eBPF学习实践系列(六) -- bpftrace学习和使用
bpftrace学习和使用
1. 背景
前面学习bcc和libbpf时,提到Brendan Gregg等大佬们编写的工具集(几个示意图可参考:eBPF学习实践系列(一) – 初识eBPF ),这些工具已经能提供很丰富的功能了。
但是想自己跟踪一些想要的个性化信息时,需要基于Python或者C/C++写逻辑,写完后有时还要调试各类编译问题,于是学习下bpftrace的使用,实践中更容易上手。
小结下近期的eBPF学习历程:
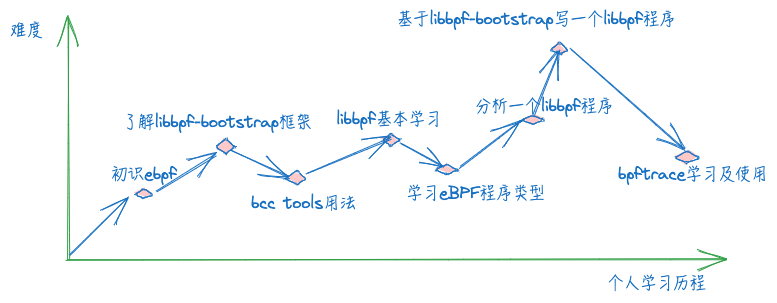
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. bpftrace说明
bpftrace是一种针对较近期的Linux内核(4.x系列起)中eBPF的高级跟踪语言。bpftrace利用LLVM作为后端,将脚本编译为BPF字节码,并借助BCC与Linux BPF系统进行交互,同时也利用了Linux现有的跟踪功能,包括内核动态跟踪(kprobes)、用户级动态跟踪(uprobes)及tracepoint。
bpftrace语言受到了awk、C语言以及先驱跟踪工具如DTrace和SystemTap的启发,并由Alastair Robertson创建。
项目主页:bpftrace
