ollama搭建本地个人知识库
ollama搭建本地个人知识库
1. 背景
大模型发展如火如荼,前段时间也打算后面建立自己的知识库,一直没行动。
由于一些因素实在忍受不了了:
- 近期工作上碰到好几次找之前笔记没找到,明明记得之前记过就是找不到
- 而且以前的一些笔记很多都不会去看,看了几个反而不如GPT清晰,不用起来以后更不会看了
- 本地笔记用markdown记录,然后全局搜索关键词,需要精确匹配到key,自然语言理解能互补一下
网上资料很多,找了一篇参考: 利用AI解读本地TXT、WORD、PDF文档
基于ollama搭建,结构如下:
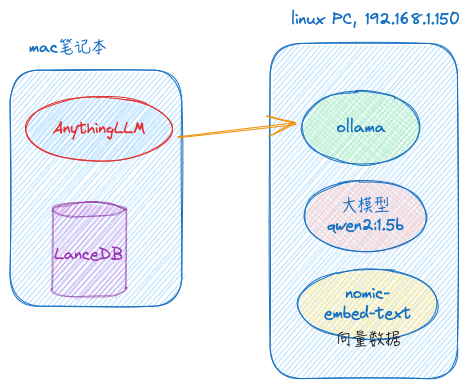
最后:笔记本“本地”也安装ollama并下载模型
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 安装ollama
1、从ollama官网下载ollama:
curl -fsSL https://ollama.com/install.sh | sh
除了ollama,里面还会自动判断GPU类型并安装依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[root@xdlinux ➜ /root ]$ curl -fsSL https://ollama.com/install.sh | sh
>>> Downloading ollama...
######################################################################## 100.0%#=#=-# # ######################################################################## 100.0%
>>> Installing ollama to /usr/local/bin...
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> Downloading AMD GPU dependencies...
######################################################################## 100.0%##O=# # ######################################################################## 100.0%
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
>>> AMD GPU ready.
安装后自动起了服务:
1
2
3
[root@xdlinux ➜ /root ]$ netstat -anp|grep 11434
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 23636/ollama
[root@xdlinux ➜ /root ]$
配置局域网内访问:
.zshrc里添加, 失败export OLLAMA_HOST=0.0.0.0:11434,然后重启服务,貌似没用
1
2
3
4
5
[root@xdlinux ➜ /root ]$ service ollama restart
Redirecting to /bin/systemctl restart ollama.service
[root@xdlinux ➜ /root ]$ netstat -anp|grep 11434
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 23878/ollama
[root@xdlinux ➜ /root ]$
在unit文件里设置环境变量OLLAMA_HOST=0.0.0.0:11434,每个环境变量各自一行(成功)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
[root@xdlinux ➜ /root ]$ systemctl cat ollama.service
# /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
...
# 在/etc/systemd/system/ollama.service
[root@xdlinux ➜ /root ]$ vim /etc/systemd/system/ollama.service
[root@xdlinux ➜ /root ]$ cat /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/root/.autojump/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
[root@xdlinux ➜ /root ]$
重新加载systemd配置并重启服务
1
2
3
4
[root@xdlinux ➜ /root ]$ systemctl daemon-reload
[root@xdlinux ➜ /root ]$ systemctl restart ollama.service
[root@xdlinux ➜ /root ]$ netstat -anp|grep 11434
tcp6 0 0 :::11434 :::* LISTEN 24573/ollama
好了,浏览器输入:http://192.168.1.150:11434/,可以访问了。提示“Ollama is running”
3. 下载模型并使用
到Ollama官网,点击右上角的Models即进入:ollama library。Ollama支持流行的开源大语言模型,包括llama2和它的众多衍生品。
暂时使用阿里的通义千问:qwen2 1.5b 实验。
复制网页提示的命令,此处为ollama run qwen2:1.5b,到linux终端运行。也可以分两步:ollama pull qwen2:1.5b再ollama run qwen2:1.5b
1
2
3
4
5
6
7
[root@xdlinux ➜ /root ]$ ollama run qwen2:1.5b
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling 405b56374e02... 81% ▕█████████████████████████ ▏ 760 MB/934 MB 36 KB/s 1h19m
...
