBPF program_type raw_tracepoint_writable is available
eBPF program_type cgroup_sockopt is NOT available
eBPF program_type tracing is NOT available
eBPF program_type struct_ops is available
eBPF program_type ext is NOT available
eBPF program_type lsm is NOT available
eBPF program_type sk_lookup is available
这些类型主要分为下述3大使用场景。主要参考:事件触发:各类eBPF程序的触发机制及其应用场景
2.1. 跟踪类eBPF程序
tracepoint、kprobe、perf_event等,主要用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑。
常见的跟踪类 BPF 程序:
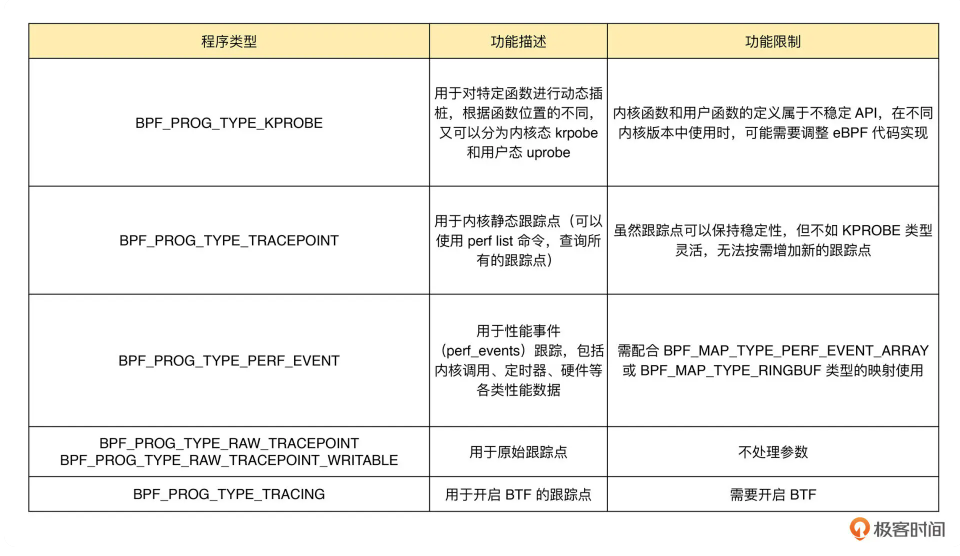
对于内核预定义的tracepoint(BPF_PROG_TYPE_TRACEPOINT),查看eBPF Docs:Program type BPF_PROG_TYPE_TRACEPOINT 后做些说明。
- tracepoint是通过
TRACE_EVENT宏,在内核中预定义的跟踪点,可在内核代码里找到很多使用TRACE_EVENT宏的定义- 比如
TRACE_EVENT(tcp_retransmit_synack, xxx);,linux-5.10.10\include\trace\events\tcp.h
- 比如
- 可以用
tracefs列出所有的tracepoint跟踪点事件,在events目录下- 一般挂载在
/sys/kernel/tracing,mount查看tracefs还会挂载到/sys/kernel/debug/tracing - 目录结构一般以名称中的第一个单词来组织
- 如
tcp_retransmit_synack,在/sys/kernel/tracing/events/tcp/tcp_retransmit_synack下 - 也有稍微不同的,如inet_sock_set_state在events/sock下
- 如
- 一般挂载在
mount过滤tracefs的结果:
1
2
