TCP发送接收过程 -- 学习netfilter和iptables
netfilter作为网络协议栈非常关键的一部分,本篇学习下netfilter和iptables,有助于理解TCP发送接收过程
1. 背景
在追踪内核网络堆栈的几种方式里记录了一下iptables设置日志跟踪的实践过程,CentOS8下为什么实验失败还没有定论。
平常工作中设置iptables防火墙规则,基本只是浮于表面记住,不清楚为什么这么设置,规则也经常混淆。
TCP半连接全连接(一) – 全连接队列相关过程里面的TODO项:“内核drop包的时机,以及跟抓包的关系。哪些情况可能会抓不到drop的包?”,在系列文章里分析了源码里全连接、半连接溢出时drop的位置,给了个tcpdump能抓到drop原始请求包的现象结论,但没有理清楚流程。
这些问题都或多或少,或直接或间接跟内核中的netfilter框架有关系。
基于上述几个原因,学习一下netfilter框架,以及它的“客户端”:iptables。同时说明下tcpdump抓包跟netfilter的关系。
主要参考学习以下文章:
- [译] 深入理解 iptables 和 netfilter 架构
- 用户态 tcpdump 如何实现抓到内核网络包的?
- 来,今天飞哥带你理解 iptables 原理!
- iptable 的基石:netfilter 原理与实战
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. netfilter基本介绍
官网:netfilter,上面可看到netfilter相关项目的动态,如iptables、nftables、conntrack-tools等。
netfilter是Linux内核中一个非常关键的子系统,它负责在网络协议栈的不同层级处理数据包,提供了一系列强大的网络数据包处理功能,包括但不限于数据包过滤、网络地址转换(NAT)以及连接跟踪。
netfilter框架由Linux内核防火墙和网络维护者 Rusty Russell 所提出和实现。这个作者还基于 netfilter 开发了大名鼎鼎的 iptables,用于在用户空间管理这些复杂的 netfilter 规则。(番外:这位大佬18年宣布退出并投入到比特币闪电网络的原型开发中了,大佬的博客)
- netfilter最初在Linux 2.4.x内核系列中引入,作为继
IPchains之后的新一代Linux防火墙框架。它至今仍是Linux系统中实现网络数据包处理的核心机制。 - netfilter的设计遵循高度模块化的原则,这意味着它的功能可以通过加载或卸载内核模块来动态扩展,从而实现了极高的灵活性和可扩展性。
- netfilter的核心在于其hook机制。它在Linux网络堆栈的关键位置定义了多个挂载点(hook points),比如在数据包流入(PREROUTING)、流出(POSTROUTING)、进入本地进程(INPUT)和转发(FORWARD)时。当数据包经过这些点时,预先注册的hook函数会被调用,执行相应的处理逻辑,如过滤、修改或丢弃数据包。
- netfilter通常与用户空间工具
iptables一起提及。netfilter作为内核部分,负责实际的数据包处理;而iptables则是一个高级命令行工具,允许管理员定义复杂的规则集来控制netfilter的行为,比如设置过滤规则、NAT规则等。
nftables:(之前比较陌生,上面netfilter官网上也有nftables介绍)
- 也是一个netfilter项目,旨在替换现有的 {ip,ip6,arp,eb}tables 框架,为 {ip,ip6}tables 提供一个新的包过滤框架、一个新的用户空间实用程序(nft)和一个兼容层。
- 虽然
iptables长期以来是与netfilter交互的主要方式,但随着nftables的引入,它提供了一种更现代、更灵活的方式来配置netfilter规则。nftables支持更丰富的表达能力和更高效的内部实现。 - CentOS8里,就用
nftables框架替代了iptables框架作为默认的网络包过滤工具。(难道这就是之前日志跟踪实验没成功的原因? TODO)
疑问:既然nftables旨在替换iptables,现在的使用情况怎么样?
实际上目前各大 Linux 发行版都已经不建议使用 iptables 了,甚至把 iptables 重命名为了 iptables-legacy
目前 opensuse/debian/opensuse 都已经预装了并且推荐使用 nftables,而且 firewalld 已经默认使用 nftables 作为它的后端了。
但是现在 kubernetes/docker 都还是用的 iptables
查看自己当前CentOS8.5的环境,firewalld的配置文件:/etc/firewalld/firewalld.conf,看配的是iptables
1
2
3
4
5
6
7
# FirewallBackend
# Selects the firewall backend implementation.
# Choices are:
# - nftables (default)
# - iptables (iptables, ip6tables, ebtables and ipset)
#FirewallBackend=nftables