结束后会出来交互式界面,跟平时用GPT一样问答。后续也可用ollama run qwen2:1.5b调出来命令行界面。试了下效果本地还挺快的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[root@xdlinux ➜ /root ]$ ollama run qwen2:1.5b
>>> 怎么用大模型搭建个人知识库
使用大型语言模型(如:通义千问、小冰等)来构建自己的知识库,可以分为以下几个步骤:
1. **确定主题范围**:
- 明确你的目标知识领域。如果是技能学习或专业领域,则可以选择相关的书籍、文章和视频内容作
为参考。
- 可以根据个人兴趣爱好选择广泛的主题,比如历史、文学、编程语言等。
2. **收集资源**:
...
# 输入 /bye 结束
>>> /bye
[root@xdlinux ➜ /root ]$
可以用ollama list查看当前已下载的模型:
1
2
3
4
[root@xdlinux ➜ /root ]$ ollama list
NAME ID SIZE MODIFIED
qwen2:1.5b f6daf2b25194 934 MB 4 minutes ago
qwen2:0.5b 6f48b936a09f 352 MB 5 minutes ago
其他用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
[root@xdlinux ➜ /root ]$ ollama -h
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
4. 下载向量模型
向量模型是用来将Word和PDF文档转化成向量数据库的工具。通过向量模型转换之后,我们的大语言模型就可以更高效地理解文档内容。
在这里我们使用 nomic-embed-text
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[root@xdlinux ➜ /root ]$ ollama pull nomic-embed-text
pulling manifest
pulling 970aa74c0a90... 100% ▕███████████████████████████████▏ 274 MB
pulling c71d239df917... 100% ▕███████████████████████████████▏ 11 KB
pulling ce4a164fc046... 100% ▕███████████████████████████████▏ 17 B
pulling 31df23ea7daa... 100% ▕███████████████████████████████▏ 420 B
verifying sha256 digest
writing manifest
removing any unused layers
success
[root@xdlinux ➜ /root ]$ ollama list
NAME ID SIZE MODIFIED
nomic-embed-text:latest 0a109f422b47 274 MB 47 seconds ago
qwen2:1.5b f6daf2b25194 934 MB 17 minutes ago
qwen2:0.5b 6f48b936a09f 352 MB 18 minutes ago
[root@xdlinux ➜ /root ]$
5. 利用Langchain处理文档
Langchain是一套利用大语言模型处理向量数据的工具。以前,搭建LLM+Langchain的运行环境比较复杂。现在我们使用AnythingLLM可以非常方便的完成这个过程,因为AnythingLLM已经内置了Langchain组件。