tracefs on /sys/kernel/debug/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
tracefs on /sys/kernel/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
2.2. 网络类eBPF程序
xdp、sock_ops、cgroup_sock_addr、sk_msg等,主要用于对网络数据包进行过滤和处理,进而实现网络的观测、过滤、流量控制以及性能优化等各种丰富的功能。
根据事件触发位置的不同,网络类 eBPF 程序又可以分为 XDP(eXpress Data Path,高速数据路径)程序、TC(Traffic Control,流量控制)程序、套接字程序以及 cgroup 程序
下面分别说明:
XDP程序,类型为BPF_PROG_TYPE_XDP,在网络驱动程序刚刚收到数据包时触发执行。可用来实现高性能的网络处理方案。TC程序,类型为BPF_PROG_TYPE_SCHED_CLS和BPF_PROG_TYPE_SCHED_ACT,分别作为 Linux流量控制 的分类器和执行器。- 套接字程序,用于过滤、观测或重定向套接字网络包,具体的种类也比较丰富。根据类型的不同,套接字 eBPF 程序可以挂载到套接字(socket)、控制组(cgroup)以及网络命名空间(netns)等各个位置。
常见的套接字程序类型:
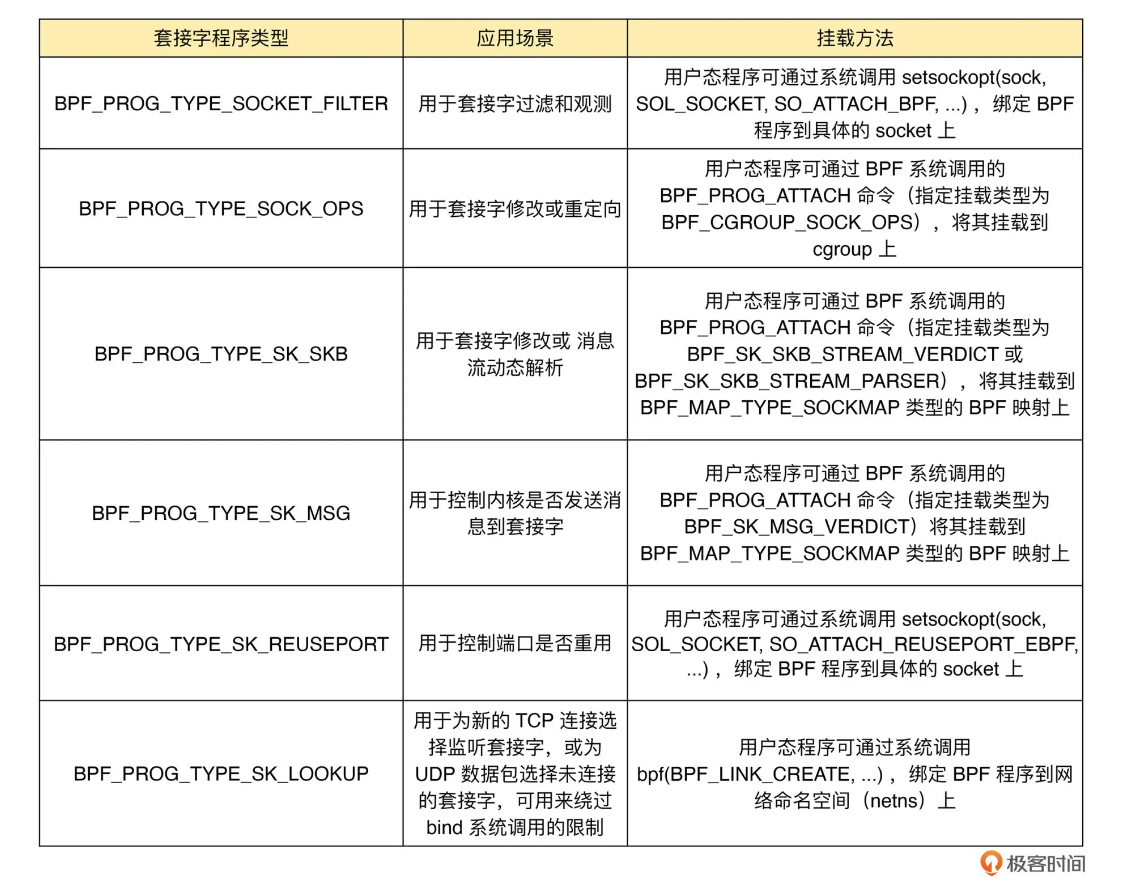
- cgroup程序,用于对cgroup内所有进程的网络过滤、套接字选项以及转发等进行动态控制,它最典型的应用场景是对容器中运行的多个进程进行网络控制。cgroup程序的种类也比较丰富。
这几类网络 eBPF 程序是在不同的事件触发时执行的,因此,在实际应用中我们通常可以把多个类型的 eBPF 程序结合起来,一起使用,来实现复杂的网络控制功能。比如,最流行的 Kubernetes 网络方案 Cilium 就大量使用了 XDP、TC 和套接字 eBPF 程序。
2.3. 安全和其他类eBPF程序
lsm用于安全,其他还有flow_dissector、lwt_in等
示例: 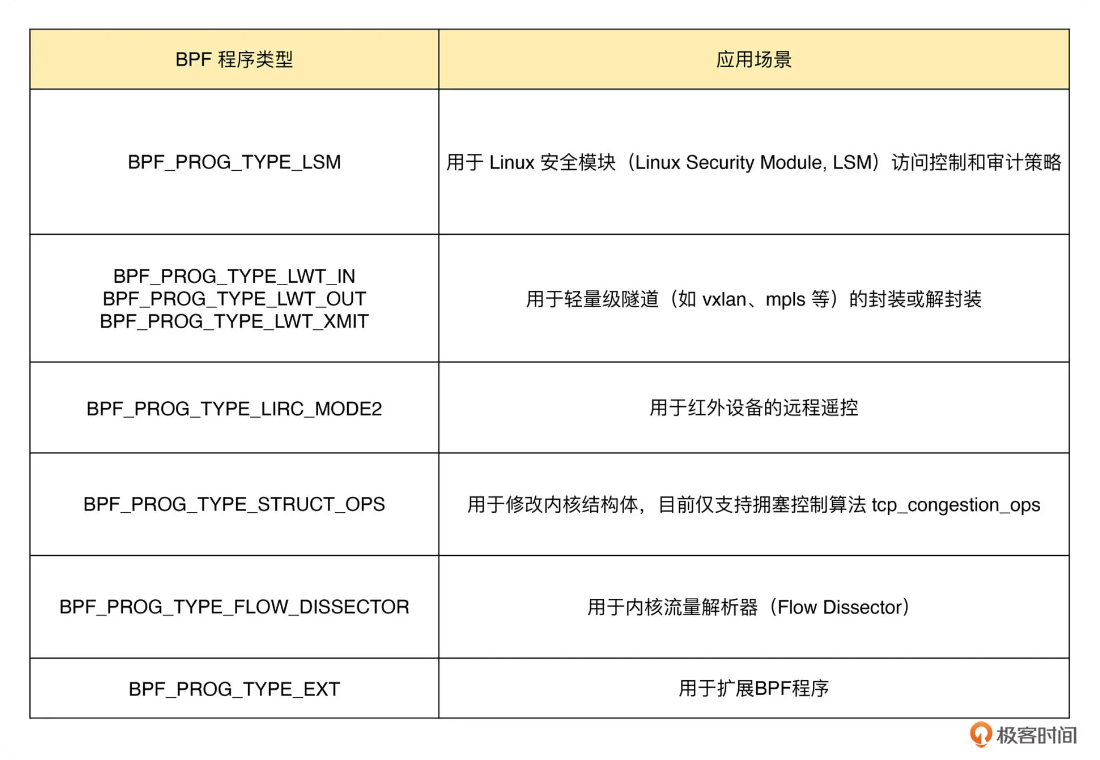
3. SEC(name)对应的eBPF类型
bcc/libbpf-tools/中有很多不同的SEC(xxx)类型,这和上面介绍的30来种enum bpf_prog_type枚举值是怎么对应起来的?