FirewallBackend=iptables
3. netfilter hooks
netfilter提供了5个hook点,这些在内核协议栈中已经定义好了(之前学习eBPF时可了解到内核提供了各种类型hook钩子)
注意:下面列的hook类型是IPv4的宏,IPv6则为NF_IP6_PRE_ROUTING形式,枚举值是一样的。具体见下面ip_rcv逻辑小节的分析说明。
NF_IP_PRE_ROUTING:接收到的包进入协议栈后立即触发此 hook,在进行任何路由判断(将包发往哪里)之前NF_IP_LOCAL_IN:接收到的包经过路由判断,如果目的是本机,将触发此 hookNF_IP_FORWARD:接收到的包经过路由判断,如果目的是其他机器,将触发此 hookNF_IP_LOCAL_OUT:本机产生的准备发送的包,在进入协议栈后立即触发此 hookNF_IP_POST_ROUTING:本机产生的准备发送的包或者转发的包,在经过路由判断之后, 将触发此 hook
内核协议栈各hook点位置和控制流如下图所示(来自Wikipedia):

3.1. iptables的“四表五链”
为了理解上面这张图,还需要了解 chain 和 table的概念。
上面我们说iptables是基于netfilter实现的,用于控制netfilter的行为。很多时候两者混在一起说,所以直接基于iptables来说明上图中的chain和table。
- iptables 使用
table来组织规则,根据用来做什么类型的判断标准,将规则分为不同table。 - 在每个
table内部,规则被进一步组织成chain,内置的chain是由内置的hook触发 的。
chain:
chain基本上能决定规则是何时被匹配的。内置的 chain 名字和 netfilter hook 名字是一一对应的:
PREROUTING:由NF_IP_PRE_ROUTINGhook 触发INPUT:由NF_IP_LOCAL_INhook 触发FORWARD:由NF_IP_FORWARDhook 触发OUTPUT:由NF_IP_LOCAL_OUThook 触发POSTROUTING:由NF_IP_POST_ROUTINGhook 触发
为什么叫链,看下下面以PREROUTING为例的示意图就明白了:
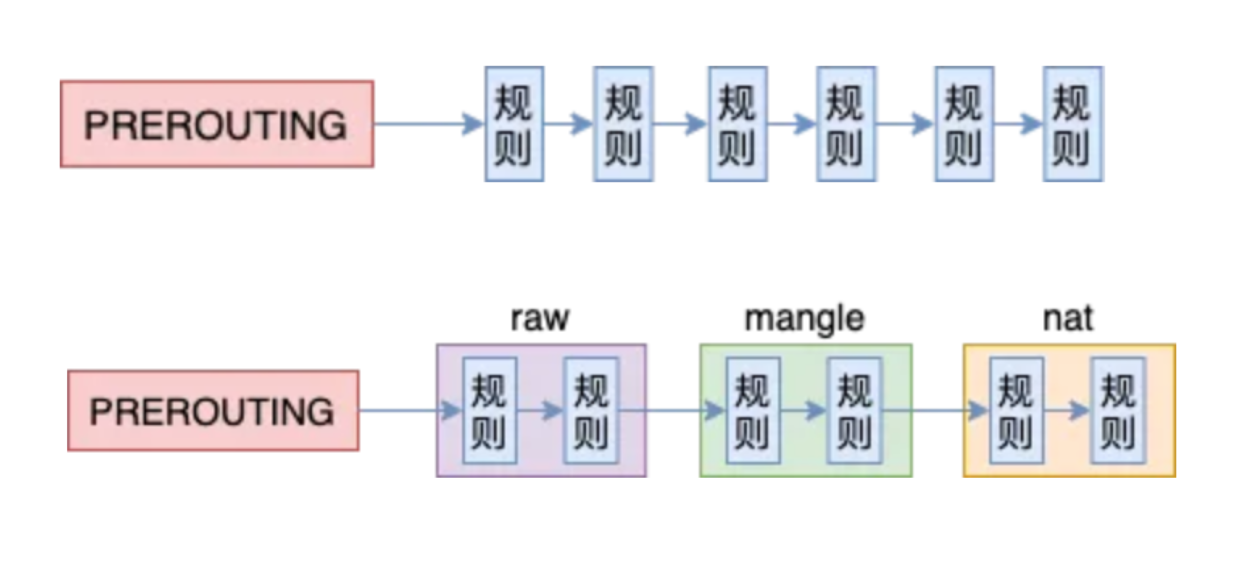
规则列表以链的方式组织,且归属不同的表(table),不同表之间还有优先级关系。
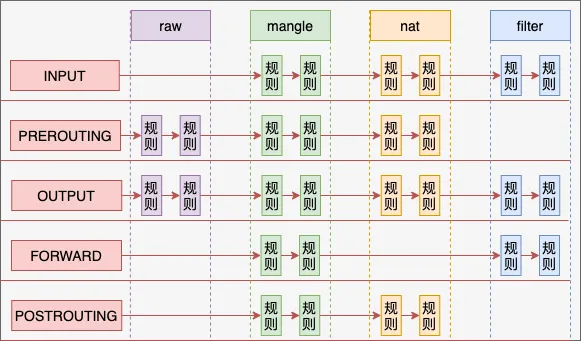
table:
iptables 提供的 table 类型如下:
filter:过滤(放行/拒绝),判断是否允许一个包通过,这个 table 提供了防火墙 的一些常见功能nat:网络地址转换,通常用于将包路由到无法直接访问的网络mangle:修改 IP 头raw:conntrack 相关,其唯一目的就是提供一个让包绕过连接跟踪的框架
四表五链的关系和优先级:
下面跟踪分析下内核流程。这里先找TCP相关追踪点获取一个堆栈,再根据堆栈去找代码分析。
4. 接收流程内核代码跟踪
说明:本篇环境基于CentOS8.5,内核:4.18.0-348.7.1.el8_5.x86_64
4.1. 先获取一份网络堆栈
有多种方式获取堆栈,可按之前追踪内核网络堆栈的几种方式里的方法,这里用bpftrace来获取。
1
2
3
4
5
6
7
8
9
10
11
12
13
# TCP相关追踪点
[root@xdlinux ➜ ~ ]$ bpftrace -l |grep -E ':tcp:|sock:inet|skb:'
tracepoint:skb:consume_skb
tracepoint:skb:kfree_skb
tracepoint:skb:skb_copy_datagram_iovec
tracepoint:sock:inet_sock_set_state
tracepoint:tcp:tcp_destroy_sock
tracepoint:tcp:tcp_probe
tracepoint:tcp:tcp_rcv_space_adjust
tracepoint:tcp:tcp_receive_reset
tracepoint:tcp:tcp_retransmit_skb
tracepoint:tcp:tcp_retransmit_synack
tracepoint:tcp:tcp_send_reset
先选取跟TCP状态变化有关的 tracepoint:sock:inet_sock_set_state进行跟踪,并打印内核堆栈
方法:用bpftrace启动eBPF跟踪,服务端python -m http.server起一个服务,并通过客户端curl 192.168.1.150:8000。
截取一个网络接收的堆栈如下(从下到上):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
[root@xdlinux ➜ ~ ]$ bpftrace -e 'tracepoint:sock:inet_sock_set_state { printf("comm:%s, stack:%s\n", comm, kstack); }'
...
