LevelDB学习笔记(三) -- 日志结构实现
LevelDB学习笔记,本篇学习日志结构对应的实现。
1. 背景
前面跟踪学习了读写实现的基本流程,此篇开始学习梳理其中具体的流程实现。本篇先看日志结构对应的实现细节。
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 日志相关操作
2.1. 再看下总体流程
前面看过了写流程,这里再放一下:
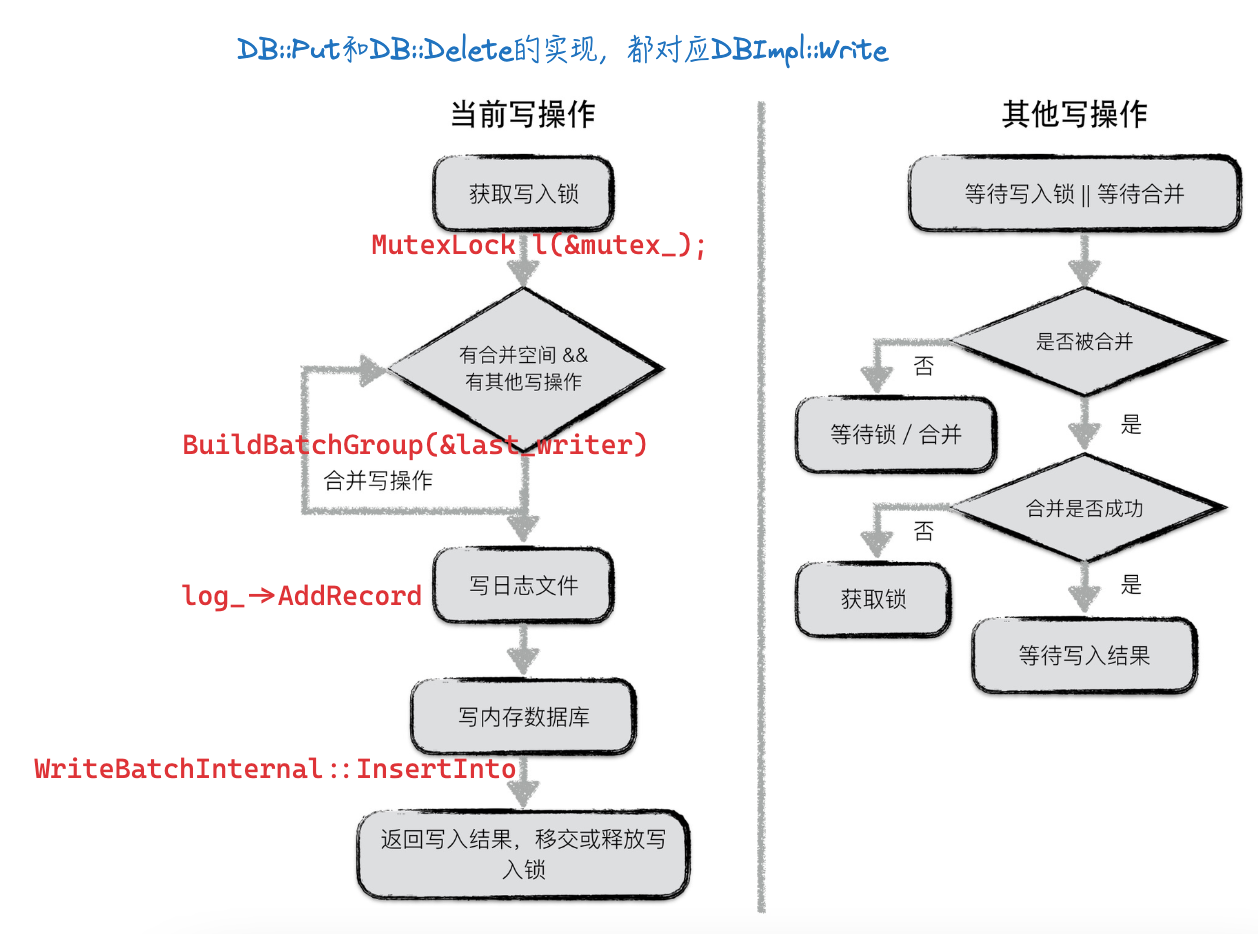
如上,为了避免断电、程序崩溃等异常导致丢数据,写memtable之前会先写日志。
在LevelDB中,有两个memory db,以及对应的两份日志文件。两个memory db即下面定义中的mem_和imm_;日志文件为log_,也会对应immutable memtable有个不可修改的log实例。
2.2. 日志文件初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// db/db_impl.h
class DBImpl : public DB {
...
