Linux存储IO栈梳理(一) -- 存储栈全貌图
Linux存储IO栈梳理学习
1. 背景
最近从LevelDB开始,梳理学习存储方面的内容。这里补充下Linux的存储栈,并贴一下CPU、磁盘、网络等的大概耗时体感图。
主要参考学习:聊聊 Linux IO
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. Linux存储栈
2.1. 存储栈全貌图
Linux内核的存储IO栈的全貌图:

这里有个简化版:
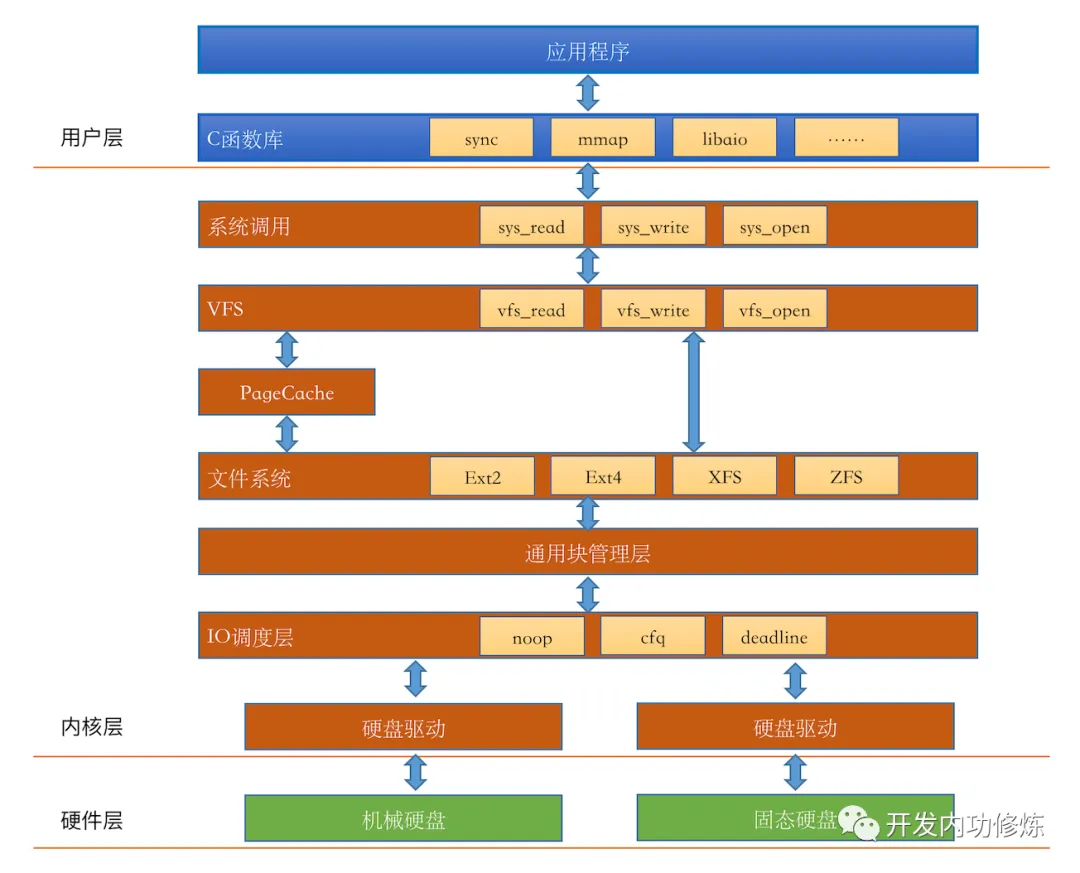
出处:read 文件一个字节实际会发生多大的磁盘IO?
注意:图中的PageCache位置其实不大准确,应该是在具体文件系统下层,其中会根据open的选项(是否指定O_DIRECT)判断是否需经过PageCache。
由图可见,从系统调用的接口再往下,Linux下的存储IO栈大致有三个层次:
文件系统层,以
write(2)为例,内核拷贝了write(2)参数指定的用户态数据到文件系统Cache中,并适时向下层同步block层,管理块设备的IO队列,对IO请求进行合并、排序
设备层,通过DMA与内存直接交互,完成数据和具体设备之间的交互
在Linux下,文件的缓存习惯性的称之为Page Cache,用于缓存文件的内容;而更低一级的设备的缓存称之为Buffer Cache,用于缓存存储设备块(比如磁盘扇区)的数据。
下面摘抄参考文章里提出的几个问题,详情请参考原链接。
2.2. Buffered IO、mmap(2)、Direct IO
Linux系统编程里用到的Buffered IO、mmap(2)、Direct IO,这些机制怎么和Linux IO栈联系起来呢?