比如下面几个:
SEC("tracepoint/sock/inet_sock_set_state")- bcc/libbpf-tools/tcplife.bpf.c
SEC("kprobe/tcp_v4_connect")、SEC("kretprobe/tcp_v4_connect")- bcc/libbpf-tools/tcptracer.bpf.c
SEC("fentry/tcp_v4_connect")- bcc/libbpf-tools/tcpconnlat.bpf.c
解答:对应关系可通过libbpf库中的libbpf.c中的bpf程序类型定义查看
这是内核中的libbpf.c:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// linux-5.10.10\tools\lib\bpf\libbpf.c
static const struct bpf_sec_def section_defs[] = {
BPF_PROG_SEC("socket", BPF_PROG_TYPE_SOCKET_FILTER),
BPF_PROG_SEC("sk_reuseport", BPF_PROG_TYPE_SK_REUSEPORT),
// SEC_DEF 这个宏会自动拼接BPF_PROG_TYPE_前缀:.prog_type = BPF_PROG_TYPE_##ptype
SEC_DEF("kprobe/", KPROBE,
.attach_fn = attach_kprobe),
BPF_PROG_SEC("uprobe/", BPF_PROG_TYPE_KPROBE),
SEC_DEF("kretprobe/", KPROBE,
.attach_fn = attach_kprobe),
BPF_PROG_SEC("uretprobe/", BPF_PROG_TYPE_KPROBE),
BPF_PROG_SEC("classifier", BPF_PROG_TYPE_SCHED_CLS),
BPF_PROG_SEC("action", BPF_PROG_TYPE_SCHED_ACT),
SEC_DEF("tracepoint/", TRACEPOINT,
.attach_fn = attach_tp),
SEC_DEF("tp/", TRACEPOINT,
.attach_fn = attach_tp),
...
}
对应可知归属eBPF程序类型分别为:
SEC("tracepoint/sock/inet_sock_set_state")- BPF_PROG_TYPE_TRACEPOINT
SEC("kprobe/tcp_v4_connect")、SEC("kretprobe/tcp_v4_connect")- BPF_PROG_TYPE_KPROBE
SEC("fentry/tcp_v4_connect")- BPF_PROG_TYPE_TRACING
这是ibbpf-bootstrap项目中的libbpf.c,展开宏后逻辑一样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// libbpf-bootstrap-master\bpftool\libbpf\src\libbpf.c
static const struct bpf_sec_def section_defs[] = {
// SEC_DEF 这个宏会自动拼接BPF_PROG_TYPE_前缀:.prog_type = BPF_PROG_TYPE_##ptype
SEC_DEF("socket", SOCKET_FILTER, 0, SEC_NONE),
SEC_DEF("sk_reuseport/migrate", SK_REUSEPORT, BPF_SK_REUSEPORT_SELECT_OR_MIGRATE, SEC_ATTACHABLE),
SEC_DEF("sk_reuseport", SK_REUSEPORT, BPF_SK_REUSEPORT_SELECT, SEC_ATTACHABLE),
SEC_DEF("kprobe+", KPROBE, 0, SEC_NONE, attach_kprobe),
SEC_DEF("uprobe+", KPROBE, 0, SEC_NONE, attach_uprobe),
...
SEC_DEF("perf_event", PERF_EVENT, 0, SEC_NONE),
...
SEC_DEF("sk_skb", SK_SKB, 0, SEC_NONE),
...
SEC_DEF("cgroup/setsockopt", CGROUP_SOCKOPT, BPF_CGROUP_SETSOCKOPT, SEC_ATTACHABLE),
SEC_DEF("cgroup/dev", CGROUP_DEVICE, BPF_CGROUP_DEVICE, SEC_ATTACHABLE_OPT),
SEC_DEF("struct_ops+", STRUCT_OPS, 0, SEC_NONE),
SEC_DEF("struct_ops.s+", STRUCT_OPS, 0, SEC_SLEEPABLE),
SEC_DEF("sk_lookup", SK_LOOKUP, BPF_SK_LOOKUP, SEC_ATTACHABLE),
SEC_DEF("netfilter", NETFILTER, BPF_NETFILTER, SEC_NONE),
};
4. 各eBPF类型怎么找对应的插桩点
从前面可以看出来 eBPF 程序本身并不困难,困难的是为其寻找合适的事件源来触发运行。
下面说明eBPF各类型程序怎么找对应的插桩点,为实际开发提供指导。
4.1. 寻找内核的插桩点
对于监控和诊断领域来说,跟踪类 eBPF 程序的事件源包含 3 类:
- 内核函数(kprobe)
- 内核跟踪点(tracepoint)
- 性能事件(perf_event)
4.1.1. 内核中都有哪些内核函数、内核跟踪点或性能事件?