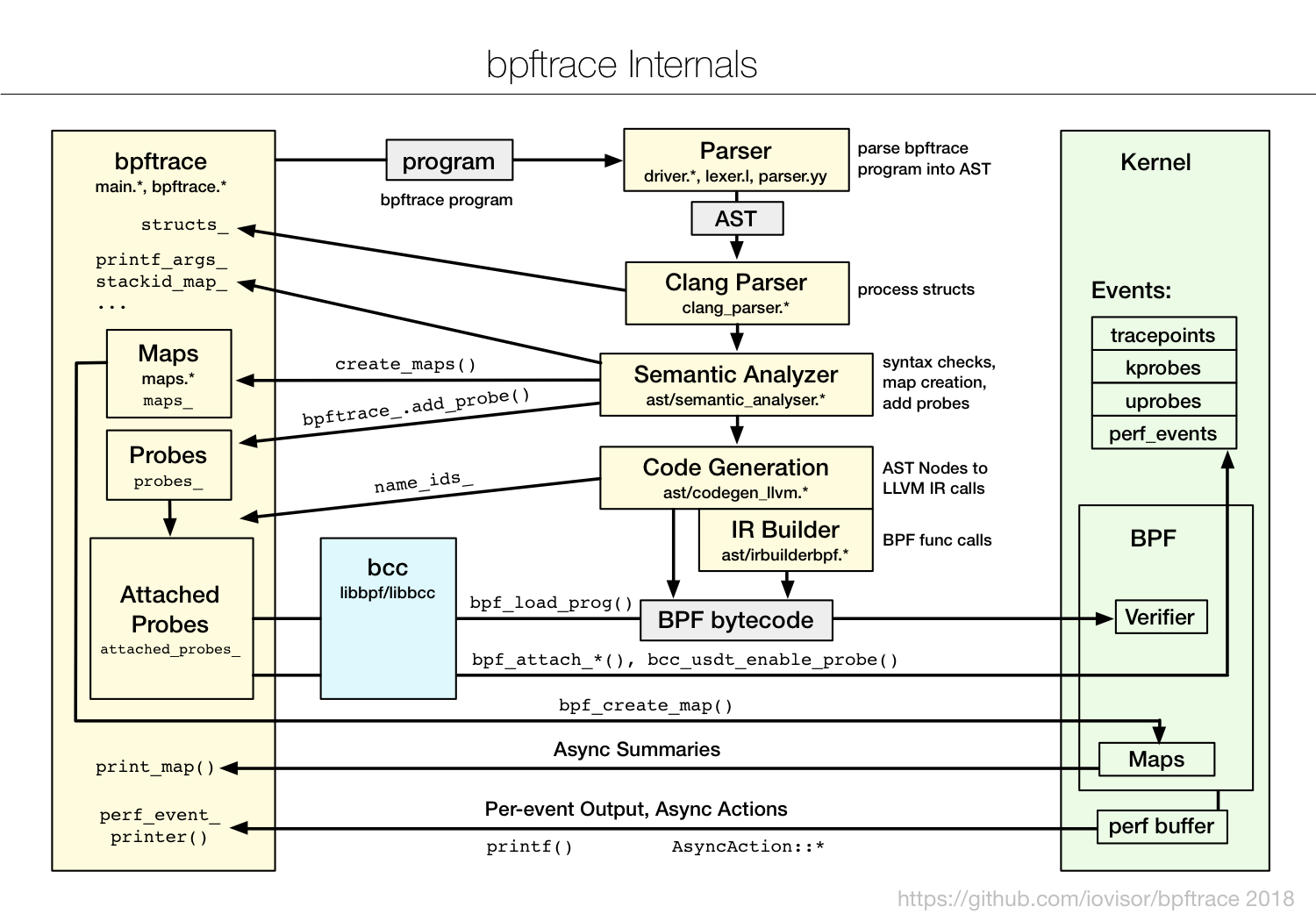
bpftrace内部结构示意图:
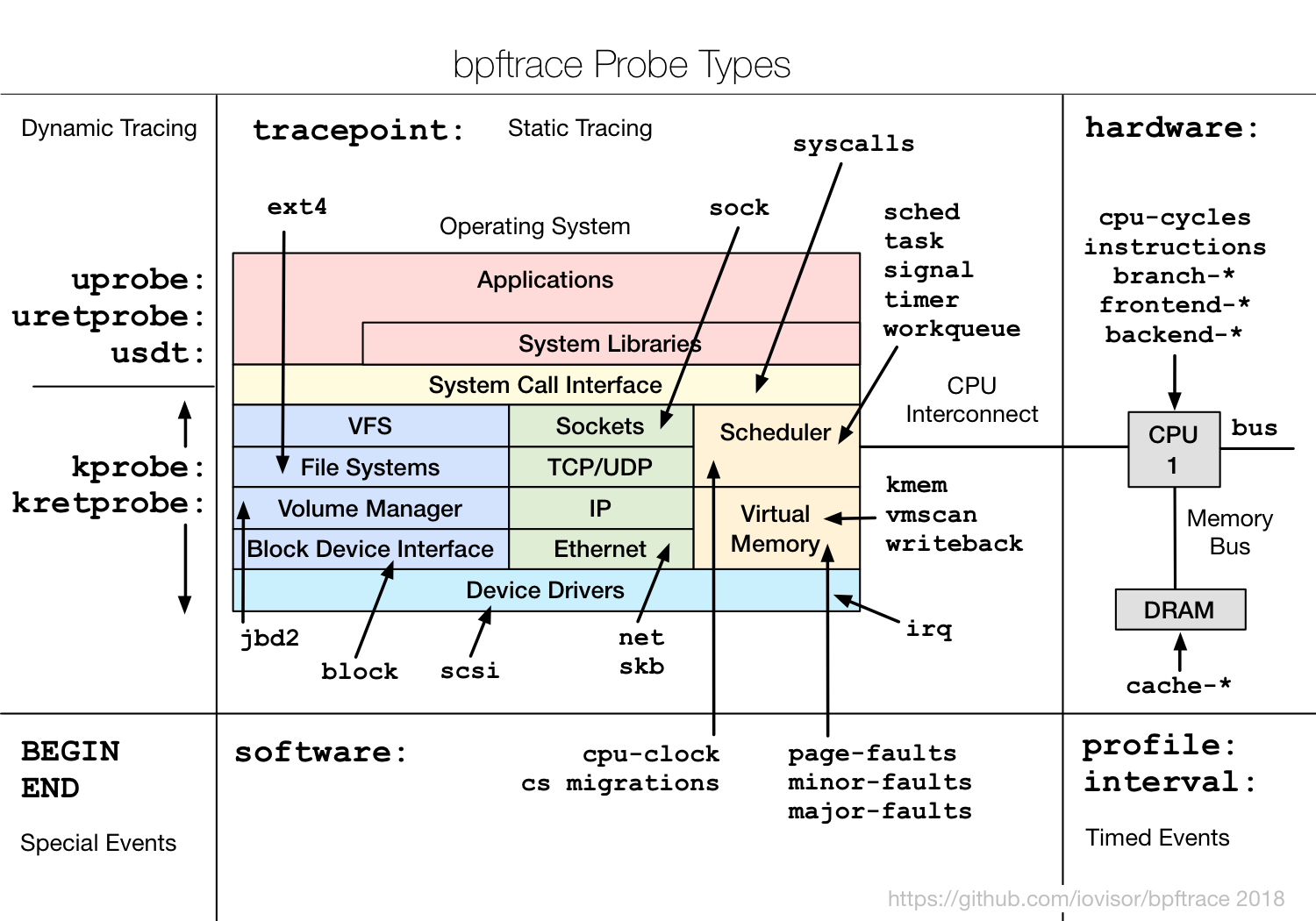
bpftrace提供的追踪类型:
3. bpftrace/BCC/libbpf对比
这三种方式各有优缺点,在实际的生产环境中都有大量的应用(参考):
- bpftrace 通常用在快速排查和定位系统上,它支持用单行脚本的方式来快速开发并执行一个 eBPF 程序。不过,bpftrace 的功能有限,不支持特别复杂的 eBPF 程序,也依赖于 BCC 和 LLVM 动态编译执行。
- BCC 通常用在开发复杂的 eBPF 程序中,其内置的各种小工具也是目前应用最为广泛的 eBPF 小程序。不过,BCC 也不是完美的,它依赖于 LLVM 和内核头文件才可以动态编译和加载 eBPF 程序。
- libbpf 是从内核中抽离出来的标准库,用它开发的 eBPF 程序可以直接分发执行,这样就不需要每台机器都安装 LLVM 和内核头文件了。不过,它要求内核开启 BTF 特性,需要非常新的发行版才会默认开启(如 RHEL 8.2+ 和 Ubuntu 20.10+ 等)。
在实际应用中,你可以根据你的内核版本、内核配置、eBPF 程序复杂度,以及是否允许安装内核头文件和 LLVM 等编译工具等,来选择最合适的方案。
4. 基本用法
查看github上bpftrace项目的一行使用教程:tutorial_one_liners,里面提供了12个简单的使用说明。 (也可以看这篇译文:bpftrace一行教程)
记录下自己运行环境的bcc和bpftrace、llvm版本(有的环境发现有问题)
1
2
3
4
5
6
7
8
9
[root@xdlinux ➜ ~ ]$ rpm -qa|grep bpftr
bpftrace-0.12.1-3.el8.x86_64
[root@xdlinux ➜ ~ ]$ rpm -qa|grep bcc
bcc-0.19.0-4.el8.x86_64
bcc-tools-0.19.0-4.el8.x86_64
python3-bcc-0.19.0-4.el8.x86_64
[root@xdlinux ➜ ~ ]$ rpm -qa|grep llvm
llvm-libs-12.0.1-2.module_el8.5.0+918+ed335b90.x86_64
llvm-12.0.1-2.module_el8.5.0+918+ed335b90.x86_64
前面eBPF学习基础后,理解和使用bpftrace就比较丝滑了,很多直接可用的轮子。
4.1. 列出所有探针
bpftrace -l 'tracepoint:syscalls:sys_enter_*'
支持通配符,如*和?