参见下面的简图:
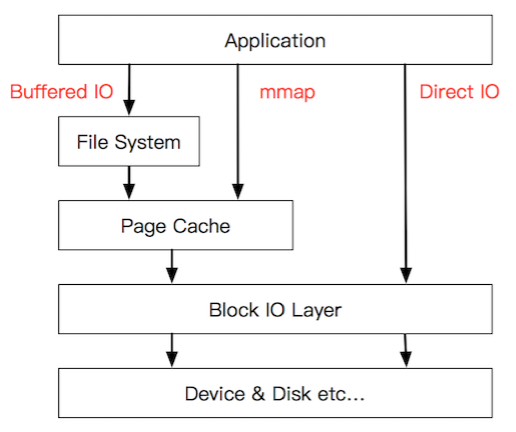
说明:参考链接里这个图中说的File System指具体的文件系统,如etx4、xfs,暂忽略了统一的VFS层;mmap和direct io等系统调用仍然是通过VFS进行IO交互的。
1、传统的Buffered IO使用read(2)读取文件的过程什么样的?
假设要去读一个冷文件(Cache中不存在),open(2)打开文件内核后建立了一系列的数据结构,接下来调用read(2),到达文件系统这一层,发现Page Cache中不存在该位置的磁盘映射,然后创建相应的Page Cache并和相关的扇区关联。
然后请求继续到达块设备层,在IO队列里排队,接受一系列的调度后到达设备驱动层,此时一般使用DMA方式读取相应的磁盘扇区到Cache中,然后read(2)拷贝数据到用户提供的用户态Buffer中去(即read(2)指定的buf,声明:ssize_t read(int fd, void *buf, size_t count);)。
2、整个过程有几次拷贝?
从磁盘到Page Cache算第一次的话,从Page Cache到用户态buffer就是第二次了。
而mmap(2)做了什么?mmap(2)直接把Page Cache映射到了用户态的地址空间里了,所以mmap(2)的方式读文件是没有第二次拷贝过程的。
那Direct IO做了什么?这个机制更狠,直接让用户态和块IO层对接,直接放弃Page Cache,从磁盘直接和用户态拷贝数据。
好处是什么?写操作直接映射进程的buffer到磁盘扇区,以DMA的方式传输数据,减少了原本需要到Page Cache层的一次拷贝,提升了写的效率。对于读而言,第一次肯定也是快于传统的方式的,但是之后的读就不如传统方式了(当然也可以在用户态自己做Cache,有些商用数据库就是这么做的)。
2.3. Page Cache的同步机制
广义上Cache的同步方式有两种,即Write Through(写穿)和Write back(写回)。
从名字上就能看出这两种方式都是从写操作的不同处理方式引出的概念(纯读的话就不存在Cache一致性了)。对应到Linux的Page Cache上:
- 所谓
Write Through就是指write(2)操作将数据拷贝到Page Cache后立即和下层进行同步的写操作,完成下层的更新后才返回。 - 而
Write back正好相反,指的是写完Page Cache就可以返回了。Page Cache到下层的更新操作是异步进行的。
Linux下Buffered IO默认使用的是Write back机制,即文件操作的写只写到Page Cache就返回,之后Page Cache到磁盘的更新操作是异步进行的。
Page Cache中被修改的内存页称之为脏页(Dirty Page),脏页在特定的时候被一个叫做pdflush(Page Dirty Flush)的内核线程写入磁盘。写入的时机和条件如下:
- 当空闲内存低于一个特定的阈值时,内核必须将脏页写回磁盘,以便释放内存。 (
vm.dirty_background_ratio) - 当脏页在内存中驻留时间超过一个特定的阈值时,内核必须将超时的脏页写回磁盘。 (
vm.dirty_expire_centisecs) - 用户进程调用
sync(2)、fsync(2)、fdatasync(2)系统调用时,内核会执行相应的写回操作。
默认是写回方式,如果想指定某个文件是写穿方式呢?除了fsync(2)之类的系统调用外,在open(2)打开文件时,传入O_SYNC这个flag即可实现。
2.4. 文件操作与锁
当多个进程/线程对同一个文件发生写操作的时候会发生什么?如果写的是文件的同一个位置呢?