comm:swapper/9, stack:
inet_sk_state_store+132
# linux-4.18/net/ipv4/af_inet.c
inet_sk_state_store+132
# linux-4.18/net/ipv4/tcp.c
tcp_set_state+148
# linux-4.18/net/ipv4/tcp.c
tcp_done+54
tcp_rcv_state_process+3421
# linux-4.18/net/ipv4/tcp_input.c
tcp_v4_do_rcv+180
# 传输层,TCP协议初始化时.handler注册为该函数
# linux-4.18/net/ipv4/tcp_ipv4.c
tcp_v4_rcv+2883
ip_protocol_deliver_rcu+44
# linux-4.18/net/ipv4/ip_input.c
ip_local_deliver_finish+77
ip_local_deliver+224
# IP层
# linux-4.18/net/ipv4/ip_input.c
ip_rcv+635
# 网络协议栈收到skb,依次向上面的各协议调用栈传递
# linux-4.18/net/core/dev.c,声明为static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
__netif_receive_skb_core+2963
# 数据包将被送到协议栈中
# linux-4.18/net/core/dev.c
netif_receive_skb_internal+61
# 网卡GRO特性,理解成把相关的小包合并成一个大包,目的是减少传送给网络栈的包数
# linux-4.18/net/core/dev.c,声明为napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb),传入已经是skb了
napi_gro_receive+186
# 网卡驱动注册的poll,这里面抽取数据成 struct sk_buff *skb
# linux-4.18/drivers/net/ethernet/realtek/r8169.c
rtl8169_poll+667
__napi_poll+45
# net_dev_init(void)时注册的 NET_RX_SOFTIRQ软中断 处理函数
# linux-4.18/net/core/dev.c
net_rx_action+595
# 软中断
__softirqentry_text_start+215
irq_exit+247
# 硬中断
do_IRQ+127
ret_from_intr+0
cpuidle_enter_state+219
cpuidle_enter+44
do_idle+564
cpu_startup_entry+111
start_secondary+411
secondary_startup_64_no_verify+194
...
上面堆栈也映证了”图解Linux网络包接收过程“里的分析流程图:
软中断处理:
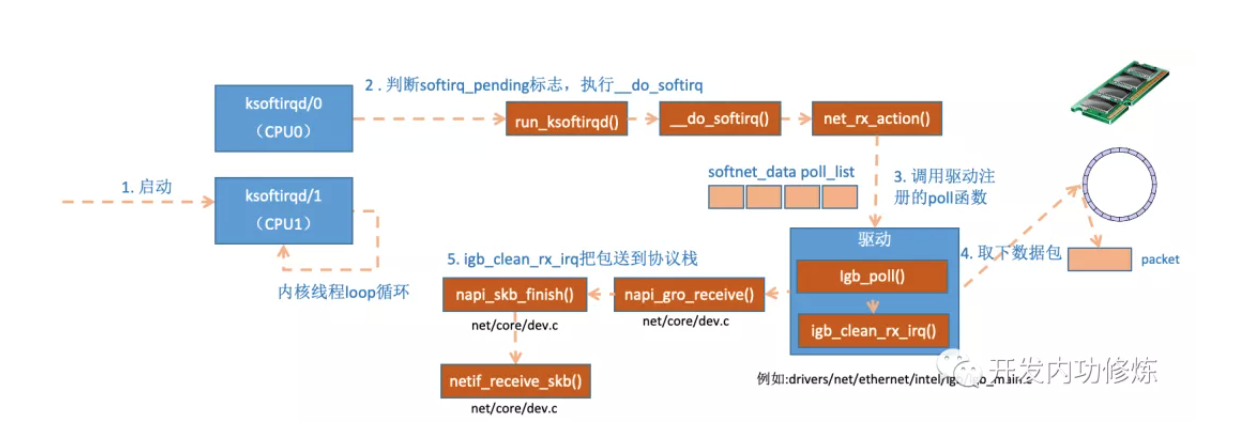
网络协议栈处理:
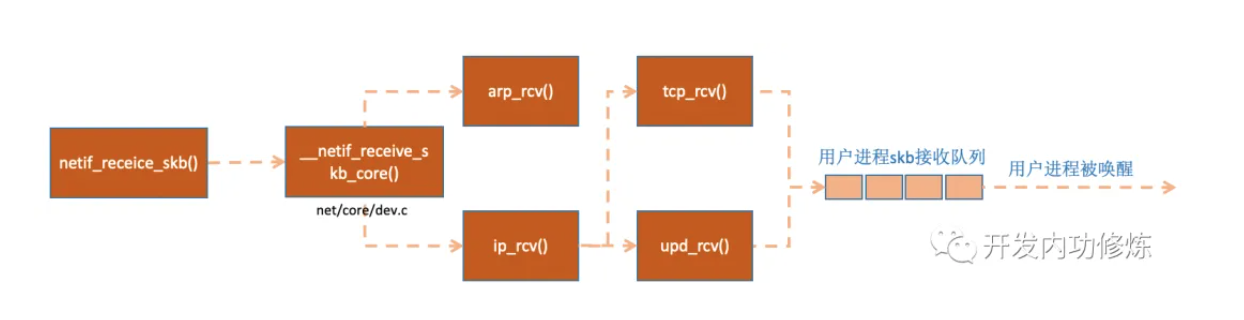
下面先分析下内核代码中网络包接收流程涉及的hook处理
4.2. 设备层处理
有上面的堆栈后,选取几个关键过程分析,直接参考下”图解Linux网络包接收过程“里的梳理说明,过程大体是对应的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// linux-4.18/net/core/dev.c
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
struct packet_type *ptype, *pt_prev;
rx_handler_func_t *rx_handler;
struct net_device *orig_dev;
bool deliver_exact = false;
int ret = NET_RX_DROP;
__be16 type;
net_timestamp_check(!netdev_tstamp_prequeue, skb);
// 定义 tracepoint:net:netif_receive_skb,可以通过eBPF追踪
trace_netif_receive_skb(skb);
...
// &ptype_all、&skb->dev->ptype_all 这里会将数据送入抓包点。
// tcpdump就是从这个入口获取包的
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
// 从数据包中取出协议信息,然后遍历注册在这个协议上的回调函数列表
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {
if (pt_prev)
// 从数据包中取出协议信息,然后遍历注册在这个协议上的回调函数列表
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
...
}
1
2
3
4
5
6
7
8
9
10
11
// linux-4.18/net/core/dev.c
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev)
{
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
return -ENOMEM;
refcount_inc(&skb->users);
// 协议层注册的处理函数,对于ip包来讲,就会进入到ip_rcv(如果是arp包的话,会进入到arp_rcv)
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
贴一下pt_prev对应的packet_type结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
// linux-4.18/include/linux/netdevice.h
struct packet_type {
__be16 type; /* This is really htons(ether_type). */
struct net_device *dev; /* NULL is wildcarded here */
int (*func) (struct sk_buff *,
struct net_device *,
struct packet_type *,
struct net_device *);
bool (*id_match)(struct packet_type *ptype,
struct sock *sk);
void *af_packet_priv;
struct list_head list;
};
4.3. 网络层ip_rcv注册时机
上面deliver_skb(xxx)中调用的pt_prev->func(),其中的func就是网络子系统inet_init()初始化时,注册的IP网络层处理函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// linux-4.18/net/ipv4/af_inet.c
static int __init inet_init(void)
{
...
rc = proto_register(&tcp_prot, 1);
if (rc)
goto out;
rc = proto_register(&udp_prot, 1);
if (rc)
goto out_unregister_tcp_proto;
...