1
2
3
4
[root@xdlinux ➜ events ]$ bpftrace -l 'tracepoint:skb:*'
tracepoint:skb:consume_skb
tracepoint:skb:kfree_skb
tracepoint:skb:skb_copy_datagram_iovec
4.2. Hello World
bpftrace -e 'BEGIN { printf("hello world\n"); }'
1
2
3
[root@xdlinux ➜ events ]$ bpftrace -e 'BEGIN { printf("hello world\n"); }'
Attaching 1 probe...
hello world
4.3. 探测文件打开
bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args.filename)); }'
common是内建变量,表示当前进程名。还有其他内建变量如: pid、tid- 访问上下文中的成员变量时,低版本使用
args->filename方式访问成员,用错时会报错提示的 str()把一个指针转换成字符串
1
2
3
4
5
6
7
# centos8.5这里,用->访问
[root@xdlinux ➜ events ]$ bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args->filename)); }'
Attaching 1 probe...
irqbalance /proc/interrupts
irqbalance /proc/stat
irqbalance /proc/irq/32/smp_affinity
irqbalance /proc/irq/30/smp_affinity
4.4. 按进程名统计系统调用次数
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
@[comm] = count()表示定义一个map,形式为map<comm, count()>,还可以给map命名count()是一个map函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
[root@xdlinux ➜ events ]$ bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
Attaching 1 probe...
^C
@[sedispatch]: 1
@[gmain]: 4
@[in:imjournal]: 12
@[sshd]: 17
@[dockerd]: 35
@[NetworkManager]: 44
@[tuned]: 54
@[bpftrace]: 64
@[containerd]: 230
# 给map命名,@test
[root@xdlinux ➜ events ]$ bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @test[comm] = count(); }'
Attaching 1 probe...
^C
@test[sssd]: 1
@test[sedispatch]: 2
@test[sssd_be]: 5
@test[sssd_nss]: 5
@test[gmain]: 6
4.5. read()返回值分布统计
过滤进程pid,并进行直方图统计,这里跟踪 tracepoint
bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args.ret); }'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
[root@xdlinux ➜ events ]$ bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 1481/ { @bytes = hist(args->ret); }'
Attaching 1 probe...
^C
@bytes:
(..., 0) 70 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[0] 27 |@@@@@@@@@@@@@@@@@@@@ |
[1] 15 |@@@@@@@@@@@ |
[2, 4) 3 |@@ |
[4, 8) 0 | |
[8, 16) 0 | |
[16, 32) 26 |@@@@@@@@@@@@@@@@@@@ |
[32, 64) 9 |@@@@@@ |
[64, 128) 12 |@@@@@@@@ |
[128, 256) 9 |@@@@@@ |
[256, 512) 4 |@@ |
[512, 1K) 2 |@ |
[1K, 2K) 1 | |
[2K, 4K) 1 | |
[4K, 8K) 0 | |
[8K, 16K) 7 |@@@@@ |
可以看到 ret 是返回值,对应的是读取的长度
1
2
3
4
5
6
7
8
9
10
11
12
13
[root@xdlinux ➜ events ]$ cat syscalls/sys_exit_read/format
name: sys_exit_read
ID: 671
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:long ret; offset:16; size:8; signed:1;
print fmt: "0x%lx", REC->ret
4.6. 动态跟踪read()内核态中返回的字节数
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
跟踪 kretprobe,系统支持的 kretprobe 追踪点列表可以查看 bpftrace -l 'kretprobe:*'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
[root@xdlinux ➜ events ]$ bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
Attaching 1 probe...
^C
@bytes:
(..., 0) 12 | |
[0, 200) 906 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[200, 400) 75 |@@@@ |
[400, 600) 18 |@ |
[600, 800) 11 | |
[800, 1000) 173 |@@@@@@@@@ |
[1000, 1200) 23 |@ |
[1200, 1400) 4 | |
[1400, 1600) 5 | |
[1600, 1800) 6 | |
[1800, 2000) 15 | |
[2000, ...) 276 |@@@@@@@@@@@@@@@ |
4.7. 各进程read()调用的时间
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
统计不同进程花在read()上面的时间,各自按花费时间区间以直方图展示,单位是ns
定义2个map,利用tid作为标识进行关联
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
[root@xdlinux ➜ ~ ]$ bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
Attaching 2 probes...
