LevelDB学习笔记(五) -- sstable实现
LevelDB学习笔记,本篇学习sstable实现。
1. 背景
继续学习梳理LevelDB中具体的流程,本篇来看下sstable(Sorted String Table)实现。
跟着 leveldb-handbook sstable 映证代码进行学习梳理。
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. SStable文件格式
物理结构:一个sstable文件按照固定大小进行块划分,默认每个块(block)的大小为4KB,block中除了存储数据外,还存储了压缩类型和CRC校验码(用于校验数据+压缩类型)两个辅助字段。
逻辑结构总体示意图如下:

出处,在此基础上添加说明
- 1、
data block中存储的数据是LevelDB中的keyvalue键值对。- 由于sstable中所有的keyvalue对都是严格按序存储的,为了节省存储空间,LevelDB并不会为每一对keyvalue对都存储完整的key值,而是存储与上一个key非共享的部分,避免了key重复内容的存储。
- 2、
filter block存储的是data block数据的一些过滤信息,这里基于布隆过滤器实现。 - 3、
meta index block用来存储filter block在整个sstable中的索引信息。 - 4、
index block用来存储所有data block的相关索引信息(与meta index block类似)。 - 5、
footer大小固定,为48字节,用来存储meta index block与index block在sstable中的索引信息,另外尾部还会存储一个magic word,内容为:“http://code.google.com/p/leveldb/”字符串sha1哈希的前8个字节。
1~5还是block数据,也遵照上述的物理结构,block里会包含压缩类型和CRC校验码。
下面简要看下逻辑结构的各部分内容组成,详情可参考原链接的说明:leveldb-handbook sstable
2.1. data block结构
data block结构见上述总体示意图。
block相关结构定义在BlockBuilder中:
1
2
3
4
5
6
7
8
9
10
11
// table/block_builder.h
class BlockBuilder {
...
private:
const Options* options_;
std::string buffer_; // Destination buffer
std::vector<uint32_t> restarts_; // Restart points
int counter_; // Number of entries emitted since restart
bool finished_; // Has Finish() been called?
std::string last_key_;
}
上图对应操作则可见BlockBuilder::Add:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// table/block_builder.cc
void BlockBuilder::Add(const Slice& key, const Slice& value) {
...
// Add "<shared><non_shared><value_size>" to buffer_
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
// Add string delta to buffer_ followed by value
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());
// Update state
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
assert(Slice(last_key_) == key);
counter_++;
}
2.2. filter block结构
filter block中存储的数据包含两部分:过滤数据 和 索引数据。
filter i offset表示第i个filter data在整个filter block中的起始偏移量filter offset's offset表示filter block的索引数据在filter block中的偏移量- 读取流程:先读取
filter offset's offset-> 而后依次读取filter i offset-> 再根据这些offset读取filter data Base Lg默认值为11,表示每2KB的数据,创建一个新的过滤器来存放过滤数据。
结构定义:
1
2
3
4
5
6
7
8
9
10
11
// table/filter_block.h
class FilterBlockBuilder {
...
const FilterPolicy* policy_;
std::string keys_; // Flattened key contents
std::vector<size_t> start_; // Starting index in keys_ of each key
// 布隆过滤器数据
std::string result_; // Filter data computed so far
std::vector<Slice> tmp_keys_; // policy_->CreateFilter() argument
std::vector<uint32_t> filter_offsets_;
};
1
2
3
4
5
6
// table/filter_block.cc
void FilterBlockBuilder::AddKey(const Slice& key) {
Slice k = key;
start_.push_back(keys_.size());
keys_.append(k.data(), k.size());
}
2.3. meta index block结构
meta index block中只存储一条记录:filter block在sstable中的索引信息序列化后的内容。
2.4. index block结构
index block用来存储所有data block的相关索引信息,包含多条记录,示意图见上面的总体示意图。
2.5. footer结构
footer大小固定,为48字节,用来存储meta index block与index block在sstable中的索引信息,另外尾部还会存储一个magic word。
3. memtable 转换处理
前面讲写流程时没展开MakeRoomForWrite看,对应的memtable写sstable的转换就在该接口中。先简单贴下写接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// db/db_impl.cc
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
...
MutexLock l(&mutex_);
// 要写入的数据,由Writer封装后先放到队列尾部
// 这里的writers_是 std::deque 双端队列,存放Writer*
writers_.push_back(&w);
...
// 申请写入的空间,里面会检查是否需要转换memtable、是否需要合并
// 声明为:Status DBImpl::MakeRoomForWrite(bool force),updates为nullptr时合并处理
// 调用 MakeRoomForWrite 前必定已持锁,里面会断言判断
Status status = MakeRoomForWrite(updates == nullptr);
uint64_t last_sequence = versions_->LastSequence();
...