// 注册ip网络层的处理函数为 ip_rcv
dev_add_pack(&ip_packet_type);
...
}
// ip_packet_type结构如下
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};
4.4. ip_rcv逻辑
继续看一下IP层的处理逻辑 ip_rcv,可看到NF_INET_PRE_ROUTING这个hook
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// linux-4.18/net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
const struct iphdr *iph;
struct net *net;
u32 len;
...
// 这里就是一个 netfilter 的hook了,类型为 NF_INET_PRE_ROUTING
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
csum_error:
__IP_INC_STATS(net, IPSTATS_MIB_CSUMERRORS);
inhdr_error:
__IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
drop:
kfree_skb(skb);
out:
return NET_RX_DROP;
}
这里NF_HOOK是一个钩子函数,当执行完注册的钩子后就会执行到最后一个参数指向的函数ip_rcv_finish。
hook类型看起来和上面netfilter介绍时的没完全对应起来。检索下代码可知是IPv4和IPv6各自定义了宏跟hook枚举值对应,实际的值是一样的。
而上面介绍时也只是放了IPv4的hook。
1
2
3
4
5
6
7
8
9
// linux-4.18/include/uapi/linux/netfilter.h
enum nf_inet_hooks {
NF_INET_PRE_ROUTING,
NF_INET_LOCAL_IN,
NF_INET_FORWARD,
NF_INET_LOCAL_OUT,
NF_INET_POST_ROUTING,
NF_INET_NUMHOOKS
};
IPv4的netfilter hooks:
1
2
3
4
5
6
7
8
9
10
11
12
13
// linux-4.18/include/uapi/linux/netfilter_ipv4.h
/* IP Hooks */
/* After promisc drops, checksum checks. */
#define NF_IP_PRE_ROUTING 0
/* If the packet is destined for this box. */
#define NF_IP_LOCAL_IN 1
/* If the packet is destined for another interface. */
#define NF_IP_FORWARD 2
/* Packets coming from a local process. */
#define NF_IP_LOCAL_OUT 3
/* Packets about to hit the wire. */
#define NF_IP_POST_ROUTING 4
#define NF_IP_NUMHOOKS 5
IPv6的netfilter hooks:
1
2
3
4
5
6
7
8
9
10
11
12
13
// linux-4.18/include/uapi/linux/netfilter_ipv6.h
/* IP6 Hooks */
/* After promisc drops, checksum checks. */
#define NF_IP6_PRE_ROUTING 0
/* If the packet is destined for this box. */
#define NF_IP6_LOCAL_IN 1
/* If the packet is destined for another interface. */
#define NF_IP6_FORWARD 2
/* Packets coming from a local process. */
#define NF_IP6_LOCAL_OUT 3
/* Packets about to hit the wire. */
#define NF_IP6_POST_ROUTING 4
#define NF_IP6_NUMHOOKS 5
4.5. ip_rcv_finish
上面执行完NF_INET_PRE_ROUTING hook后,进入 ip_rcv_finish 函数处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// linux-4.18/net/ipv4/ip_input.c
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
int (*edemux)(struct sk_buff *skb);
struct net_device *dev = skb->dev;
struct rtable *rt;
int err;
...
// 处理input,rt_dst_alloc 时(route.c),input函数注册为了 ip_local_deliver
return dst_input(skb);
...
drop:
kfree_skb(skb);
return NET_RX_DROP;
drop_error:
if (err == -EXDEV)
__NET_INC_STATS(net, LINUX_MIB_IPRPFILTER);
goto drop;
}
1
2
3
4
5
6
// linux-4.18/include/net/dst.h
/* Input packet from network to transport. */
static inline int dst_input(struct sk_buff *skb)
{
return skb_dst(skb)->input(skb);
}
上面的input处理函数,实际调用到 ip_local_deliver,可看到这里又有个hook:NF_INET_LOCAL_IN
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// linux-4.18/net/ipv4/ip_input.c
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
// netfilter hook: NF_INET_LOCAL_IN
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
传输层的处理,比如跟踪堆栈中tcp_v4_rcv及后续的调用,这里暂不展开分析了,简单过一下。
1
2
3
4
5
6
7
8
9
10
11
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
...
const struct net_protocol *ipprot;
...
ipprot = rcu_dereference(inet_protos[protocol]);
...
// 对于TCP这里是tcp_v4_rcv,对应struct net_protocol tcp_protocol等协议初始化注册的接口
ret = ipprot->handler(skb);
...