- 使用调试信息获取内核函数、内核跟踪点
查看:/sys/kernel/debug/tracing/events (或/sys/kernel/tracing/events)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[root@xdlinux ➜ /root ]$ ls /sys/kernel/debug/tracing/events
alarmtimer dma_fence header_page kyber oom rpm timer
amdgpu drm huge_memory libata page_isolation rseq tlb
amdgpu_dm enable hyperv mac80211 page_pool rtc ucsi
avc exceptions i2c mce pagemap sched udp
block fib ib_mad mdio percpu scsi vmscan
bpf_test_run fib6 initcall migrate power signal vsyscall
bpf_trace filelock intel_iommu module printk skb wbt
bridge filemap iomap mptcp qdisc smbus workqueue
cfg80211 fs_dax iommu msr random sock writeback
cgroup ftrace irq napi ras spi x86_fpu
clk gpu_scheduler irq_matrix neigh raw_syscalls swiotlb xdp
compaction hda irq_vectors net rcu syscalls xen
context_tracking hda_controller kmem netlink rdma_core task xfs
cpuhp hda_intel kvm nmi regmap tcp xhci-hcd
devlink header_event kvmmmu nvme resctrl thermal
另外,在/sys/kernel/debug/tracing/available_events文件里可以看到汇总
1
2
3
4
5
6
7
8
9
10
11
[root@xdlinux ➜ /sys/kernel/debug/tracing ]$ tail /sys/kernel/debug/tracing/available_events
devlink:devlink_health_report
devlink:devlink_hwerr
devlink:devlink_hwmsg
netlink:netlink_extack
bpf_test_run:bpf_test_finish
fib6:fib6_table_lookup
mptcp:subflow_check_data_avail
mptcp:ack_update_msk
mptcp:get_mapping_status
mptcp:mptcp_subflow_get_send
对于kprobe,只有显式导出的内核函数才可以被eBPF进行动态跟踪:
可以通过 /sys/kernel/tracing/available_filter_functions 或 /proc/kallsyms 查看各内核函数。
- 使用
bpftrace获取内核函数、内核跟踪点
1
2
3
4
5
6
7
8
9
10
# 查询所有内核插桩和跟踪点
sudo bpftrace -l
# 使用通配符查询所有的系统调用跟踪点,也可结合grep过滤
bpftrace -l 'tracepoint:syscalls:*'
# 使用通配符查询所有名字包含"open"的跟踪点
# 使用该方式报错了,可以用grep匹配
# bpftrace -l '*open*'
bpftrace -l | grep open
在自己的测试环境上查看的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 所有跟踪点有很多
[root@xdlinux ➜ /root ]$ bpftrace -l|wc -l
94998
# 通配符查看系统调用跟踪点
[root@xdlinux ➜ /root ]$ bpftrace -l 'tracepoint:syscalls:*' |wc -l
656
[root@xdlinux ➜ /root ]$ bpftrace -l 'tracepoint:syscalls:*' |head -n5
tracepoint:syscalls:sys_enter_accept
tracepoint:syscalls:sys_enter_accept4
tracepoint:syscalls:sys_enter_access
tracepoint:syscalls:sys_enter_acct
tracepoint:syscalls:sys_enter_add_key
# 所有名字包含"open"的跟踪点
[root@xdlinux ➜ /root ]$ bpftrace -l "*open*"
stdin:1:1-7: ERROR: No probe type matched for *open*
*open*
~~~~~~
# 换成grep
[root@xdlinux ➜ /root ]$ bpftrace -l |grep open|head -n5
kfunc:__audit_mq_open
kfunc:__dev_open
kfunc:__ia32_compat_sys_mq_open
kfunc:__ia32_compat_sys_open
kfunc:__ia32_compat_sys_open_by_handle_at
- 使用
perf list获取性能事件
1
2
3
4
5
6
7
8
9
10
11
12
[root@xdlinux ➜ /root ]$ perf list tracepoint
# 执行后会进入下述less界面,可用vim操作进行移动和搜索
List of pre-defined events (to be used in -e):
alarmtimer:alarmtimer_cancel [Tracepoint event]
alarmtimer:alarmtimer_fired [Tracepoint event]
alarmtimer:alarmtimer_start [Tracepoint event]
alarmtimer:alarmtimer_suspend [Tracepoint event]
amdgpu:amdgpu_bo_create [Tracepoint event]
amdgpu:amdgpu_bo_list_set [Tracepoint event]
amdgpu:amdgpu_bo_move [Tracepoint event]
4.1.2. 如何查看内核函数/跟踪点的参数和数据结构?
对于内核函数和内核跟踪点,在需要跟踪它们的传入参数和返回值的时候,该如何查询这些数据结构的定义格式呢?
- 1)使用调试信息获取
以系统调用的sys_enter_openat为例,查看调试信息下的format文件
可看到其数据结构。注意:
- format 列出的字段中,前8个字节对应的字段普通的 ebpf 程序都不能直接访问(部分 bpf helpers 辅助函数可以访问),其他的字段一般都可以访问,具体以 print fmt 中引用的字段为准。
- fmt 这里引用的这些字段都是我们可以在 ebpf 程序中获取的信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[root@xdlinux ➜ /root ]$ cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_openat/format
name: sys_enter_openat
ID: 614
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:int dfd; offset:16; size:8; signed:0;
field:const char * filename; offset:24; size:8; signed:0;
field:int flags; offset:32; size:8; signed:0;
field:umode_t mode; offset:40; size:8; signed:0;
print fmt: "dfd: 0x%08lx, filename: 0x%08lx, flags: 0x%08lx, mode: 0x%08lx", ((unsigned long)(REC->dfd)), ((unsigned long)(REC->filename)), ((unsigned long)(REC->flags)), ((unsigned long)(REC->mode))
对于kprobe,是无法通过上面方式获取参数的,可从内核代码找对应的内核函数。
- 2)使用bpftrace获取
1
2
3
4
5
6
7
8
9
# -l 搜索,-v 附加信息
[root@xdlinux ➜ /root ]$ bpftrace -lv tracepoint:syscalls:sys_enter_openat
tracepoint:syscalls:sys_enter_openat
int __syscall_nr
int dfd
const char * filename
int flags
umode_t mode
[root@xdlinux ➜ /root ]$
4.2. 寻找应用的插桩点
说明:tracepoint和kprobe已经能满足很多eBPF刚需场景了,uprobe、USDT追踪此处作了解,有需要再深入。
4.2.1. 如何查询用户进程的跟踪点?
- 使用
readelf、objdump、nm查询
静态编译语言通过-g编译选项保留调试信息,应用程序二进制会包含 DWARF(Debugging With Attributed Record Format),有了调试信息,可以通过 readelf、objdump、nm 等工具,查询可用于跟踪的函数、变量等符号列表
比如socket编程服务端demo(g++ server.cpp -g -o server):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# readelf - Displays information about ELF files.