// 写journal、写memtable
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
// db/db_impl.cc
Status DBImpl::MakeRoomForWrite(bool force) {
// 要求外面肯定是持锁的,这里加了断言
mutex_.AssertHeld();
assert(!writers_.empty());
bool allow_delay = !force;
Status s;
while (true) {
if (!bg_error_.ok()) {
// Yield previous error
s = bg_error_;
break;
} else if (allow_delay && versions_->NumLevelFiles(0) >=
config::kL0_SlowdownWritesTrigger) {
// 若Level0的文件数超出限制(默认为8),则不延迟写
mutex_.Unlock();
// 等待过程不要持锁
env_->SleepForMicroseconds(1000);
// 由于当前在while(true)循环体中,下次就不会进入该语句块了
allow_delay = false; // Do not delay a single write more than once
mutex_.Lock();
} else if (!force &&
(mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) {
// 若memtable中内存还够用,则不需要申请新的memtable
// There is room in current memtable
break;
} else if (imm_ != nullptr) {
// We have filled up the current memtable, but the previous
// one is still being compacted, so we wait.
// 若immutable memtable还没完成合并,则等待
Log(options_.info_log, "Current memtable full; waiting...\n");
background_work_finished_signal_.Wait();
} else if (versions_->NumLevelFiles(0) >= config::kL0_StopWritesTrigger) {
// There are too many level-0 files.
// level0层的文件数超出限制(默认12个),等待
Log(options_.info_log, "Too many L0 files; waiting...\n");
background_work_finished_signal_.Wait();
} else {
// Attempt to switch to a new memtable and trigger compaction of old
// 到这里才需要申请新的空间:memtable(原来的memtable移动到immutable memtable)
assert(versions_->PrevLogNumber() == 0);
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile* lfile = nullptr;
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
if (!s.ok()) {
// Avoid chewing through file number space in a tight loop.
versions_->ReuseFileNumber(new_log_number);
break;
}
delete log_;
// 关闭原来的log文件
s = logfile_->Close();
if (!s.ok()) {
RecordBackgroundError(s);
}
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
log_ = new log::Writer(lfile);
// 原来的memtable移动到immutable memtable
imm_ = mem_;
has_imm_.store(true, std::memory_order_release);
// 创建新的memtable
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
force = false; // Do not force another compaction if have room
// 检查(immutable memtable和其他level)是否需要合并
MaybeScheduleCompaction();
}
}
return s;
}
4. memtable 合并写 sstable
继续看MaybeScheduleCompaction
4.1. MaybeScheduleCompaction:新增合并任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// db/db_impl.cc
void DBImpl::MaybeScheduleCompaction() {
mutex_.AssertHeld();
if (background_compaction_scheduled_) {
// 已经触发后台合并调度,不需要再新增任务
// Already scheduled
} else if (shutting_down_.load(std::memory_order_acquire)) {
// DB is being deleted; no more background compactions
} else if (!bg_error_.ok()) {
// Already got an error; no more changes
} else if (imm_ == nullptr && manual_compaction_ == nullptr &&
!versions_->NeedsCompaction()) {
// No work to be done
} else {
background_compaction_scheduled_ = true;
// 这里面会生产一个任务,并通知消费者进行线程处理
// 具体任务处理在 DBImpl::BGWork 回调函数里,负责后台合并 immutable memtable
env_->Schedule(&DBImpl::BGWork, this);
}
}
上面若需要合并,则env_->Schedule(&DBImpl::BGWork, this);投递任务,其回调处理为DBImpl::BGWork。
env_->Schedule里面基于mutex和条件变量实现了一个生产-消费者模型,LevelDB自己包装了一层std::mutex和std::condition_variable。
4.2. DBImpl::BGWork:合并回调函数
1
2
3
4
// db/db_impl.cc
void DBImpl::BGWork(void* db) {
reinterpret_cast<DBImpl*>(db)->BackgroundCall();
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// db/db_impl.cc
// 负责后台合并 immutable memtable
void DBImpl::BackgroundCall() {
MutexLock l(&mutex_);
assert(background_compaction_scheduled_);
if (shutting_down_.load(std::memory_order_acquire)) {
// No more background work when shutting down.
} else if (!bg_error_.ok()) {
// No more background work after a background error.
} else {
// 检查并进行后台合并
BackgroundCompaction();
}
// 合并完,重置任务调度标志
background_compaction_scheduled_ = false;
// Previous compaction may have produced too many files in a level,
// so reschedule another compaction if needed.
