LevelDB学习笔记(七) -- 布隆过滤器
LevelDB学习笔记,本篇学习其布隆过滤器实现。
1. 背景
继续学习梳理LevelDB中具体的流程,本篇来看下布隆过滤器实现。
之前学习记录中虽然有涉及但未展开:
LevelDB学习笔记(二) – 读写操作流程里面的读写流程,没有展开说明
LevelDB学习笔记(五) – sstable实现里提到filter block是基于布隆过滤器实现的。
主要参考如下文章并映证LevelDB代码:
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. Why
先看看LevelDB为什么要用布隆过滤器?
对于 LevelDB 的一次读取操作,需要首先去 memtable、immutable memtable 查找,然后依次去文件系统(sstable文件)中各层查找。可以看出,相比写入操作,读取操作实在有点效率低下。我们这种客户端进行一次读请求,进入系统后被变成多次读请求的现象为读放大。
为了减小读放大,LevelDB 采取了几方面措施:
- 通过
major compaction尽量减少 sstable 文件 - 使用快速筛选的办法,快速判断 key 是否在某个 sstable 文件中
而快速判断某个 key 是否在某个 key 集合中,LevelDB 用的正是布隆过滤器。
3. 布隆过滤器原理
Bloom Filter(wiki) 是 Burton Howard Bloom于 1970 年 提出,相关论文为: Space/time trade-offs in hash coding with allowable errors。
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。
Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。
因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
3.1. 结构
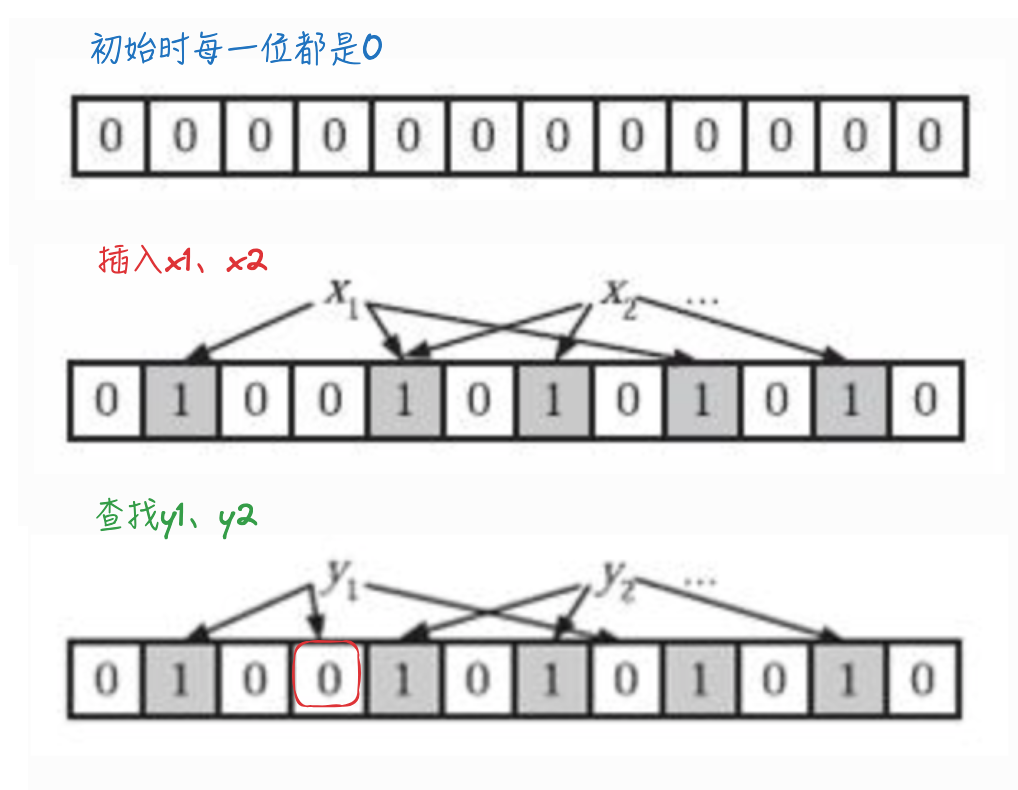
- bloom过滤器底层是一个位数组,初始时每一位都是0
- 插入:当插入值x后,分别利用k个哈希函数,利用x的值进行散列,并将散列得到的值与bloom过滤器的容量进行取余,将取余结果所代表的那一位值置为1。
- 查找:同样利用k个哈希函数对所需要查找的值进行散列,只有散列得到的每一个位的值均为1,才表示该值“有可能”真正存在;反之若有任意一位的值为0,则表示该值一定不存在。
- 例如y1一定不存在;而y2可能存在。
示意图如下:
3.2. 相关参数
与布隆过滤器准确率有关的参数有:
- 哈希函数的个数k;
- 布隆过滤器位数组的容量m;
- 布隆过滤器插入的数据数量n;
并有如下结论:
- 为了获得最优的准确率,当
k = (ln2) * (m/n)时,布隆过滤器获得最优的准确性; - 在哈希函数的个数取到最优时,要让错误率不超过
ε,m至少需要取到错判率最小值的1.44倍;- bloom filter中错判的概率叫
false postive,记为ε
- bloom filter中错判的概率叫
可进一步查看:经典论文解读——布隆过滤器,有基本的概率论知识就可以看懂里面的参数和概率证明。(里面还提到几种优化点和对应论文、redis中的扩展实现、golang中的实现等)
参考链接里提到Murmur3作为哈希函数,随机性很好。LevelDB里自己实现的也是类murmur哈希(util/hash.cc中的Hash函数)
4. LevelDB中的布隆过滤器
LevelDB中利用布隆过滤器判断指定的key值是否存在于sstable中,若过滤器表示不存在,则该key一定不存在,由此加快了查找的效率。
4.1. 调用链
再看下sstable合并操作流程,其中涉及布隆过滤器操作。
调用链为:CompactMemTable->WriteLevel0Table->BuildTable->builder->Finish()->filter block操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// table/table_builder.cc