首先write(2)调用不是原子操作。当多个write(2)操作对一个文件的同一部分发起写操作的时候,情况实际上和多个线程访问共享的变量没有什么区别。按照不同的逻辑执行流,会有很多种可能的结果。也许大多数情况下符合预期,但是本质上这样的代码是不可靠的。
特别的:文件操作中有两个操作是内核保证原子的,分别是open(2)调用的O_CREAT和O_APPEND这两个flag属性。
Linux下的文件锁有两种,分别是flock(2)的方式和fcntl(2)的方式,前者源于BSD,后者源于System V,各有限制和应用场景。
3. 耗时体感
注意:下面的各时延数据仅作参考,随着硬件等基础设施的更新迭代,数据也会不同,此处关注大概数量级即可。
CPU、磁盘、网络的耗时体感:
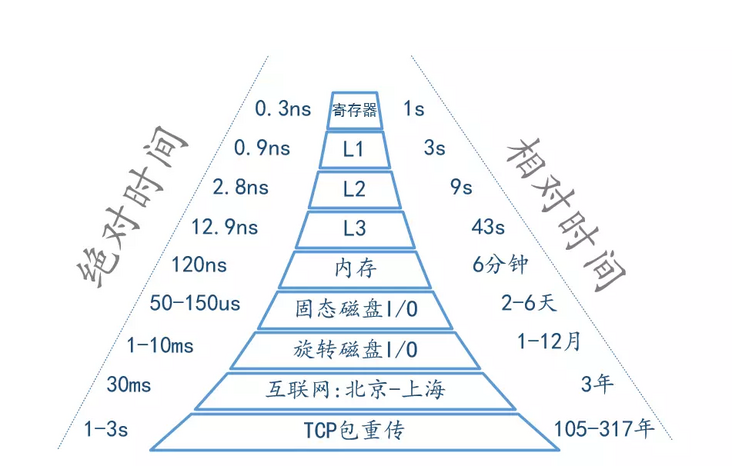
还有一些其他的时延数据供参考。以下这组数字,来自于Jeff Dean在Google的Engineering All-Hands Meeting上的演讲。
- 访问L1缓存:0.5ns;
- 分支预测失败:5ns;
- 访问L2缓存:7ns;
- 对互斥量(Mutex)的加锁/解锁:100ns;
- 内存访问:100ns;
- 使用Zippy压缩1KB数据:10,000ns = 10us;
- 通过1Gbps的网络发送2KB数据:20,000ns = 20us = 0.02ms;(1MB数据:10ms)
- 从内存中顺序读取1MB数据:250,000ns = 250us = 0.25ms;
- 同一个数据中心的RTT(往返时间):500,000ns = 500us = 0.5ms;
- 磁盘寻道:10,000,000ns = 10ms;