}
4.6. 接收流程小结
小结上述网络包接收时的netfilter hook,先经过PREROUTING,而后经过INPUT hook。
简单总结接收数据的处理流程是:PREROUTING链 -> 路由判断(是本机)-> INPUT链 -> …,如下图所示。
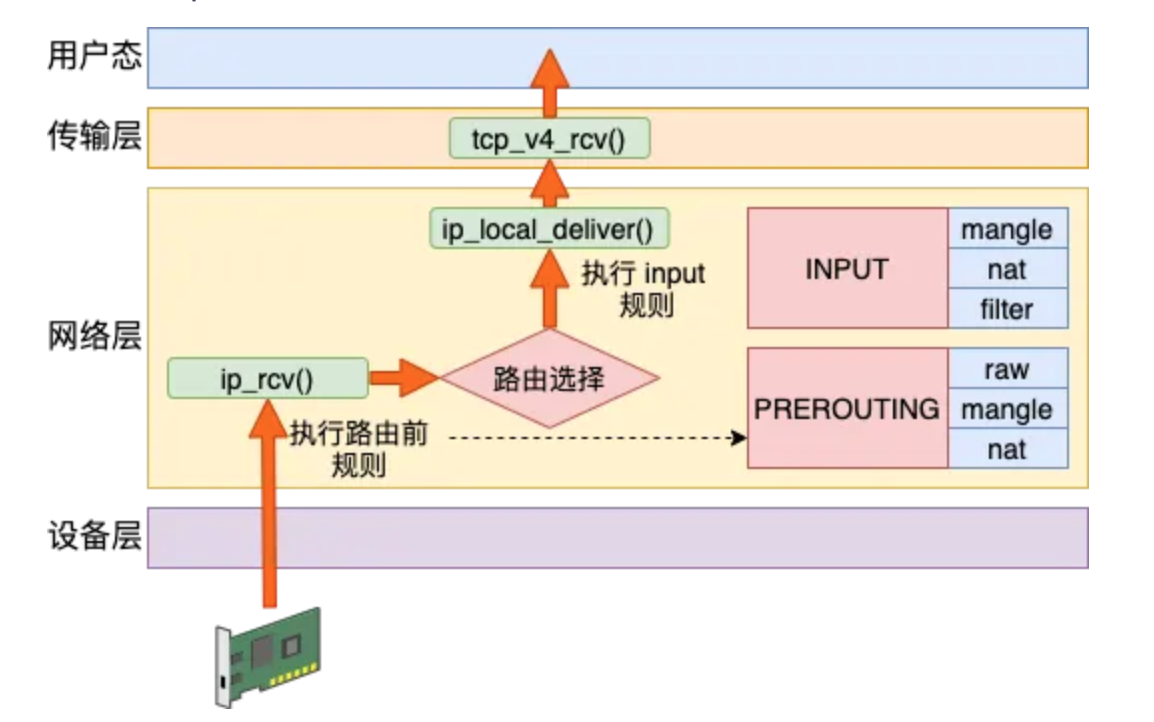
5. 发送流程内核代码跟踪
发送流程也如上跟踪一下。
5.1. 获取发送堆栈
上面bpftrace -l |grep -E ':tcp:|sock:inet|skb:'过滤的几个追踪点,看起来貌似没特别合适跟踪发送数据的。
接收流程里我们看到有tracepoint:net:netif_receive_skb,到tracefs支持的符号里找下类似的发送追踪点。
/sys/kernel/tracing/available_events里是支持的各类tracepoint/sys/kernel/tracing/available_filter_functions里一般是支持的各类kprobe
优先选择tracepoint,看netif_receive_skb附近的net_dev_xmit是设备层发送数据的,先跟踪看下
1
2
3
4
5
6
7
8
9
10
11
12
# available_events 文件内容截取
...
net:netif_rx
net:netif_receive_skb
net:net_dev_queue
net:net_dev_xmit_timeout
net:net_dev_xmit
net:net_dev_start_xmit
skb:skb_copy_datagram_iovec
skb:consume_skb
skb:kfree_skb
...
仍旧是上面的方法:用bpftrace启动eBPF跟踪,服务端python -m http.server起一个服务,并通过客户端curl 192.168.1.150:8000。
这里加个python进程的pid过滤条件,追踪堆栈信息截取如下(从下到上):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
[root@xdlinux ➜ tracing ]$ bpftrace -e 'tracepoint:net:net_dev_xmit /pid==1569531/ { printf("comm:%s, stack:%s\n", comm, kstack); }'
Attaching 1 probe...
comm:python, stack:
dev_hard_start_xmit+394
# 调用驱动程序来发送数据
dev_hard_start_xmit+394
sch_direct_xmit+159
# 通过网络设备子系统发送数据
__dev_queue_xmit+2140
ip_finish_output2+738
ip_output+112
# 网络层发送数据
__ip_queue_xmit+349
__tcp_transmit_skb+1362
# 传输层发送数据
tcp_write_xmit+1077
__tcp_push_pending_frames+50
tcp_sendmsg_locked+3128
# TCP协议注册的sendmsg函数为tcp_sendmsg,具体见下面网络协议初始化小节的分析
tcp_sendmsg+39
# 系统调用里会调到 sock_sendmsg,里面会调用到具体协议的 sendmsg
sock_sendmsg+62
# 实际调用到__sys_sendto
__sys_sendto+238
__x64_sys_sendto+36
# 用户态进行系统调用
do_syscall_64+91
entry_SYSCALL_64_after_hwframe+101
这里的堆栈映证”25 张图,一万字,拆解 Linux 网络包发送过程“里的流程分析图一起查看:
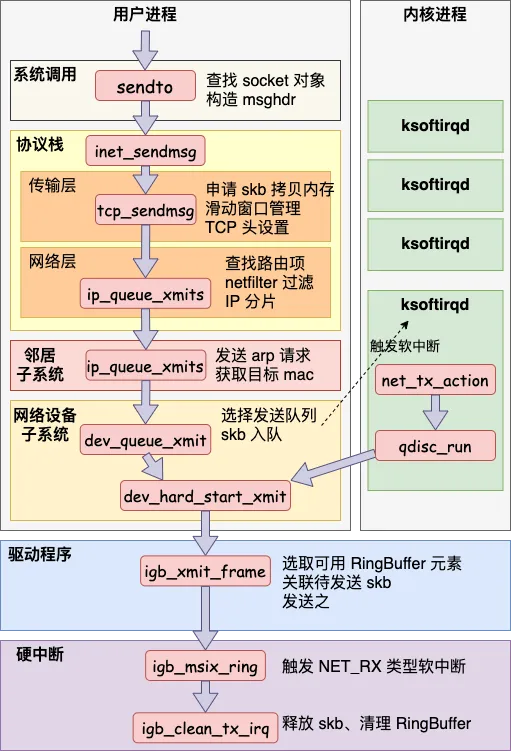
虽然堆栈和上述流程图没有全部一一对应,但总体流程差别不大,具体可查看原文及源码跟踪。
下面跟踪堆栈到内核代码里看一下。
5.2. __sys_sendto
这里的系统调用是sendto,man一下send或者sendto,可看到sendto默认后两个参数为零值时即跟send是等价的。
1
2
3
4
5
6
7
8
9
10
11
12
DESCRIPTION
The system calls send(), sendto(), and sendmsg() are used to transmit a message to
another socket.
The send() call may be used only when the socket is in a connected state (so that the
intended recipient is known). The only difference between send() and write(2) is the
presence of flags. With a zero flags argument, send() is equivalent to write(2).
Also, the following call
send(sockfd, buf, len, flags);
is equivalent to
sendto(sockfd, buf, len, flags, NULL, 0);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// linux-4.18/net/socket.c
int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags,
struct sockaddr __user *addr, int addr_len)
{
struct socket *sock;
struct sockaddr_storage address;
...
// 根据fd找到socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
...
// 调用到 sock_sendmsg
err = sock_sendmsg(sock, &msg);
...