^C
# 下面结果暂时先用#注释,貌似影响博客解析
# @ns[NetworkManager]:
# [4K, 8K) 2 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
# @ns[containerd]:
# [8K, 16K) 2 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
# @ns[dockerd]:
# [8K, 16K) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
# [16K, 32K) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
# @ns[sshd]:
# [4K, 8K) 2 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
# [8K, 16K) 0 | |
# [16K, 32K) 2 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
# @ns[in:imjournal]:
# [4K, 8K) 7 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
# [8K, 16K) 1 |@@@@@@@ |
# @ns[irqbalance]:
# [256, 512) 3 |@@@@@@@@@@@@@@@@@@@ |
# [512, 1K) 4 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
# [1K, 2K) 2 |@@@@@@@@@@@@@ |
# [2K, 4K) 0 | |
# [4K, 8K) 1 |@@@@@@ |
# [8K, 16K) 8 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
# [16K, 32K) 3 |@@@@@@@@@@@@@@@@@@@ |
# [32K, 64K) 0 | |
# [64K, 128K) 1 |@@@@@@ |
# @start[6395]: 91660555397772
4.8. 统计进程级别的事件
bpftrace -e 'tracepoint:sched:sched* { @[probe] = count(); } interval:s:5 { exit(); }'
统计tracepoint:sched:sched*形式的tracepoint在5s内的触发次数
1
2
3
4
5
6
7
8
9
10
[root@xdlinux ➜ ~ ]$ bpftrace -e 'tracepoint:sched:sched* { @[probe] = count(); } interval:s:5 { exit(); }'
Attaching 25 probes...
@[tracepoint:sched:sched_migrate_task]: 1
@[tracepoint:sched:sched_wake_idle_without_ipi]: 24
@[tracepoint:sched:sched_stat_runtime]: 480
@[tracepoint:sched:sched_wakeup]: 547
@[tracepoint:sched:sched_waking]: 556
@[tracepoint:sched:sched_switch]: 1005
4.9. 跟踪内核函数堆栈
bpftrace -e 'profile:hz:99 { @[kstack] = count(); }'
采集On-CPU的内核堆栈及对应的统计次数,采样频率99Hz
profile:hz:99:所有cpu都以99赫兹的频率采样分析内核栈。为了采集足够的内核信息,这里的99够用了,为什么不是正好100,这是由于采样频率可能与其他定时事件步调一致,所以99赫兹是一个理想的选择
kstack 返回内核调用栈。另外ustack可以分析用户级调用栈**
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
[root@xdlinux ➜ ~ ]$ bpftrace -e 'profile:hz:99 { @[kstack] = count(); }'
Attaching 1 probe...
^C
@[
load_balance+5
rebalance_domains+700
__do_softirq+215
irq_exit+247
smp_apic_timer_interrupt+116
apic_timer_interrupt+15
cpuidle_enter_state+219
cpuidle_enter+44
do_idle+564
cpu_startup_entry+111
start_secondary+411
secondary_startup_64_no_verify+194
]: 1
@[
cpuidle_enter_state+219
cpuidle_enter+44
do_idle+564
cpu_startup_entry+111
start_kernel+1309
secondary_startup_64_no_verify+194
]: 221
@[
cpuidle_enter_state+219
cpuidle_enter+44
do_idle+564
cpu_startup_entry+111
start_secondary+411
secondary_startup_64_no_verify+194
]: 6497
4.10. 调度器跟踪
bpftrace -e 'tracepoint:sched:sched_switch { @[kstack] = count(); }'
4.11. 块级别I/O跟踪
bpftrace -e 'tracepoint:block:block_rq_issue { @ = hist(args.bytes); }'
4.12. 内核结构跟踪
使用内核动态跟踪技术跟踪vfs_read()函数,该函数的(struct path *)作为第一个参数。
path.bt脚本内容:
1
2
3
4
5
6
7
8
9
10
11
#ifndef BPFTRACE_HAVE_BTF
// 没有BTF时手动指定必要的内核头文件
#include <linux/path.h>
#include <linux/dcache.h>
#endif
// kprobe跟踪类型
kprobe:vfs_open
{
printf("open path: %s\n", str(((struct path *)arg0)->dentry->d_name.name));
}
执行示例:
1
2
3
4
5
6
# bpftrace path.bt
Attaching 1 probe...
open path: dev
open path: if_inet6
open path: retrans_time_ms
[...]