// 内存态的表
MemTable* mem_;
// 内存态的表,不可修改
MemTable* imm_ GUARDED_BY(mutex_); // Memtable being compacted
std::atomic<bool> has_imm_; // So bg thread can detect non-null imm_
// 此处表示日志文件,具体内容在实现类中(linux下为PosixWritableFile)
WritableFile* logfile_;
uint64_t logfile_number_ GUARDED_BY(mutex_);
// 日志文件对于的写操作对象,该对象操作都体现在 logfile_ 对应文件上
log::Writer* log_;
...
};
上述log_和logfile_成员是在LevelDB数据库Open时初始化的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// db/db_impl.cc
Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr) {
// Open的时候会初始化DBImpl相关内容
DBImpl* impl = new DBImpl(options, dbname);
...
Status s = impl->Recover(&edit, &save_manifest);
if (s.ok() && impl->mem_ == nullptr) {
uint64_t new_log_number = impl->versions_->NewFileNumber();
WritableFile* lfile;
// linux下env对应posix文件io接口,此处新建一个文件
s = options.env->NewWritableFile(LogFileName(dbname, new_log_number), &lfile);
if (s.ok()) {
edit.SetLogNumber(new_log_number);
// 初始化日志文件 logfile_
impl->logfile_ = lfile;
impl->logfile_number_ = new_log_number;
// 初始化日志文件对于的写操作对象log_,该对象操作都体现在 logfile_ 对应文件上
impl->log_ = new log::Writer(lfile);
// mem_ 为空则new进行实例化
impl->mem_ = new MemTable(impl->internal_comparator_);
impl->mem_->Ref();
}
}
...
}
2.3. 写流程中的日志操作
主要写流程操作如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
// db/db_impl.cc
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
...
MutexLock l(&mutex_);
// 要写入的数据,由Writer封装后先放到队列尾部
// 这里的writers_是 std::deque 双端队列,存放Writer*
writers_.push_back(&w);
...
// 申请写入的空间,里面会检查是否需要转换memtable、是否需要压缩
// 声明为:Status DBImpl::MakeRoomForWrite(bool force),updates为nullptr时压缩处理
// 调用 MakeRoomForWrite 前必定已持锁,里面会断言判断
Status status = MakeRoomForWrite(updates == nullptr);
uint64_t last_sequence = versions_->LastSequence();
// 待写入数据
Writer* last_writer = &w;
if (status.ok() && updates != nullptr) {
// 合并写操作,要合并的对象是 writers_ 对应的 Writer 双端队列
WriteBatch* write_batch = BuildBatchGroup(&last_writer);
...
{
mutex_.Unlock();
// 合并后的记录,写WAL预写日志
// Contents 用于获取WriteBatch里面的内容,多条记录按batch格式组织
status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));
...
if (status.ok()) {
// 写memtable,write_batch写到传入的 mem_ 里
status = WriteBatchInternal::InsertInto(write_batch, mem_);
}
mutex_.Lock();
...
}
...
}
...
}
其中涉及写日志的逻辑,leveldb::log::Writer实现写journal(日志)的writer:
1
2
3
4
5
6
7
8
9
10
11
12
13
// db/log_writer.cc
Status Writer::AddRecord(const Slice& slice) {
const char* ptr = slice.data();
size_t left = slice.size();
...
// 循环写 dest_(定义为`WritableFile* dest_;`)
do {
dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
...
s = EmitPhysicalRecord(type, ptr, fragment_length);
...