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// linux-4.18/net/socket.c
int sock_sendmsg(struct socket *sock, struct msghdr *msg)
{
// 安全相关校验,暂不关注
int err = security_socket_sendmsg(sock, msg,
msg_data_left(msg));
return err ?: sock_sendmsg_nosec(sock, msg);
}
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg)
{
// socket注册的相应 sendmsg 函数
int ret = sock->ops->sendmsg(sock, msg, msg_data_left(msg));
BUG_ON(ret == -EIOCBQUEUED);
return ret;
}
查看af_inet.c的协议初始化,对于TCP(stream)、UDP(dgram)、RAW类型的协议,虽然sendmsg操作都初始化为inet_sendmsg,但inet_sendmsg里还有一层,里面会按具体网络协议区分处理函数。
1
2
3
4
5
6
7
// linux-4.18/net/ipv4/af_inet.c
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
...
.sendmsg = inet_sendmsg,
...
}
1
2
3
4
5
6
7
8
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
...
// sk_prot 的定义:#define sk_prot __sk_common.skc_prot(对应的结构是:struct proto *skc_prot; 这里会进行协议接口区分)
// 对于TCP协议的,此处注册为 tcp_sendmsg 接口,具体可见下面小节的梳理
return sk->sk_prot->sendmsg(sk, msg, size);
}
5.2.1. 再次分析网络协议初始化
上面sk_prot对应的具体网络协议(struct proto结构),之前梳理过流程,这里再说明一下加强印象。(初始化相关逻辑对于理清内核网络代码非常重要)
- af_inet.c中
inet_init初始化网络时,遍历inetsw_array全局数组进行各类网络协议注册 - 其中的
.prot里是具体协议,如TCP、UDP。这里的”具体协议”都是struct proto结构的实例,不同协议各自定义了一个struct proto全局变量用于注册struct proto里定义了一堆函数指针(linux-4.18/include/net/sock.h中)- 比如下面TCP协议,对应协议实例为:
struct proto tcp_prot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// linux-4.18/net/ipv4/af_inet.c
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
...
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// linux-4.18/net/ipv4/tcp_ipv4.c
// 这里是定义一个`struct proto`实例,并初始化各种操作接口,用于指代TCP协议,网络初始化时会进行注册
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
...
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
...
}
EXPORT_SYMBOL(tcp_prot);
于是,就知道上面TCP协议后面会调用到tcp_sendmsg,跟堆栈一致。
作为对比,把UDP协议实例也贴一下
1
2
3
4
5
6
7
8
9
10
11
12
13
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
.close = udp_lib_close,
.pre_connect = udp_pre_connect,
.connect = ip4_datagram_connect,
.disconnect = udp_disconnect,
...
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,
...
}
EXPORT_SYMBOL(udp_prot);
5.3. tcp_sendmsg
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// linux-4.18/net/ipv4/tcp.c
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
{
int ret;
lock_sock(sk);
ret = tcp_sendmsg_locked(sk, msg, size);
release_sock(sk);
return ret;
}
// linux-4.18/net/ipv4/tcp.c
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);
struct ubuf_info *uarg = NULL;
struct sk_buff *skb;
...
while (msg_data_left(msg)) {
int copy = 0;
// 获取发送队列
skb = tcp_write_queue_tail(sk);
if (skb)
copy = size_goal - skb->len;
...
// 只有满足下面2个条件之一,内核才会真正启动发送数据包
// 这里判断的是未发送的数据数据是否已经超过最大窗口的一半
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
...
}
...
}
上述__tcp_push_pending_frames 和 tcp_push_one 中,都会调用到 tcp_write_xmit发送数据。
5.4. tcp_write_xmit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// linux-4.18/net/ipv4/tcp_output.c
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
...
while ((skb = tcp_send_head(sk))) {
// 真正开启发送
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
...
}
}
// linux-4.18/net/ipv4/tcp_output.c
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it,
gfp_t gfp_mask)
{
return __tcp_transmit_skb(sk, skb, clone_it, gfp_mask,
tcp_sk(sk)->rcv_nxt);
}
__tcp_transmit_skb即上述调用栈中的打印的接口,逻辑如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// linux-4.18/net/ipv4/tcp_output.c
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask, u32 rcv_nxt)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet;
struct tcp_sock *tp;
struct tcp_skb_cb *tcb;
...
tp = tcp_sk(sk);
// 1.克隆新 skb 出来
if (clone_it) {
TCP_SKB_CB(skb)->tx.in_flight = TCP_SKB_CB(skb)->end_seq
- tp->snd_una;
oskb = skb;
...
skb = skb_clone(oskb, gfp_mask);
}
...
// 2.封装 TCP 头
/* Build TCP header and checksum it. */
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
...
// 3.调用网络层发送接口
err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);
...
}
5.4.1. 分析 queue_xmit 对应的注册函数
先说结果:上面queue_xmit中注册的函数是ip_queue_xmit,下面进行分析说明。
我们在”TCP半连接全连接(二) – 半连接队列代码逻辑“中梳理过,面向连接的sock相关的初始化。这里再贴一下:
inet_init初始化网络协议->注册TCP协议(struct proto tcp_prot)
注册的init接口为: .init = tcp_v4_init_sock,,其中会指定tcp协议socket连接的处理接口ipv4_specific
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// linux-5.10.10/net/ipv4/tcp_ipv4.c
static int tcp_v4_init_sock(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
tcp_init_sock(sk);
icsk->icsk_af_ops = &ipv4_specific;
#ifdef CONFIG_TCP_MD5SIG
tcp_sk(sk)->af_specific = &tcp_sock_ipv4_specific;
#endif
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// linux-5.10.10/net/ipv4/tcp_ipv4.c(之前看的是5.10内核,此处4.18结构是一样的)
const struct inet_connection_sock_af_ops ipv4_specific = {
// 发送数据的函数。用于将数据从传输层(TCP)发送到网络层(IP)
.queue_xmit = ip_queue_xmit,
// 用于计算校验和的函数
.send_check = tcp_v4_send_check,
.rebuild_header = inet_sk_rebuild_header,
.sk_rx_dst_set = inet_sk_rx_dst_set,
// 处理SYN段的函数。在TCP三次握手的开始阶段被调用,用于处理来自客户端的SYN包
.conn_request = tcp_v4_conn_request,
// 创建和初始化新socket的函数。在TCP三次握手完成后被调用,用于为新的连接创建一个传输控制块(TCB)并初始化它
.syn_recv_sock = tcp_v4_syn_recv_sock,
.net_header_len = sizeof(struct iphdr),
...