- 从网络中顺序读取1MB数据:10,000,000ns = 10ms;
- 从磁盘中顺序读取1MB数据:30,000,000ns = 30ms;
- 发送一个包,从加拿大到荷兰的RTT:150,000,000ns = 150ms;
《性能之巅》中的时延(或称延时)列举:
- 系统中的各种时延
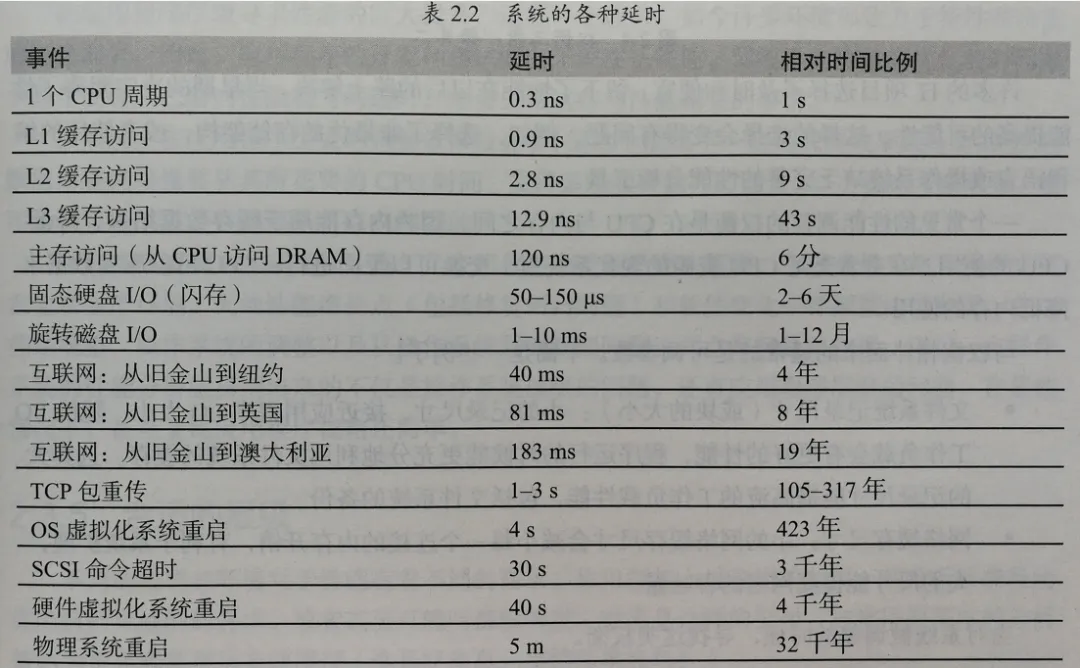
- 磁盘IO时延

4. 扩展了解
4.1. 机械硬盘结构
机械硬盘结构:
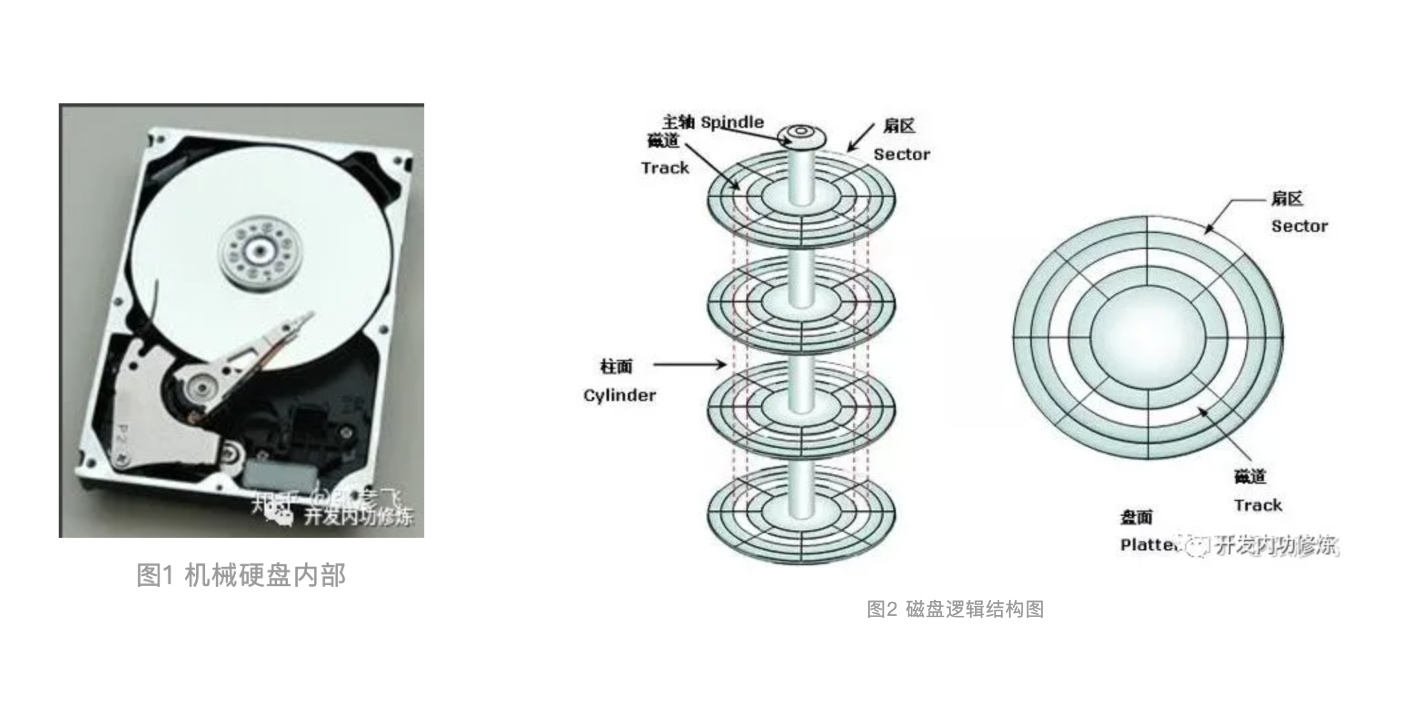
一些概念:
- 磁盘面:磁盘是由一叠磁盘面叠加组合构成,每个磁盘面上都会有一个磁头负责读写。
- 磁道(Track):每个盘面会围绕圆心划分出多个同心圆圈,每个圆圈叫做一个磁道。
- 柱面(Cylinders):所有盘片上的同一位置的磁道组成的立体叫做一个柱面。
- 扇区(Sector):以磁道为单位管理磁盘仍然太大,所以计算机前辈们又把每个磁道划分出了多个扇区。
磁盘存储的最小组成单位就是扇区。
单柱面的存储容量 = 每个扇区的字节数 * 每柱面扇区数 * 磁盘面数
整体磁盘的容量 = 单柱面容量 * 总的柱面数字
4.2. 固态硬盘结构
参考:拆解固态硬盘结构
固态硬盘结构:
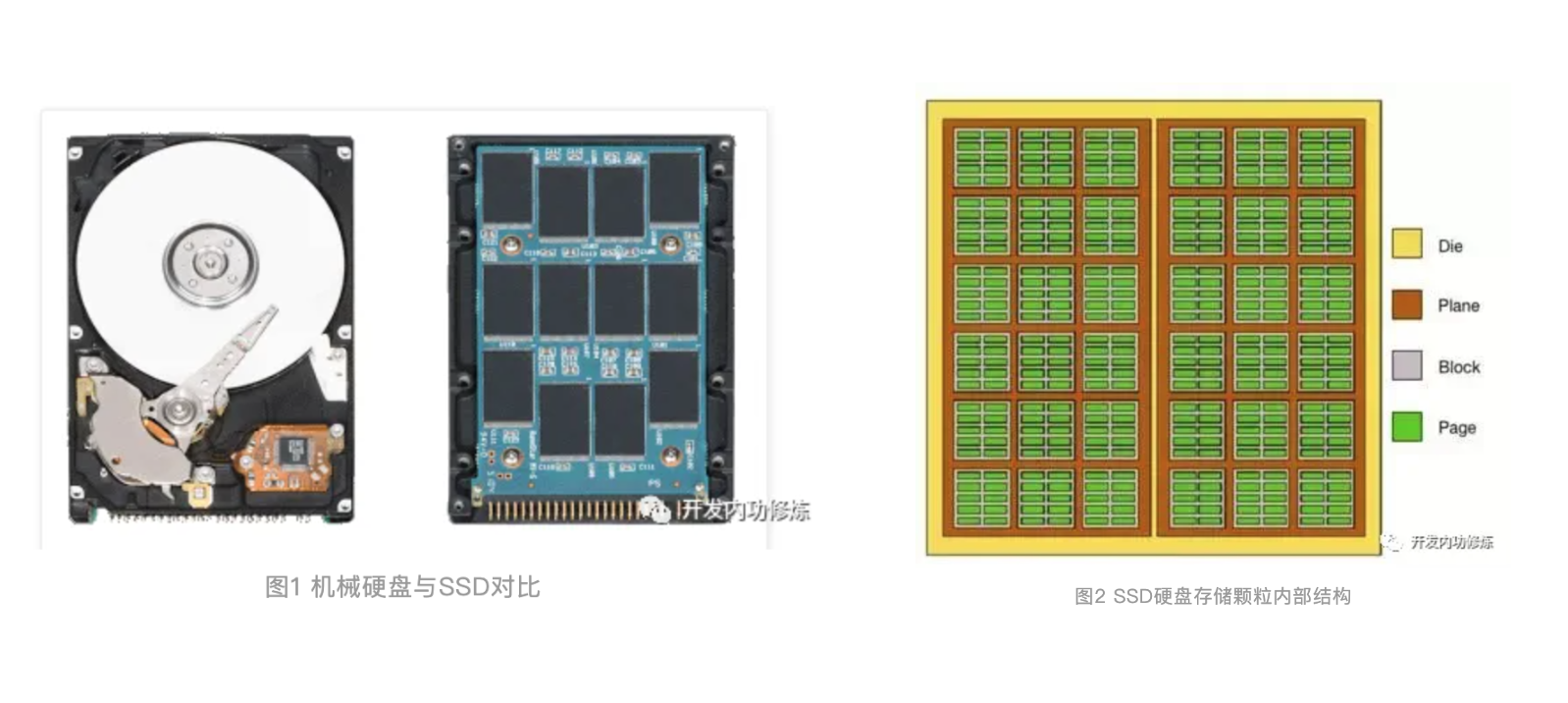
不像机械硬盘里的一摞子圆形碟片,SSD是由一些电路和黑色的存储颗粒构成。SSD硬盘是基于NAND Flash存储技术的,属于非易失性存储设备,换成人话说,就是掉电了数据不会丢。其中每一个黑色的存储颗粒也叫做一个Die。
每个Die有若干个Plane,每个Plane有若干个Block,每个Block有若干个Page。Page是磁盘进行读写的最小单位,一般为2KB/4KB/8KB/16KB等。