5. bpftrace tools
bpftrace项目的 tools 目录下有很多直接可用的工具,作为平时使用和开发参考都是值得去看的。
若是yum安装的bpftrace,tools默认安装在:/usr/share/bpftrace/tools
过滤tcp相关的bpftrace脚本,可以用看到之前bcc tools里面的几个熟面孔
1
2
3
4
5
6
7
➜ /Users/xd/Documents/workspace/repo/bpftrace/tools git:(master) ls -ltr |grep tcp|grep .bt
-rwxr-xr-x 1 xd staff 1976 6 29 10:07 tcpaccept.bt
-rwxr-xr-x 1 xd staff 1869 6 29 10:07 tcpconnect.bt
-rwxr-xr-x 1 xd staff 2689 6 29 10:07 tcpdrop.bt
-rwxr-xr-x 1 xd staff 3005 6 29 10:07 tcplife.bt
-rwxr-xr-x 1 xd staff 2340 6 29 10:07 tcpretrans.bt
-rwxr-xr-x 1 xd staff 962 6 29 10:07 tcpsynbl.bt
简单看一下tcpdrop.bt内容:(对比BCC和libbpf开发,这里省了很多事,当然先不考虑通用移植性)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
#!/usr/bin/env bpftrace
/*
* tcpdrop.bt Trace TCP kernel-dropped packets/segments.
* For Linux, uses bpftrace and eBPF.
*
* USAGE: tcpdrop.bt
*
* This is a bpftrace version of the bcc tool of the same name.
*
* This provides information such as packet details, socket state, and kernel
* stack trace for packets/segments that were dropped via kfree_skb.
* It cannot show tcp flags.
*
# 当前这个脚本对内核是有要求的。对于老版本内核old下面有一个对应脚本:tools/old/tcpdrop.bt
* For Linux 5.17+ (see tools/old for script for lower versions).
*
* Copyright (c) 2018 Dale Hamel.
* Licensed under the Apache License, Version 2.0 (the "License")
*
* 23-Nov-2018 Dale Hamel created this.
* 01-Oct-2022 Rong Tao use tracepoint:skb:kfree_skb
*/
#ifndef BPFTRACE_HAVE_BTF
#include <linux/socket.h>
#include <net/sock.h>
#else
/*
* With BTF providing types, socket headers are not needed.
* We only need to supply the preprocessor defines in this script.
* AF_INET/AF_INET6 are part of the stable arch-independent Linux ABI
*/
#define AF_INET 2
#define AF_INET6 10
#endif
BEGIN
{
printf("Tracing tcp drops. Hit Ctrl-C to end.\n");
printf("%-8s %-8s %-16s %-21s %-21s %-8s\n", "TIME", "PID", "COMM", "SADDR:SPORT", "DADDR:DPORT", "STATE");
// See https://github.com/torvalds/linux/blob/master/include/net/tcp_states.h
# 定义map
@tcp_states[1] = "ESTABLISHED";
@tcp_states[2] = "SYN_SENT";
@tcp_states[3] = "SYN_RECV";
@tcp_states[4] = "FIN_WAIT1";
@tcp_states[5] = "FIN_WAIT2";
@tcp_states[6] = "TIME_WAIT";
@tcp_states[7] = "CLOSE";
@tcp_states[8] = "CLOSE_WAIT";
@tcp_states[9] = "LAST_ACK";
@tcp_states[10] = "LISTEN";
@tcp_states[11] = "CLOSING";
@tcp_states[12] = "NEW_SYN_RECV";
}
# 跟踪 skb:kfree_skb 这个tracepoint
tracepoint:skb:kfree_skb
{
# args 是上下文,根据前面的eBPF学习可知,可利用tracefs或者 bpftrace -lv tracepoint:skb:kfree_skb 查看
# reason是后面内核版本加的字段
$reason = args.reason;
# 变量定义和访问都用`$xxx`形式
$skb = (struct sk_buff *)args.skbaddr;