# 查询符号表
# -s --syms/--symbols Display the symbol table
[root@xdlinux ➜ /home/workspace/prog-playground/network/tcp_connect git:(main) ✗ ]$ readelf -s server|head -n10
Symbol table '.dynsym' contains 20 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FUNC GLOBAL DEFAULT UND htons@GLIBC_2.2.5 (2)
2: 0000000000000000 0 FUNC GLOBAL DEFAULT UND bind@GLIBC_2.2.5 (2)
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND socket@GLIBC_2.2.5 (2)
4: 0000000000000000 0 FUNC GLOBAL DEFAULT UND sleep@GLIBC_2.2.5 (2)
5: 0000000000000000 0 FUNC GLOBAL DEFAULT UND perror@GLIBC_2.2.5 (2)
6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __cxa_atexit@GLIBC_2.2.5 (2)
# 查询USDT信息
# -n --notes Display the core notes (if present)
[root@xdlinux ➜ /home/workspace/prog-playground/network/tcp_connect git:(main) ✗ ]$ readelf -n server
Displaying notes found in: .note.ABI-tag
Owner Data size Description
GNU 0x00000010 NT_GNU_ABI_TAG (ABI version tag)
OS: Linux, ABI: 3.2.0
...
Displaying notes found in: .gnu.build.attributes
Owner Data size Description
GA$<version>3p965 0x00000010 OPEN
Applies to region from 0x4009bf to 0x4009bf (.annobin_init.c)
GA$<tool>running gcc 0x00000000 OPEN
...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# objdump - display information from object files.
# -t, --syms Display the contents of the symbol table(s)
[root@xdlinux ➜ /home/workspace/prog-playground/network/tcp_connect git:(main) ✗ ]$ objdump -t server
server: file format elf64-x86-64
SYMBOL TABLE:
0000000000400238 l d .interp 0000000000000000 .interp
0000000000400254 l d .note.ABI-tag 0000000000000000 .note.ABI-tag
0000000000400274 l d .note.gnu.build-id 0000000000000000 .note.gnu.build-id
0000000000400298 l d .gnu.hash 0000000000000000 .gnu.hash
00000000004002c8 l d .dynsym 0000000000000000 .dynsym
...
1
2
3
4
5
6
7
8
9
10
11
12
13
# nm - list symbols from object files
# -a, --debug-syms Display debugger-only symbols
[root@xdlinux ➜ /home/workspace/prog-playground/network/tcp_connect git:(main) ✗ ]$ nm -a server
0000000000000000 a
0000000000400c35 t .annobin___libc_csu_fini.end
0000000000400c25 t .annobin___libc_csu_fini.start
...
0000000000400878 T _init
0000000000400990 T _start
U bind@@GLIBC_2.2.5
00000000006021b0 b completed.7294
...
- 使用bpftrace查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 还是上面编译出来的 server bin程序
# 查询uprobe
[root@xdlinux ➜ tcp_connect git:(main) ✗ ]$ bpftrace -l 'uprobe:server:*'
uprobe:server:_GLOBAL__sub_I_main
uprobe:server:_Z41__static_initialization_and_destruction_0ii
uprobe:server:_ZNSt8ios_base4InitD1Ev
uprobe:server:_ZNSt8ios_base4InitD1Ev@@GLIBCXX_3.4
uprobe:server:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
uprobe:server:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_@@GLIBCXX_3.4
uprobe:server:__do_global_dtors_aux
uprobe:server:__libc_csu_fini
uprobe:server:__libc_csu_init
uprobe:server:_dl_relocate_static_pie
uprobe:server:_fini
uprobe:server:_init
uprobe:server:_start
uprobe:server:deregister_tm_clones
uprobe:server:frame_dummy
uprobe:server:main
uprobe:server:register_tm_clones
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 查看USDT
# server程序里没有
[root@xdlinux ➜ tcp_connect git:(main) ✗ ]$ bpftrace -l 'usdt:server:*'
ERROR: failed to initialize usdt context for path server
# 查看 libc.so.6 库为例
[root@xdlinux ➜ tcp_connect git:(main) ✗ ]$ bpftrace -l 'usdt:/lib64/libc.so.6:*'
usdt:/lib64/libc.so.6:libc:lll_lock_wait_private
usdt:/lib64/libc.so.6:libc:longjmp
usdt:/lib64/libc.so.6:libc:longjmp_target
usdt:/lib64/libc.so.6:libc:memory_arena_new
usdt:/lib64/libc.so.6:libc:memory_arena_retry
usdt:/lib64/libc.so.6:libc:memory_arena_reuse
usdt:/lib64/libc.so.6:libc:memory_arena_reuse_free_list
...
5. tracepoint追踪实践
通过上面的学习,已经差不多可以知道怎么查看常见追踪类型了
本小节以tracepoint(对应类型为:BPF_PROG_TYPE_TRACEPOINT)类型的eBPF为例,来看下实践中具体如何使用
5.1. 确定需要追踪的 tracepoint 事件
场景:
假设,我们想通过 tracepoint 追踪 chmod 这个命令涉及的 fchmodat 系统调用, 那么,如何确定ebpf 中事件处理函数的参数类型,以及如何获取到对应的 fchmodat 这个系统调用涉及的参数的内容, 比如拿到操作文件名称以及操作的权限 mode 的值。
1、先确定 chmod 所使用的系统调用
比如通过strace
1
2
3
4
5
[root@xdlinux ➜ workspace ]$ strace chmod +x minimal
execve("/usr/bin/chmod", ["chmod", "+x", "minimal"], 0x7fffef2662f0 /* 41 vars */) = 0
...
fchmodat(AT_FDCWD, "minimal", 0755) = 0
...