// 再检查一次是否要合并
MaybeScheduleCompaction();
background_work_finished_signal_.SignalAll();
}
1
2
3
4
5
6
7
8
9
10
11
// db/db_impl.cc
void DBImpl::BackgroundCompaction() {
mutex_.AssertHeld();
// 存在immutable memtable则合并并退出,immutable memtable合并为level0层的sstable
if (imm_ != nullptr) {
CompactMemTable();
return;
}
...
}
CompactMemTable函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// db/db_impl.cc
void DBImpl::CompactMemTable() {
mutex_.AssertHeld();
assert(imm_ != nullptr);
// Save the contents of the memtable as a new Table
VersionEdit edit;
// 当前version(每次合并完都会创建一个新的version)
Version* base = versions_->current();
base->Ref();
// immutable memtable 写入到 level0
Status s = WriteLevel0Table(imm_, &edit, base);
base->Unref();
...
}
4.3. DBImpl::WriteLevel0Table:写sstable
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// db/db_impl.cc
Status DBImpl::WriteLevel0Table(MemTable* mem, VersionEdit* edit,
Version* base) {
mutex_.AssertHeld();
const uint64_t start_micros = env_->NowMicros();
// 文件元数据(定义在db/version_edit.h中,VersionEdit类中会有多个FileMetaData)
FileMetaData meta;
// version文件计数+1,该数值也用于下面新增文件的文件名: db名称/编号.ldb
meta.number = versions_->NewFileNumber();
pending_outputs_.insert(meta.number);
// 获取传入 memtable(实际immutable memtable) 的迭代器
Iterator* iter = mem->NewIterator();
Log(options_.info_log, "Level-0 table #%llu: started",
(unsigned long long)meta.number);
Status s;
{
mutex_.Unlock();
// 这里通过 iter 写 sstable 文件
// 结束写入时:里面会写filter block、metaindex block、Write index block、Write footer
// 对应: 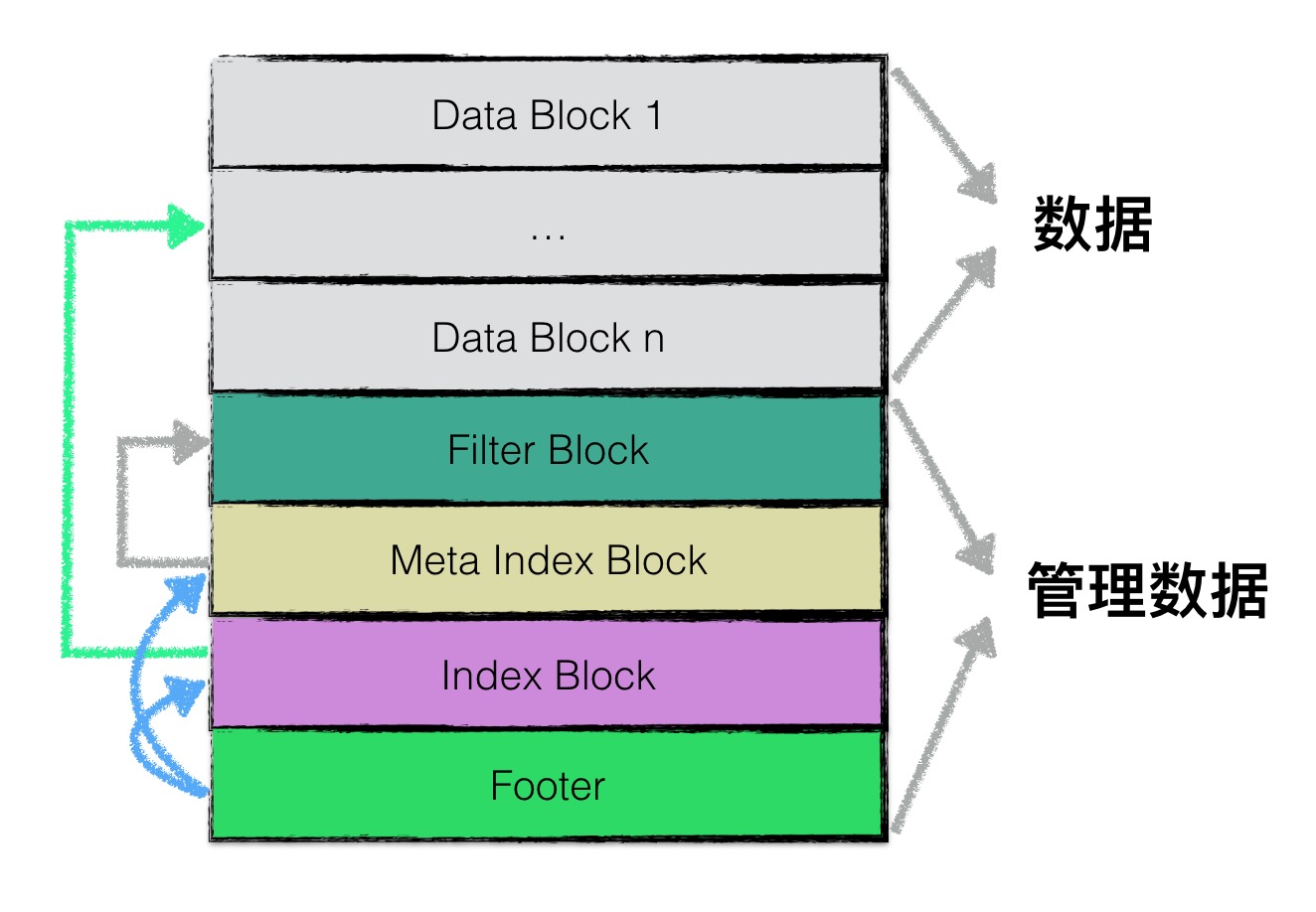
// meta作为指针传入,里面会做一些元数据设置
s = BuildTable(dbname_, env_, options_, table_cache_, iter, &meta);
mutex_.Lock();
}
Log(options_.info_log, "Level-0 table #%llu: %lld bytes %s",