$sk = ((struct sock *) $skb->sk);
$inet_family = $sk->__sk_common.skc_family;
if ($reason > SKB_DROP_REASON_NOT_SPECIFIED &&
($inet_family == AF_INET || $inet_family == AF_INET6)) {
if ($inet_family == AF_INET) {
$daddr = ntop($sk->__sk_common.skc_daddr);
$saddr = ntop($sk->__sk_common.skc_rcv_saddr);
} else {
$daddr = ntop($sk->__sk_common.skc_v6_daddr.in6_u.u6_addr8);
$saddr = ntop($sk->__sk_common.skc_v6_rcv_saddr.in6_u.u6_addr8);
}
$lport = $sk->__sk_common.skc_num;
$dport = $sk->__sk_common.skc_dport;
// Destination port is big endian, it must be flipped
$dport = bswap($dport);
$state = $sk->__sk_common.skc_state;
$statestr = @tcp_states[$state];
time("%H:%M:%S ");
printf("%-8d %-16s ", pid, comm);
printf("%39s:%-6d %39s:%-6d %-10s\n", $saddr, $lport, $daddr, $dport, $statestr);
printf("%s\n", kstack);
}
}
END
{
# 清理前面定义的map
clear(@tcp_states);
}
6. 基本语法
下面只列举几个语法相关示例:
- 注释:
//或者/* */ - 数组:
int a[] = {1,2,3} - map:
@name[key] = expression,key也可以是多变量组合:@name[key1,key2] = expression - 指针:和C类似,但是bpftrace中,需要用指针的形式读取变量
1
2
3
4
5
6
7
8
9
10
struct MyStruct {
int a;
}
kprobe:dummy {
$ptr = (struct MyStruct *) arg0;
$st = *$ptr;
print($st.a);
print($ptr->a);
}
内建变量:
$1、$2等,传给bpftrace程序的第几个参数,如果传入的是字符串,用str()查看其内容arg0、arg1等,传给待跟踪函数的参数,用于kprobes, uprobes, usdt。注意:arg0是指第一个参数,即从0开始,args,跟踪函数的所有参数的结构体,用于tracepoint, kfunc, and uprobecomm当前线程(current thread)cpu当前处理bpf程序的CPU IDfunc当前被跟踪的函数(用于kprobe、uprobe)pid当前进程pid(Process ID of the current thread,当前线程对应的进程)tid当前线程idreturn关键字,当前退出probe。和exit()的差别是return不退出bpftraceretval被跟踪函数的返回值(用于kretprobe, uretprobe, kretfunc)
函数:
bswap(类型)(包含uint8 bswap(uint8 n)、uint16 bswap(uint16 n)、32、64)- 按byte翻转字节序。对于8字节数,结果不变
buf_t buf(void * data, [int64 length])- 从data里面读取length长度的数据,length定义类型是int64
- 返回的
buf_t对象,可以用%r格式化输出十进制字符串:printf("%r\n", buf(kaddr("avenrun"), 8));
void exit()退出程序kstack()内核调用栈- 基于BPF的stack maps实现,即 BPF_MAP_TYPE_STACK
- 比如:
kprobe:ip_output { @[kstack()] = count(); },统计各堆栈出现次数
inet_t ntop([int64 af, ] int addr),把ipv4/ipv6转换成点分十进制形式,也可第一个参数显式指定协议族(如AF_INET)char addr[4] pton(const string *addr_v4)相对于上面是反的,这里是地址转成网络序
probe:
- 可以在一行里追踪多个probe,如
kprobe:tcp_reset,kprobe:tcp_v4_rcv { xxx } - 也可以用通配符
kprobe:tcp_* { xxx } BEGIN/END,是特殊的bpftrace运行时内建事件,分别在其他probe之前及之后触发- 大部probe类型都有缩写,如
kprobe:f可缩写为k:f,tracepoint:f可缩写为t:f(各具体小节有shortname说明)
示例:
跟踪短时进程:bpftrace -e 'tracepoint:syscalls:sys_enter_execve,tracepoint:syscalls:sys_enter_execveat { printf("%-6d %-8s", pid, comm); join(args->argv);}' (join把字符串数组格式的参数用空格拼接起来)
7. 小结
学习了解bpftrace和基本用法,跟BCC、libbpf做了简单对比
8. 参考
1、bpftrace
6、GPT