2、找到针对这个系统调用可用的 tracepoint 事件
在/sys/kernel/debug/tracing/available_events中查找
1
2
3
[root@xdlinux ➜ tracing ]$ cat /sys/kernel/debug/tracing/available_events |grep fchmodat
syscalls:sys_exit_fchmodat
syscalls:sys_enter_fchmodat
或者通过 bpftrace 查找:
1
2
3
[root@xdlinux ➜ tracing ]$ bpftrace -l 'tracepoint:*' |grep fchmodat
tracepoint:syscalls:sys_enter_fchmodat
tracepoint:syscalls:sys_exit_fchmodat
5.2. 确定事件包含的信息
通过查看 /sys/kernel/tracing/events/syscalls/xxx/format,其中sys_enter_xxx对应输入参数、sys_exit_xxx对应输出参数
(若是其他类型,可以到eBPF Docs上去查找对应的上下文结构)
此处以跟踪sys_enter_fchmodat为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 输入参数
# 如前所述,前8个字节对应的字段普通的eBPF程序一般不能直接访问
[root@xdlinux ➜ tracing ]$ cat /sys/kernel/tracing/events/syscalls/sys_enter_fchmodat/format
name: sys_enter_fchmodat
ID: 628
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:int dfd; offset:16; size:8; signed:0;
field:const char * filename; offset:24; size:8; signed:0;
field:umode_t mode; offset:32; size:8; signed:0;
print fmt: "dfd: 0x%08lx, filename: 0x%08lx, mode: 0x%08lx", ((unsigned long)(REC->dfd)), ((unsigned long)(REC->filename)), ((unsigned long)(REC->mode))
# 返回值/输出参数,即返回值为 long ret
[root@xdlinux ➜ bcc git:(v0.19.0) ✗ ]$ cat /sys/kernel/tracing/events/syscalls/sys_exit_fchmodat/format
name: sys_exit_fchmodat
ID: 627
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:long ret; offset:16; size:8; signed:1;
print fmt: "0x%lx", REC->ret
或者 bpftrace 方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
# 输入参数
[root@xdlinux ➜ tracing ]$ bpftrace -lv 'tracepoint:syscalls:sys_enter_fchmodat'
tracepoint:syscalls:sys_enter_fchmodat
int __syscall_nr
int dfd
const char * filename
umode_t mode
# 返回值/输出参数
[root@xdlinux ➜ bcc git:(v0.19.0) ✗ ]$ bpftrace -lv 'tracepoint:syscalls:sys_exit_fchmodat'
tracepoint:syscalls:sys_exit_fchmodat
int __syscall_nr
long ret
从上面可以看到,我们可以获取 sys_enter_fchmodat 事件的 dfd 、filename 以及 mode 信息
5.3. 确定事件处理函数的参数
上述小节知道了事件本身可以提供的信息后,我们还需要知道如何在eBPF程序中读取这些信息。
这涉及到eBPF事件处理函数的输入参数。可通过如下方式获取:
5.3.1. 方法1:基于vmlinux.h
对于tracepoint,比较好确定,在vmlinux.h中按tracepoint点查找:
sys_enter_xx对应trace_event_raw_sys_enter- 对于
sys_enter_fchmodat,对应struct trace_event_raw_sys_enter。
- 对于
sys_exit_xx对应trace_event_raw_sys_exit- 其他的tracepoint一般对应
trace_event_raw_<name>,如果没找到的话,可以参考 trace_event_raw_sys_enter 的例子找它相近的 struct- 比如追踪点
tcp:tcp_retransmit_synack,搜索可以找到:struct trace_event_raw_tcp_retransmit_synack - 即
trace_event_raw_xxx形式
- 比如追踪点
不同内核可能有差异,也可以生成当前内核匹配的vmlinux.h文件:bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
这里查看bcc项目里的vmlinux.h(不同内核版本vmlinux.h有所差异,这就体现出libbpf CO-RE的优势了)
1
2
3
4
[root@xdlinux ➜ bcc git:(v0.19.0) ✗ ]$ find . -name vmlinux.h
./libbpf-tools/powerpc/vmlinux.h
./libbpf-tools/x86/vmlinux.h
./libbpf-tools/arm64/vmlinux.h
1
2
3
4
5
6
7
// bcc/libbpf-tools/x86/vmlinux.h
struct trace_event_raw_sys_enter {
struct trace_entry ent;
long int id;
long unsigned int args[6];
char __data[0];
};
其中 args 中就存储了事件相关的我们可以获取的信息,即上述中format文件的fmt里包含的字段。
因此,我们可以通过 args[0] 获取dfd,args[1] 获取 filename,以此类推。
使用方式示例:
(完整代码可见原作者的 github仓库)
1
2
3
4
5
6
7
8
9
10
SEC("tracepoint/syscalls/sys_enter_fchmodat")
// 函数名可以自定义,入参跟eBPF追踪类型结构一致
int tracepoint__syscalls__sys_enter_fchmodat(struct trace_event_raw_sys_enter *ctx)
{
// ...
char *filename_ptr = (char *) BPF_CORE_READ(ctx, args[1]);
bpf_core_read_user_str(&event->filename, sizeof(event->filename), filename_ptr);
event->mode = BPF_CORE_READ(ctx, args[2]);
// ...