4.3. IOPS和读写速度参考
机械硬盘 (HDD) 和固态硬盘 (SSD) 的I/O和读写速度存在明显的差异,以下是两者的大致性能指标(GPT提供,供参考)。
机械硬盘 (HDD):
机械硬盘因为其旋转磁盘和机械臂的物理结构,导致其在随机访问性能方面大大低于固态硬盘。但它们在顺序读取和写入操作中仍然具有一定的优势。HDD通常用于存储大量数据的应用环境,如大文件存储和备份。
- 顺序速度:
- 顺序读取速度: 80到160 MB/s
- 顺序写入速度: 80到160 MB/s
- 随机速度:
- 随机读取速度: 0.5到2 MB/s
- 随机写入速度: 0.5到2 MB/s
- 由于机械臂和磁盘的特性,HDD在处理大量小文件时效率较低。
- IOPS (Input/Output Operations Per Second):
- 随机读取IOPS: 75到150 IOPS
- 随机写入IOPS: 75到150 IOPS
- 相比SSD,HDD的随机I/O性能较差。
固态硬盘 (SSD):
固态硬盘采用闪存存储,大大提升了数据传输速度及随机访问性能。根据接口类型(SATA或NVMe),SSD在各项性能指标上有所不同。SSD的高性能使其非常适合操作系统、应用程序及高需求的游戏存储。
- 顺序速度:
- SATA接口SSD:
- 顺序读取速度: 大约500到550 MB/s
- 顺序写入速度: 大约450到500 MB/s
- SATA接口由于受到接口带宽限制,性能有限。
- NVMe接口SSD:
- 顺序读取速度: 2000到3500+ MB/s
- 顺序写入速度: 1500到3000+ MB/s