} while(s.ok() && left > 0);
}
涉及日志转换和memtable/immutable memtable转换操作,逻辑在MakeRoomForWrite函数中,放到memtable里去说明。
2.4. 写日志逻辑
为便于理解,我们把上面的AddRecord全部展开,并添加注释。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
// db/log_writer.cc
Status Writer::AddRecord(const Slice& slice) {
const char* ptr = slice.data();
size_t left = slice.size();
// Fragment the record if necessary and emit it. Note that if slice
// is empty, we still want to iterate once to emit a single
// zero-length record
Status s;
bool begin = true;
// 循环写 dest_(定义为`WritableFile* dest_;`)
// 一条日志记录可能包含多个block,一个block包含一个或多个完整的chunk。
// 可查看日志结构[示意图](https://leveldb-handbook.readthedocs.io/zh/latest/_images/journal.jpeg)
do {
// 日志文件中按照block进行划分,每个block的大小为32KiB,32KB对齐这是为了提升读取时的效率
// kBlockSize默认为32KB,block_offset_在下面的 EmitPhysicalRecord 里会赋值 fragment_length+头长度,表示数据偏移
const int leftover = kBlockSize - block_offset_;
assert(leftover >= 0);
if (leftover < kHeaderSize) {
// 一个block里剩余不足写7字节头,则填充空字符
// Switch to a new block
if (leftover > 0) {
// Fill the trailer (literal below relies on kHeaderSize being 7)
static_assert(kHeaderSize == 7, "");
// 小数据写buffer,大数据直接::write写盘
dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
}
// 32KB后重置偏移,重新写一个block
block_offset_ = 0;
}
// 断言:block里剩余的空间肯定 >= 7字节,留空间给下面的写入 (block剩余空间即kBlockSize - block_offset_)
// Invariant: we never leave < kHeaderSize bytes in a block.
assert(kBlockSize - block_offset_ - kHeaderSize >= 0);
// 剩余可以给数据用的空间(头占有的7字节预留好了)
const size_t avail = kBlockSize - block_offset_ - kHeaderSize;