}
5.3.2. 方法2:手动构造参数结构体
除了使用 vmlinux.h 中预定义的结构体外,我们还可以基于上述 format 文件的内容自定义一个结构体来作为eBPF程序的参数。
对于上面的sys_enter_fchmodat/format:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[root@xdlinux ➜ tracing ]$ cat /sys/kernel/tracing/events/syscalls/sys_enter_fchmodat/format
name: sys_enter_fchmodat
ID: 628
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:int dfd; offset:16; size:8; signed:0;
field:const char * filename; offset:24; size:8; signed:0;
field:umode_t mode; offset:32; size:8; signed:0;
print fmt: "dfd: 0x%08lx, filename: 0x%08lx, mode: 0x%08lx", ((unsigned long)(REC->dfd)), ((unsigned long)(REC->filename)), ((unsigned long)(REC->mode))
自定义如下结构:只需保证各字段偏移和上述format说明一致。
1
2
3
4
5
6
7
8
9
10
11
struct sys_enter_fchmodat_args {
// 前16个字节的内容,对应的是 format 文件中 dfd 之前的所有字段,根据dfd对应的`offset:16`可知道其偏移
// 不确定时建议还是按format结果定义相应类型的字段
char _[16];
// linux 64位机器上,long一般是8字节 (32位linux和windows机器则不同,此处不管)
long dfd;
// 指针 8字节
long filename_ptr;
// 8字节
long mode;
};
使用方式相应调整:
1
2
3
4
5
6
7
8
SEC("tracepoint/syscalls/sys_enter_fchmodat")
int tracepoint__syscalls__sys_enter_fchmodat(struct sys_enter_fchmodat_args *ctx) {
// ...
char *filename_ptr = (char *)ctx->filename_ptr;
bpf_core_read_user_str(&event->filename, sizeof(event->filename), filename_ptr);
event->mode = (u32)ctx->mode;
// ...
}
5.3.3. 其他eBPF类型
上面重点展示了tracepoint对应的的BPF_PROG_TYPE_TRACEPOINT类型的实践方式,其他类型的eBPF程序,如篇头所述可以查询eBPF Docs:program types (Linux)
6. SEC(name)对应的处理函数定义说明
很多人(包括我自己)一开始很容易迷惑,到底该以什么规则定义处理函数?输入参数又是怎么样的?下面进行说明。
从bcc/libbpf-bootstrap等项目里可以看到好几种不同的处理函数定义。比如下面列举的几种:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// bcc/libbpf-tools/opensnoop.bpf.c
SEC("tracepoint/syscalls/sys_enter_open")
int tracepoint__syscalls__sys_enter_open(struct trace_event_raw_sys_enter* ctx){xxx}
// bcc/libbpf-tools/runqslower.bpf.c
SEC("tp_btf/sched_wakeup")
int handle__sched_wakeup(u64 *ctx){xxx}
// bcc/libbpf-tools/syscount.bpf.c
SEC("tracepoint/raw_syscalls/sys_enter")
int sys_enter(struct trace_event_raw_sys_enter *args)
// bcc/libbpf-tools/numamove.bpf.c
SEC("fexit/migrate_misplaced_page")
int BPF_PROG(migrate_misplaced_page_exit){xxx}
// bcc/libbpf-tools/tcpconnect.bpf.c
SEC("kprobe/tcp_v4_connect")
int BPF_KPROBE(tcp_v4_connect, struct sock *sk){xxx}
SEC("kretprobe/tcp_v4_connect")
int BPF_KRETPROBE(tcp_v4_connect_ret, int ret)
// libbpf-bootstrap/examples/c/uprobe.bpf.c
SEC("uretprobe")
int BPF_KRETPROBE(uretprobe_add, int ret){xxx}
// libbpf-bootstrap/examples/c/sockfilter.bpf.c
SEC("socket")
int socket_handler(struct __sk_buff *skb){xxx}
函数名可以自定义,比如上面的tracepoint__syscalls__sys_enter_open、handle__sched_wakeup、sys_enter,不需要跟SEC(xxx)里面的xxx有严格的绑定关系,保持一定的可读性即可。
也可借助eBPF宏来简化和标准化不同类型eBPF程序的定义。这里的宏只是再包装了一下上面的自定义函数。
上面有3个宏:BPF_PROG、BPF_KPROBE、BPF_KRETPROBE,都是比较常用的,下面单独说明。
6.1. BPF_PROG 宏
BPF_PROG 宏用于定义一个通用的 eBPF 程序,该宏是最基础的宏,可以适用于不同类型的 eBPF 程序,根据定义的上下文和用途的不同,其作用也不同。其签名通常会根据具体的 eBPF 程序类型来适配。
此宏的作用是定义一个 eBPF 程序,参数是一个 eBPF 上下文对象(例如 struct __sk_buff 代表网络数据包的上下文)。
示例:
1
2
3
4
5
6
7
8
9
10
// 宏定义(部分内容)
#define BPF_PROG(name, ... ) \
int name(struct __sk_buff *ctx, ##__VA_ARGS__)
// 用法,比如上面的 BPF_PROG(migrate_misplaced_page_exit){xxx}
BPF_PROG(my_prog_name)
{
// Your eBPF program logic here
return 0;
}
我们看下BPF_PROG在内核中的定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// linux-5.10.10/tools/lib/bpf/bpf_tracing.h
/*
* BPF_PROG is a convenience wrapper for generic tp_btf/fentry/fexit and
* similar kinds of BPF programs, that accept input arguments as a single
* pointer to untyped u64 array, where each u64 can actually be a typed
* pointer or integer of different size. Instead of requring user to write
* manual casts and work with array elements by index, BPF_PROG macro
* allows user to declare a list of named and typed input arguments in the
* same syntax as for normal C function. All the casting is hidden and
* performed transparently, while user code can just assume working with
* function arguments of specified type and name.
*
* Original raw context argument is preserved as well as 'ctx' argument.
* This is useful when using BPF helpers that expect original context
* as one of the parameters (e.g., for bpf_perf_event_output()).
*/
#define BPF_PROG(name, args...) \
name(unsigned long long *ctx); \
static __attribute__((always_inline)) typeof(name(0)) \
____##name(unsigned long long *ctx, ##args); \
typeof(name(0)) name(unsigned long long *ctx) \
{ \
_Pragma("GCC diagnostic push") \
_Pragma("GCC diagnostic ignored \"-Wint-conversion\"") \
return ____##name(___bpf_ctx_cast(args)); \
_Pragma("GCC diagnostic pop") \
} \
...