};
5.5. 网络层处理:ip_queue_xmit
在网络层里主要处理路由项查找、IP 头设置、netfilter 过滤、skb 切分(大于 MTU 的话)等几项工作,处理完这些工作后会交给更下层的邻居子系统来处理。
这里暂不细看,详情可跟着参考链接的流程分析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// linux-4.18/net/ipv4/ip_output.c
int ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl)
{
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
...
// 检查 socket 中是否有缓存的路由表;没有时会查找路由项并缓存到socket中
rt = (struct rtable *)__sk_dst_check(sk, 0);
...
// 为 skb 设置路由表
skb_dst_set_noref(skb, &rt->dst);
...
// 设置 IP 头
iph = ip_hdr(skb);
...
// 发送
res = ip_local_out(net, sk, skb);
...
}
5.6. ip_local_out:NF_INET_LOCAL_OUT hook
1
2
3
4
5
6
7
8
9
10
11
12
13
// linux-4.18/net/ipv4/ip_output.c
int ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
int err;
err = __ip_local_out(net, sk, skb);
if (likely(err == 1))
err = dst_output(net, sk, skb);
return err;
}
// 可通过kprobe跟踪到
EXPORT_SYMBOL_GPL(ip_local_out);
到这里,终于找到netfilter hook了,此处为NF_INET_LOCAL_OUT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// linux-4.18/net/ipv4/ip_output.c
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph);
/* if egress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_out(sk, skb);
if (unlikely(!skb))
return 0;
skb->protocol = htons(ETH_P_IP);
// 这里是netfilter hook:NF_INET_LOCAL_OUT
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,
net, sk, skb, NULL, skb_dst(skb)->dev,
dst_output);
}
这里再看下钩子结束后调用的dst_output
1
2
3
4
5
/* Output packet to network from transport. */
static inline int dst_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
return skb_dst(skb)->output(net, sk, skb);
}
根据eBPF追踪打印的调用栈,output对应的应该是ip_output
全局搜了下是在linux-4.18/net/ipv4/route.c的rt_dst_alloc中进行的赋值,暂不细究注册的流程
5.7. ip_output:NF_INET_POST_ROUTING hook
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// linux-4.18/net/ipv4/ip_output.c
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev;
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUT, skb->len);
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
简单看下ip_finish_output,可看到如果数据大于 MTU 的话,是会执行分片的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// linux-4.18/net/ipv4/ip_output.c
static int ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
unsigned int mtu;
int ret;
...
mtu = ip_skb_dst_mtu(sk, skb);
if (skb_is_gso(skb))
return ip_finish_output_gso(net, sk, skb, mtu);
if (skb->len > mtu || (IPCB(skb)->flags & IPSKB_FRAG_PMTU))
// ip分片
return ip_fragment(net, sk, skb, mtu, ip_finish_output2);
return ip_finish_output2(net, sk, skb);
}
5.8. 发送流程小结
基于上述流程可知,Linux在网络包发送的过程中,首先是发送的路由选择,然后碰到的第一个netfilter hook就是OUTPUT,然后接着进入POSTROUTING链。
基本流程如下图所示:
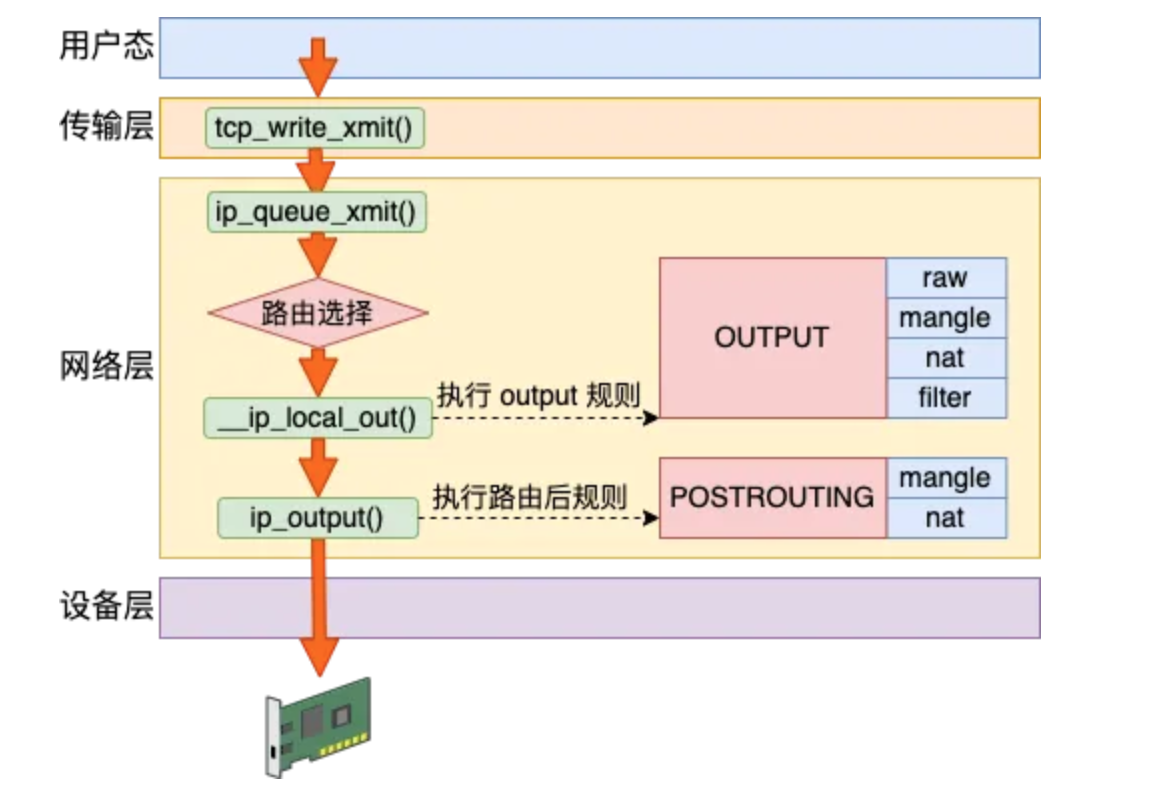
{kind=link}
6. 发送接收总体流程
转发流程我们本篇就先不看了,具体可参考”来,今天飞哥带你理解 iptables 原理!“。直接放一下其中对上述过程汇总后的总体流程。
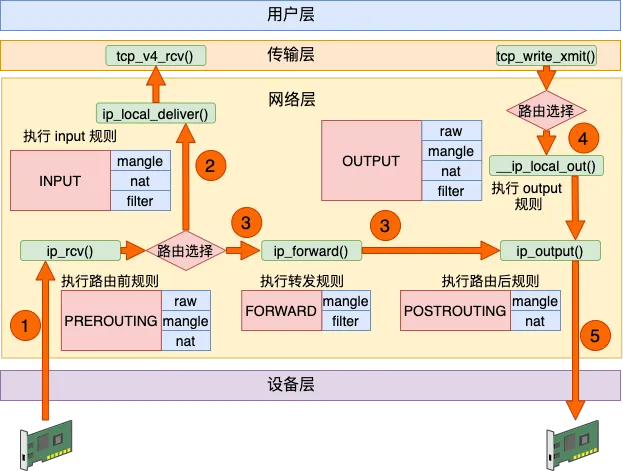
到这里,再回头看开头那张netfilter/iptables的hook点和流程(里面还包含优先级)经典配图,就清晰不少了。
7. tcpdump和netfilter说明
tcpdump是基于libpcap抓取内核态的包的,这里引出一个问题:netfilter 过滤的包 tcpdump 是否可以抓的到?