// 若要写的数据 < block剩余空间,写要写的数据长度
// 若要写的数据 >= block剩余空间,写block剩余空间(可能只写个头,数据为0长度)
const size_t fragment_length = (left < avail) ? left : avail;
RecordType type;
// 根据 写的数据 和 block剩余空间的关系,判断chunk所处位置是 开始/结束/中间/满
const bool end = (left == fragment_length);
if (begin && end) {
type = kFullType;
} else if (begin) {
type = kFirstType;
} else if (end) {
type = kLastType;
} else {
type = kMiddleType;
}
// 里面涉及组装日志结构:7字节大小的header + 数据(数据可能为0字节)
s = EmitPhysicalRecord(type, ptr, fragment_length);
ptr += fragment_length;
left -= fragment_length;
begin = false;
} while (s.ok() && left > 0);
return s;
}
2.5. 写日志流程图
上述逻辑对应逻辑图,即:
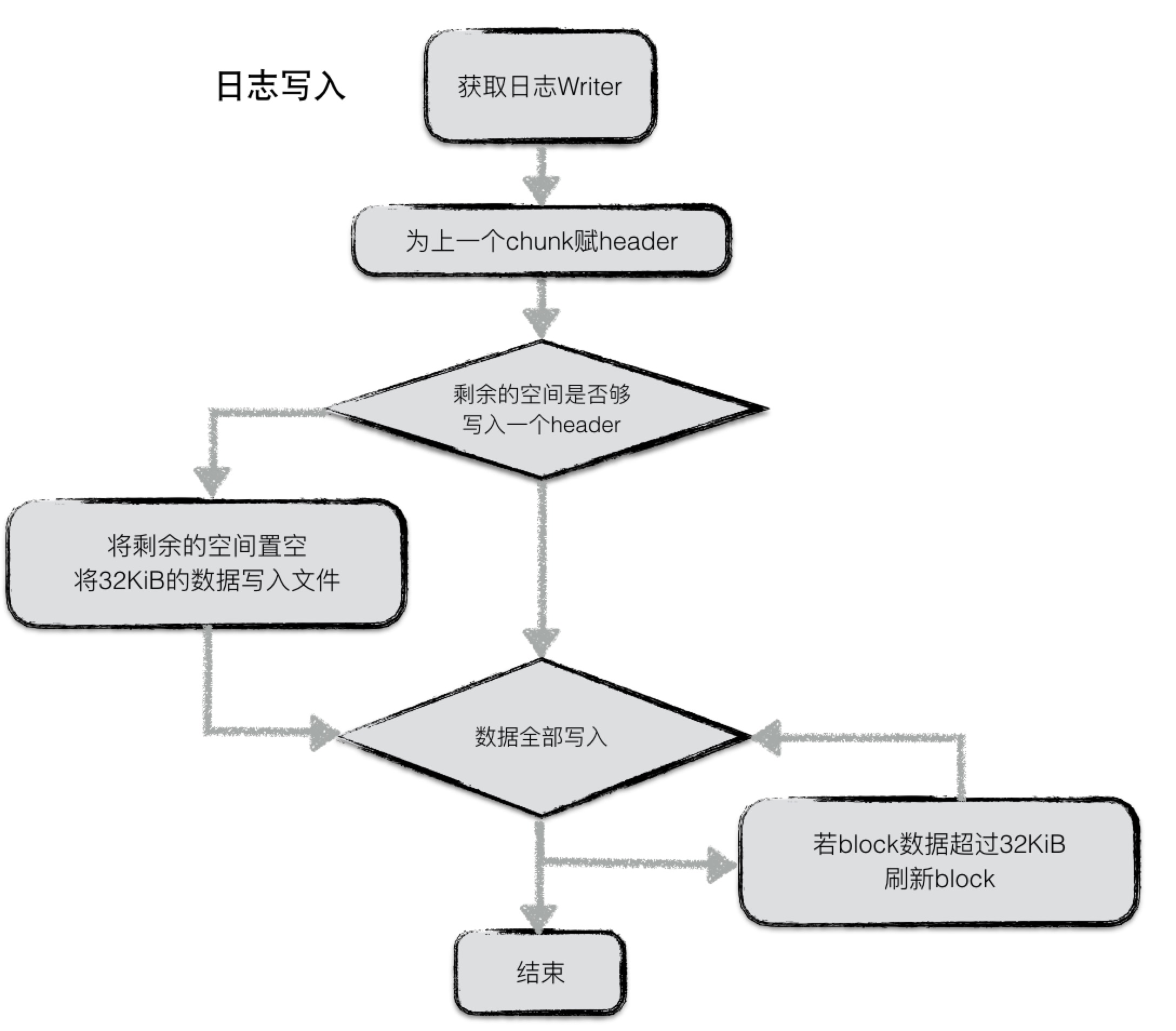
在写入的过程中,不断判断writer中buffer的大小,若超过32KiB,将chunk开始到现在做为一个完整的chunk,为其计算header之后将整个chunk写入文件。与此同时reset buffer,开始新的chunk的写入。
若一条journal记录较大,则可能会分成几个chunk存储在若干个block中。
3. 日志结构
3.1. EmitPhysicalRecord:日志结构组装
写日志时的EmitPhysicalRecord中,涉及组装日志结构,具体组装方式见代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// db/log_writer.cc
Status Writer::EmitPhysicalRecord(RecordType t, const char* ptr,
size_t length) {
assert(length <= 0xffff); // Must fit in two bytes
assert(block_offset_ + kHeaderSize + length <= kBlockSize);
// 每个chunk包含了一个7字节大小的header,前4字节是该chunk的校验码,紧接的2字节是该chunk数据的长度,以及最后一个字节是该chunk的类型。
// 可查看日志结构[示意图](https://leveldb-handbook.readthedocs.io/zh/latest/_images/journal.jpeg)
// Format the header
char buf[kHeaderSize];
buf[4] = static_cast<char>(length & 0xff);
buf[5] = static_cast<char>(length >> 8);
buf[6] = static_cast<char>(t);
// Compute the crc of the record type and the payload.