- NVMe通过PCIe高速通道,显著提高性能。高端型号甚至超过3500 MB/s的读取速度。
- SATA接口SSD:
- 随机速度:
- SATA接口SSD:
- 随机读取速度: 25到50 MB/s
- 随机写入速度: 10到40 MB/s
- NVMe接口SSD:
- 随机读取速度: 50到100 MB/s
- 随机写入速度: 50到100 MB/s
- 高IOPS性能使其在处理小文件和大量随机操作时表现优异。
- SATA接口SSD:
- IOPS (Input/Output Operations Per Second):
- SATA接口SSD:
- 随机读取IOPS: 75,000到100,000 IOPS
- 随机写入IOPS: 70,000到90,000 IOPS
- NVMe接口SSD:
- 随机读取IOPS: 250,000到500,000 IOPS
- 随机写入IOPS: 200,000到450,000 IOPS
- NVMe接口SSD在高需求应用中以其卓越的IOPS性能脱颖而出。
- SATA接口SSD:
一些数据出处可参考:
- 硬盘厂商:Seagate、Western Digital等硬盘厂商的官方技术规格。
- SSD厂商:Samsung、Western Digital、Crucial等SSD制造商的官方数据。
- 评测网站:Tom’s Hardware, AnandTech, TechRadar等提供的性能评测数据。
比如搜索”Seagate BarraCuda 计算硬盘数据表”,可找到下面两份datasheets:
5. 小结
学习了Linux存储IO栈,文件IO和存储栈的对应关系,大概对比了解了CPU、磁盘、网络等的时延情况,并简单了解了机械硬盘和固态硬盘结构。