AnythingLLM是一个集成度非常高的大语言模型整合包。它包括了图形化对话界面、内置大语言模型、内置语音识别模型、内置向量模型、内置向量数据库、内置图形分析库。
可惜的是,AnythingLLM目前的易用性和稳定性仍有所欠缺。因此,在本教程中,我们仅使用AnythingLLM的向量数据库和对话界面。LLM模型和向量模型仍然委托给Ollama来管理
AnythingLLM本身对Ollama的支持也非常完善。只需要通过图形界面,点击几下鼠标,我们就可以轻松完成配置。
下载Mac端程序(300MB左右),安装后进行配置。
5.1. 配置LLM
1、按提示进行必要设置,设置工作空间名
2、进入workspace后,左下角有配置按钮,选择LLM Preference选项卡
3、在LLM Provider的下拉中,选择Ollama,并进行配置后保存
- Ollama Base URL:
http://192.168.1.150:11434 - Chat Model Selection:
qwen2:1.5b - Token context window:
8192
5.2. 配置embedding模式
1、选择Embedding Preference选项卡
2、在Embedding Provider下拉中,选择Ollama,进行配置后保存
- Ollama Base URL:
http://192.168.1.150:11434 - Embedding Model Selection:
nomic-embed-text:latest - Max embedding chunk length:
512
注意:这个Max embedding chunk length数值会影响文档回答的质量,推荐设置成128-512中的某个数值。
从512往下逐级降低,测试效果。太低也不好,对电脑性能消耗大。
5.3. 选择LanceDB向量数据库
1、选择Vector Database选项卡
2、在Vector Database Provider下拉中,选择LanceDB作为后端。这是一个内置的向量数据库。
6. 使用AnythingLLM上传文档和问答
1、基本问答:可以直接开始问答
感觉效果有点差,内容和速度都不好,应该是哪里配置还要优化下。
直接使用命令行效果还不错。
2、上传文档
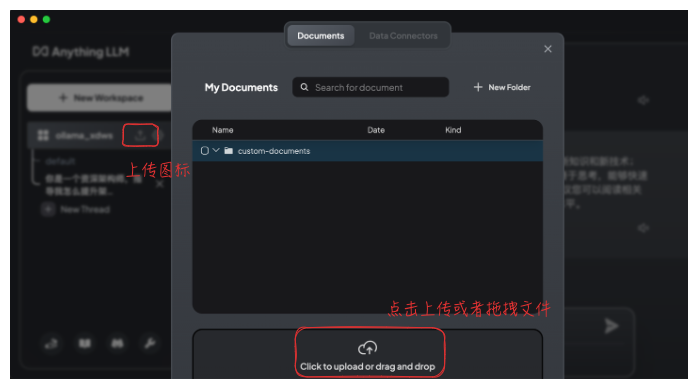
上传完成后,选中相应的文档,并点击 Move to Workspcae,然后点击 Save and Embed。
使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Q:提炼文档里的网络知识
A:根据提供的文档内容,我们可以总结出以下关于网络的知识点:
1. 网络性能的实现:文档提到了如何实现网络性能,包括使用Nginx等服务器程序来提高网络性能。Nginx是一个流行的HTTP和反向代理Web服务器软件。
2. TCP/IP协议:文档中提到了TCP/IP协议,这是一个广泛使用的通信协议,用于在网络之间传输数据包。
3. 网络管理:文档还涉及了系统级别的网络配置、监控以及性能优化等方面的知识。例如,提供了如何设置安全限制(如fs.file-max和sysctl)的示例。
4. 网络接口和地址:文档也提到了网络接口(如eth0, wlan0等)及其对应的IP地址。这通常用于网络设备上配置特定端口或接口的通信服务。
5. 服务器进程:文档中提到如何使用epoll来提高Nginx处理并发请求的能力,这可能涉及如何在多线程环境中管理事件和资源。
6. 网络编程和异步编程:文档提到了异步编程的概念,例如通过epoll_wait函数进行网络事件的实时处理。异步编程通常用于提高效率和减少系统阻塞现象。