// 计算 数据+类型 对应的 CRC
uint32_t crc = crc32c::Extend(type_crc_[t], ptr, length);
crc = crc32c::Mask(crc); // Adjust for storage
EncodeFixed32(buf, crc);
// Write the header and the payload
// 写7字节大小的header 到 dest_,buffer够则只写buffer
Status s = dest_->Append(Slice(buf, kHeaderSize));
if (s.ok()) {
// 写 数据 到 dest_,buffer够则只写buffer
s = dest_->Append(Slice(ptr, length));
if (s.ok()) {
// 系统::write接口写磁盘(里面并不会调::flush)
s = dest_->Flush();
}
}
block_offset_ += kHeaderSize + length;
return s;
}
3.2. 落盘时机:dest_->Append
dest_对应的类结构为PosixWritableFile,成员变量如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
// util/env_posix.cc
class PosixWritableFile final : public WritableFile {
...
// buf_[0, pos_ - 1] contains data to be written to fd_.
// kWritableFileBufferSize定义为 65536 的const变量,即此处buffer为64KB
char buf_[kWritableFileBufferSize];
size_t pos_;
int fd_;
const bool is_manifest_; // True if the file's name starts with MANIFEST.
const std::string filename_;
const std::string dirname_; // The directory of filename_.
}
上面写记录时,EmitPhysicalRecord会调用dest_->Append,其逻辑如下:
- buffer总大小为64KB,先往buffer剩余空间写,若buffer剩余空间足够写入当前日志数据,则写buffer后退出
- 若buffer剩余空间不足以写满,则将buffer数据::write落盘后,剩余数据再判断写入:
- 若剩余<64KB,则写buffer并退出;
- 若剩余>=64KB,则直接::write落盘
下面是具体代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// util/env_posix.cc,PosixWritableFile 类的成员函数
Status Append(const Slice& data) override {
size_t write_size = data.size();
const char* write_data = data.data();
// Fit as much as possible into buffer.
// 若要写的数据 > buffer还剩下的空间,先写满剩下的空间