需要分发送和接收过程分别说明,这里贴一下结论,详情请参考原链接。
7.1. 接收过程
- tcpdump在
ptype_all上挂了虚拟协议,上述的__netif_receive_skb_core中会遍历ptype_all上的每个协议
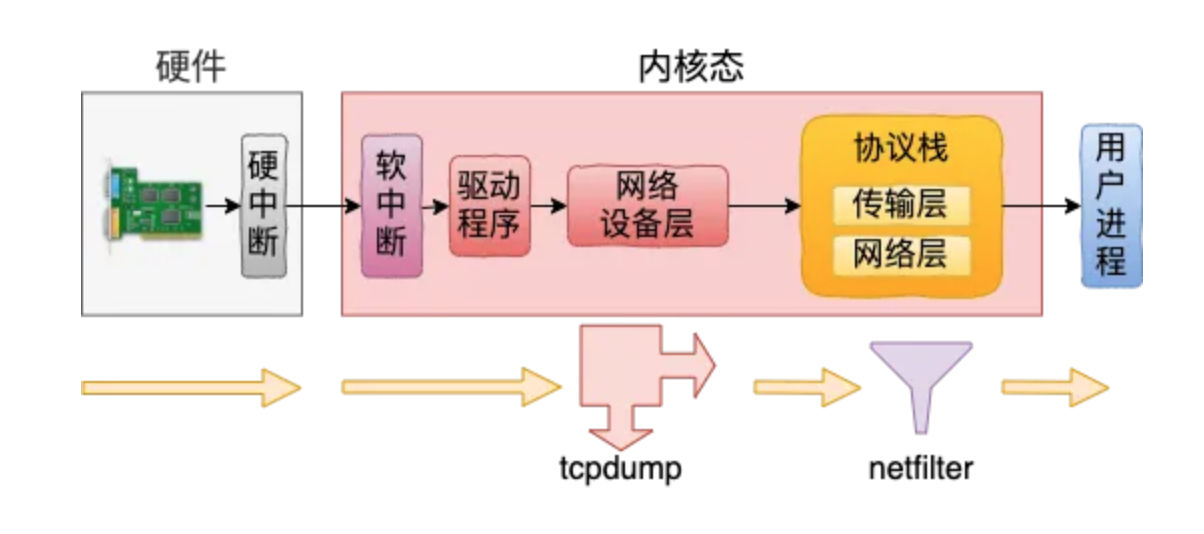
可以捕获到命中 netfilter 过滤规则的包。
7.2. 发送过程
dev_queue_xmit_nit中也会遍历 ptype_all 中的协议,会执行到 tcpdump 挂在上面的虚拟协议
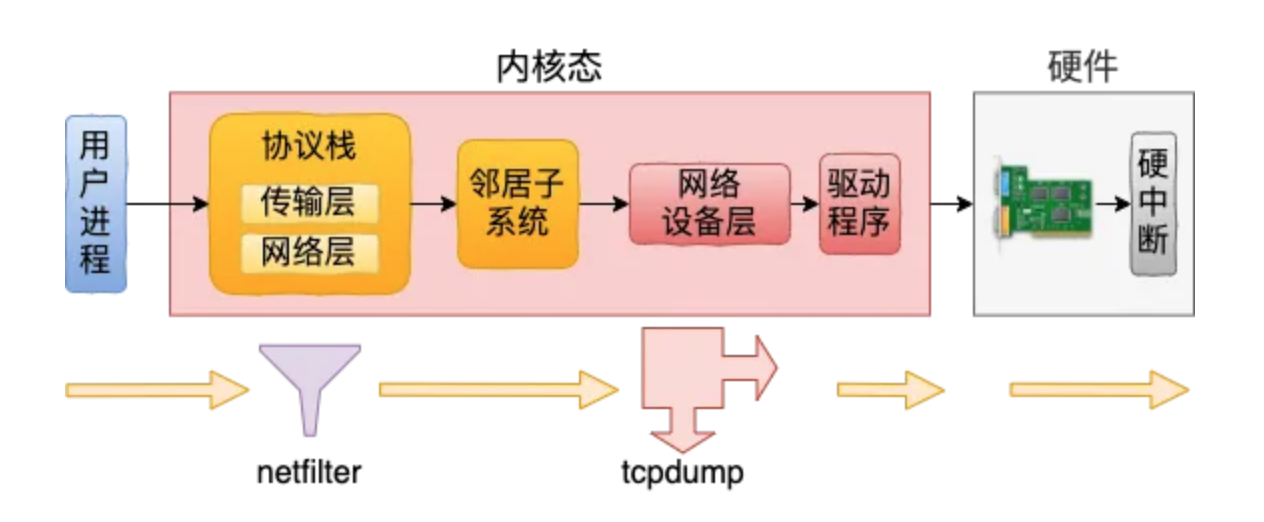
不可以捕获到 netfilter 过滤掉的包。
8. 小结
学习了解了netfilter模块功能、和iptables、tcpdump的关系,并跟踪了内核中TCP网络包接收和发送过程中涉及到的netfileter hook。
当前只是先跟踪了部分流程,并未深入探究很多详细逻辑,后续涉及细节再基于参考链接进一步学习。
9. 参考
1、[译] 深入理解 iptables 和 netfilter 架构
8、GPT