(unsigned long long)meta.number, (unsigned long long)meta.file_size,
s.ToString().c_str());
delete iter;
...
return s;
}
上面BuildTable中负责根据迭代器依次写入key-value数据,最后(见下面小节)写入filter block、meta index block、Write index block、Write footer等信息。
4.4. BuildTable 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
// db/builder.cc
Status BuildTable(const std::string& dbname, Env* env, const Options& options,
TableCache* table_cache, Iterator* iter, FileMetaData* meta) {
Status s;
meta->file_size = 0;
// 先到链表头
iter->SeekToFirst();
// 新sstable文件名为 db名称/编号.ldb
std::string fname = TableFileName(dbname, meta->number);
if (iter->Valid()) {
WritableFile* file;
s = env->NewWritableFile(fname, &file);
if (!s.ok()) {
return s;
}
// TableBuilder用于辅助sstable文件写入
TableBuilder* builder = new TableBuilder(options, file);
// 设置元数据信息,第一个key是最小的key
meta->smallest.DecodeFrom(iter->key());
Slice key;
for (; iter->Valid(); iter->Next()) {
key = iter->key();
// 依次添加key-value数据
builder->Add(key, iter->value());
}
if (!key.empty()) {
// 设置元数据信息,最后key是最大的key
meta->largest.DecodeFrom(key);
}
// Finish and check for builder errors
// 结束写入:里面会写filter block、metaindex block、Write index block、Write footer
// 
s = builder->Finish();
if (s.ok()) {
meta->file_size = builder->FileSize();
assert(meta->file_size > 0);
}
...
}
...
return s;
}
4.5. 代码印证上述示意图
上述的sstable结构示意图:
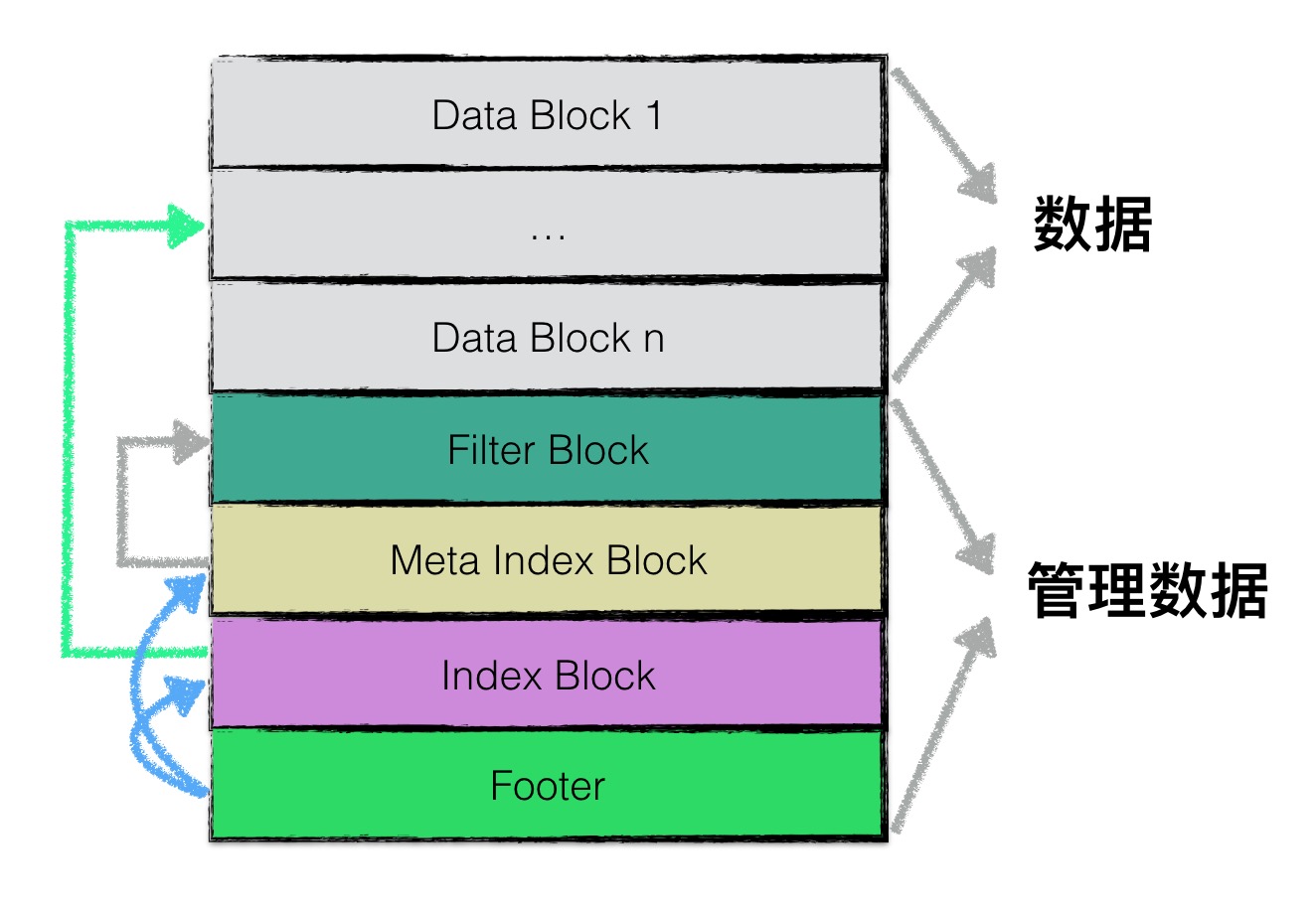
代码中依次写入filter block、meta index block、Write index block、Write footer等信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
// table/table_builder.cc
Status TableBuilder::Finish() {
Rep* r = rep_;
// 把前面的 data block 写文件落盘
Flush();
assert(!r->closed);
r->closed = true;
// 各部数据在sstable文件中的偏移+数据长度
BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle;
// Write filter block
// filter block存储的是data block数据的一些过滤信息。
// 这些过滤数据一般指代布隆过滤器的数据,用于加快查询的速度
if (ok() && r->filter_block != nullptr) {
// WriteRawBlock写原始数据(不需要压缩,而WriteBlock里可以对数据进行压缩)
// filter_block->Finish() 里面根据布隆过滤器实现
WriteRawBlock(r->filter_block->Finish(), kNoCompression,
&filter_block_handle);
}
// Write metaindex block
// meta index block用来存储filter block在整个sstable中的索引信息。
if (ok()) {
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != nullptr) {
// Add mapping from "filter.Name" to location of filter data
// key为:"filter."与过滤器名字组成的常量字符串
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
// value为:filter block在sstable中的索引信息序列化后的内容,
// 索引信息包括:(1)在sstable中的偏移量(2)数据长度。
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
// TODO(postrelease): Add stats and other meta blocks
// handle用于返回数据在文件的偏移和本次数据长度
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
// Write index block
// indexblock包含若干条记录,每一条记录代表一个data block的索引信息。
if (ok()) {
// 前面Flush已经把data_block写完了,pending_index_entry也置true了
if (r->pending_index_entry) {
// 一条索引包括以下内容:
// 1. data block i 中最大的key值;
// 2. 该data block起始地址在sstable中的偏移量;
// 3. 该data block的大小
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
// 数据在文件中的偏移,以及数据长度
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
WriteBlock(&r->index_block, &index_block_handle);
}
// Write footer
if (ok()) {
Footer footer;
// footer大小固定,为48字节,用来存储meta index block与index block在sstable中的索引信息,另外尾部还会存储一个magic word
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
// 追加到文件中
r->status = r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset += footer_encoding.size();
}
}
return r->status;
}
5. 小结
学习梳理sstable实现逻辑。
6. 参考
1、leveldb