size_t copy_size = std::min(write_size, kWritableFileBufferSize - pos_);
std::memcpy(buf_ + pos_, write_data, copy_size);
write_data += copy_size;
write_size -= copy_size;
pos_ += copy_size;
// 此处说明buffer剩余空间足够写入本次数据,写入buffer后直接退出
if (write_size == 0) {
return Status::OK();
}
// 到这里说明只写了一部分数据,buffer已经满了,调一次 ::write 写盘
// Can't fit in buffer, so need to do at least one write.
Status status = FlushBuffer();
if (!status.ok()) {
return status;
}
// 剩余要写入的数据,不足64KB则写buffer后退出,否则直接::write写盘(操作系统的page cache等不关注)
// Small writes go to buffer, large writes are written directly.
if (write_size < kWritableFileBufferSize) {
std::memcpy(buf_, write_data, write_size);
pos_ = write_size;
return Status::OK();
}
return WriteUn
3.3. 日志结构示意图
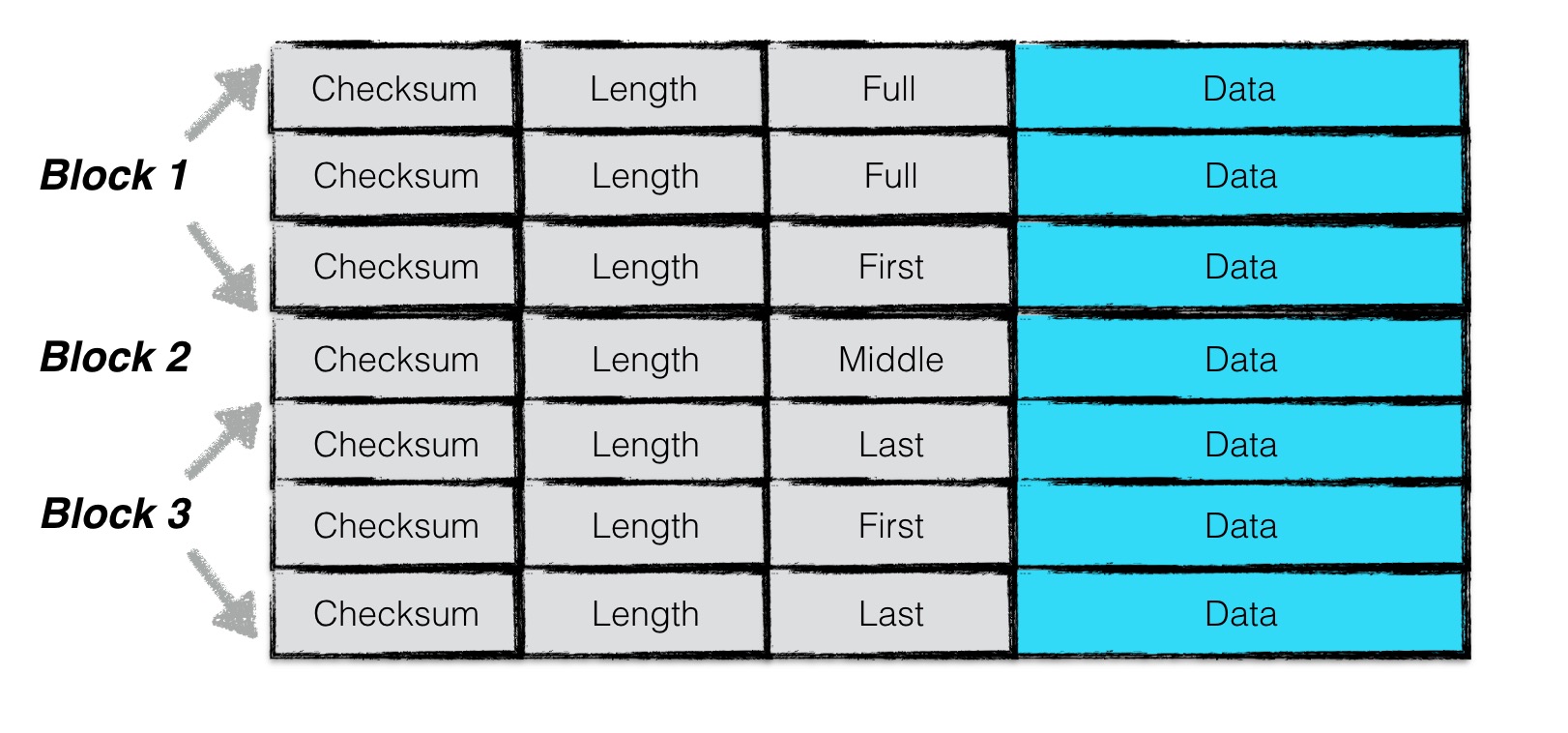
上面代码注释也是映证示意图梳理的,通过代码去反看设计的方式比较费劲且需要抽象,还是先理解设计然后映证代码实现更轻松一些。
贴一下参考链接的结构说明,对照代码就比较清晰了:
一条日志记录包含一个或多个chunk。每个chunk包含了一个7字节大小的header,前4字节是该chunk的校验码,紧接的2字节是该chunk数据的长度,以及最后一个字节是该chunk的类型。其中checksum校验的范围包括chunk的类型以及随后的data数据。
chunk共有四种类型:full,first,middle,last。一条日志记录若只包含一个chunk,则该chunk的类型为full。若一条日志记录包含多个chunk,则这些chunk的第一个类型为first, 最后一个类型为last,中间包含大于等于0个middle类型的chunk。
由于一个block的大小为32KiB,因此当一条日志文件过大时,会将第一部分数据写在第一个block中,且类型为first,若剩余的数据仍然超过一个block的大小,则第二部分数据写在第二个block中,类型为middle,最后剩余的数据写在最后一个block中,类型为last。
4. 日志内容(Data)
日志的内容为写入的batch编码后的信息。
上述要写的日志,即示意图中的Data(不包含7字节的header),在WriteBatchInternal::Contents(write_batch)里构造。
上篇中可知write_batch(类型为WriteBatch*)对应的编码格式如下(以Put为例,Delete则没有value对应信息):

日志内容格式如下:

WriteBatch中rep_的第一个字节即编码得到的sequence number
entry number在哪里体现的?(TODO)
5. 小结
学习日志结构的实现细节。
6. 参考
1、leveldb
3、GPT