7. 模块化开发:文档中还涉及了模块化的编码实践,即在代码中分组不同的功能,并使用类或对象来组织这些功能。这有助于提高代码的可读性、复用性和扩展性。
8. 网络测试和监控:文档中的部分内容可能涉及到网络测试工具(如Wireshark)的使用,以及如何通过监控系统性能指标(如CPU使用率、内存使用情况等)来发现潜在的问题。这些知识对于确保系统的稳定运行非常重要。
点击下面的 Show Citations,可以看到引用的文档。
1
2
Hide Citations
理解了实现再谈网络性能_202202更新.pdf
切换为Query模式(不过上面没切换也能参考到文档):
点击齿轮图标,打开对应workspace的设置选项。选择Chat Settings,将对话模式更改为Query(默认是Chat)
Query模式能够确保仅采用上传文档中的信息进行回答(而不会采用大模型本身的信息)。
7. 构建”本地”应用
最后想想发现有点不对,说是”本地”应用,但笔记本带出去就没法用了,于是本地再安装一下,流程一样:
- Mac上安装一下Ollama(会下载Ollama.app,440MB左右)
- 下载模型和向量模型(
qwen2:1.5b和nomic-embed-text) - 配置AnythingLLM到本机(上面各URL地址改成127.0.0.1)
1
2
3
4
➜ /Users/xd ollama list
NAME ID SIZE MODIFIED
nomic-embed-text:latest 0a109f422b47 274 MB 34 seconds ago
qwen2:1.5b f6daf2b25194 934 MB 6 minutes ago
不过试了下效果,风扇呼呼的转,还是算了,改成了指向PC机。
8. 离线方式搭建
初衷是为了在平时工作环境先集成之前的笔记,但环境里网络受限。这里记录一下通过离线方式搭建Ollama+AnythingLLM的过程。
1、下载AnythingLLM安装包,发现里面还是要下载模型,由于网络受限无法在软件内直接下载。使用Ollama方式加载离线模型
2、下载Windows版本的Ollama安装包,进行安装
3、下载模型
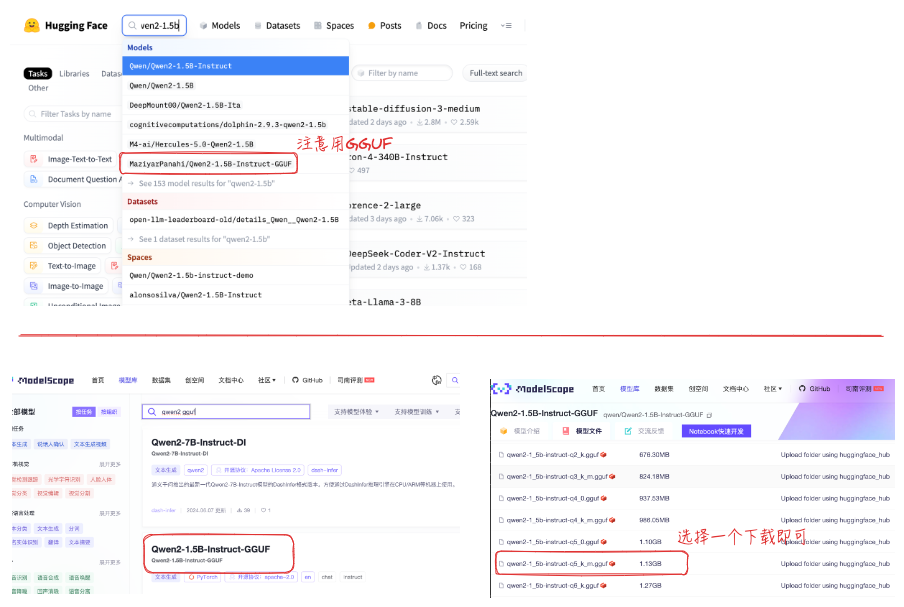
大模型下载地址:魔搭社区(ModelScope) 或者 Hugging Face(这个要梯子)
注意:下载的时候要选.gguf类型而不是model.safetensors,才能用下述Modelfile方式加载,否则会报无法识别。搜仓库时就要区分:
3、加载离线模型
Windows下模型默认放在:C:\Users\xxx用户\.ollama\models\blobs,也可设置OLLAMA_MODELS环境变量调整位置。
1)此处还是拷贝下载的模型到默认目录,这里下载的模型是qwen2-1_5b-instruct-q5_k_m.gguf
2)创建Modelfile。这里在当前目录下创建,内容如下(若模型放置位置不同,以实际为准调整即可):
1
FROM ./qwen2-1_5b-instruct-q5_k_m.gguf
3)执行 ollama create qwen2:1.5 -f Modelfile 加载模型,可自行指定模型名称和版本
完成后 ollama list 即可看到加载的模型。
后续操作和上面基本就没什么差别了,配置AnythingLLM、上传文档,此处省略。
4、效果说明
结果:有点失望。
工作电脑配置有点渣,CPU使用率高、问答慢(无法忍受),还不如自己全局搜markdown+线上GPT的体验好,后续先整理精简下笔记。
9. 小结
基于Ollama+AnythingLLM搭建了简单的文档知识库。不过总体效果还没达到预期。
10. 参考
2、基于Ollama+AnythingLLM轻松打造本地大模型知识库
5、GPT