手动改下本地代码看下宏展开的样子。
修改:/home/workspace/bcc/libbpf-tools/tcpconnect.bpf.c
1
2
3
4
5
6
7
8
9
10
SEC("kprobe/tcp_v4_connect")
//int BPF_KPROBE(tcp_v4_connect, struct sock *sk)
//{
// return enter_tcp_connect(ctx, sk);
//}
// 函数改成 tcp_v4_connect_test,便于检索,此处也可说明处理函数是可以自定义的
int BPF_KPROBE(tcp_v4_connect_test, struct sock *sk)
{
return enter_tcp_connect(ctx, sk);
}
在Makefile里临时加一个-E预编译规则
1
2
3
4
5
6
7
8
9
10
11
12
# /home/workspace/bcc/libbpf-tools/Makefile
$(OUTPUT)/%.bpf.o: %.bpf.c $(LIBBPF_OBJ) $(wildcard %.h) $(ARCH)/vmlinux.h | $(OUTPUT)
$(call msg,BPF,$@)
$(Q)$(CLANG) -g -O2 -target bpf -D__TARGET_ARCH_$(ARCH) \
-I$(ARCH)/ $(INCLUDES) -c $(filter %.c,$^) -o $@ && \
$(LLVM_STRIP) -g $@
# 临时新增begin 生成预编译文件
$(call msg,xxxxxxxxxxxxxx, 000tcpconnect.bpf.i)
$(Q)$(CLANG) -g -O2 -target bpf -D__TARGET_ARCH_$(ARCH) \
-I$(ARCH)/ $(INCLUDES) -E $(filter %.c,$^) -o tcpconnect.bpf.i && \
$(LLVM_STRIP) -g $@
# 临时新增end 生成预编译文件
进行编译
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[root@xdlinux ➜ libbpf-tools git:(v0.19.0) ✗ ]$ make clean; make tcpconnect
CLEAN
MKDIR .output
MKDIR libbpf
LIB libbpf.a
MKDIR staticobjs
CC bpf.o
...
INSTALL libbpf.a
BPF tcpconnect.bpf.o
# 生成预编译文件
xxxxxxxxxxxxxx 000tcpconnect.bpf.i
GEN-SKEL tcpconnect.skel.h
CC tcpconnect.o
...
BINARY tcpconnect
预编译文件tcpconnect.bpf.i,上面改的tcp_v4_connect_test,BPF_KPROBE宏展开后如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// /home/workspace/bcc/libbpf-tools/tcpconnect.bpf.i
int tcp_v4_connect_test(struct pt_regs *ctx); static __attribute__((always_inline)) typeof(tcp_v4_connect_test(0)) ____tcp_v4_connect_test(struct pt_regs *ctx, struct sock *sk); typeof(tcp_v4_connect_test(0)) tcp_v4_connect_test(struct pt_regs *ctx) {
# 213 "tcpconnect.bpf.c"
#pragma GCC diagnostic push
# 213 "tcpconnect.bpf.c"
#pragma GCC diagnostic ignored "-Wint-conversion"
# 213 "tcpconnect.bpf.c"
return ____tcp_v4_connect_test(ctx, (void *)((ctx)->di));
# 213 "tcpconnect.bpf.c"
#pragma GCC diagnostic pop
# 213 "tcpconnect.bpf.c"
} static __attribute__((always_inline)) typeof(tcp_v4_connect_test(0)) ____tcp_v4_connect_test(struct pt_regs *ctx, struct sock *sk)
{
return enter_tcp_connect(ctx, sk);
}
6.2. BPF_KPROBE 宏
BPF_KPROBE 宏用于定义基于 kprobe(内核探针)的 eBPF 程序,它用于探测内核函数的入口点。在 kprobe 上设置的 eBPF 程序能够在内核函数被调用时执行。
其通常的定义方式是:
1
2
#define BPF_KPROBE(func, ...) \
int func(struct pt_regs *ctx, ##__VA_ARGS__)
示例:
1
2
3
4
5
6
SEC("kprobe/tcp_v6_connect")
int BPF_KPROBE(tcp_v6_connect, struct sock *sk)
{
// Your kprobe logic here
return 0;
}
此宏的作用是定义一个 kprobe 钩子函数,并传入内核函数的参数,ctx 是上下文信息,其他参数是内核函数的实际参数。
6.3. BPF_KRETPROBE 宏
BPF_KRETPROBE 宏用于定义基于 kretprobe(返回探针)的 eBPF 程序,它用于探测内核函数的返回点。在 kretprobe 上设置的 eBPF 程序能够在内核函数执行完成并返回时执行。
其通常的定义方式是:
1
2
#define BPF_KRETPROBE(func) \
int func(struct pt_regs *ctx)
示例:
1
2
3
4
5
6
SEC("kretprobe/tcp_v6_connect")
int BPF_KRETPROBE(tcp_v6_connect)
{
// Your kretprobe logic here
return 0;
}
此宏的作用是定义一个 kretprobe 钩子函数,只有一个参数 ctx,它代表了捕获的寄存器上下文,因为在函数返回点时,我们没有其他函数参数可以获取。
6.4. 参数说明
上面小节我们知道SEC(xxx)对应的eBPF类型后,可以到eBPF Docs上去查找对应的上下文结构。
7. 小结
学习梳理了eBPF各程序类型,查找追踪点的方法,进行追踪的实践套路。
下一步应该可以按需开始上手了。
8. 参考
3、ebpf/libbpf 程序使用 tracepoint 的常见问题
4、eBPF Docs:program types (Linux)
5、BPF 进阶笔记(一):BPF 程序(BPF Prog)类型详解:使用场景、函数签名、执行位置及程序示例
6、GPT