Status TableBuilder::Finish() {
Rep* r = rep_;
// 把前面的 data block 写文件落盘
Flush();
assert(!r->closed);
r->closed = true;
// 各部数据在sstable文件中的偏移+数据长度
BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle;
// Write filter block
// filter block存储的是data block数据的一些过滤信息。
// 这些过滤数据一般指代布隆过滤器的数据,用于加快查询的速度
if (ok() && r->filter_block != nullptr) {
// WriteRawBlock写原始数据(不需要压缩,而WriteBlock里可以对数据进行压缩)
// filter_block->Finish() 里面根据布隆过滤器实现
WriteRawBlock(r->filter_block->Finish(), kNoCompression,
&filter_block_handle);
}
...
}
下面对r->filter_block->Finish()进行说明。
4.2. FilterBlockBuilder::Finish()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// table/filter_block.cc
Slice FilterBlockBuilder::Finish() {
if (!start_.empty()) {
GenerateFilter();
}
// Append array of per-filter offsets
const uint32_t array_offset = result_.size();
for (size_t i = 0; i < filter_offsets_.size(); i++) {
PutFixed32(&result_, filter_offsets_[i]);
}
PutFixed32(&result_, array_offset);
result_.push_back(kFilterBaseLg); // Save encoding parameter in result
return Slice(result_);
}
GenerateFilter逻辑,主要看CreateFilter:
1
2
3
4
5
6
7
void FilterBlockBuilder::GenerateFilter() {
...
// Generate filter for current set of keys and append to result_.
filter_offsets_.push_back(result_.size());
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
...
}
4.3. BloomFilterPolicy::CreateFilter 布隆过滤器hash计算
LevelDB 实现时并未真正使用 k 个哈希函数,而是用了 double-hashing 方法进行了一个优化,号称可以达到相似的正确率。
详细分析可以参考:Less Hashing, Same Performance: Building a Better Bloom Filter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
// util/bloom.cc
class BloomFilterPolicy : public FilterPolicy {
...
void CreateFilter(const Slice* keys, int n, std::string* dst) const override {
// Compute bloom filter size (in both bits and bytes)
// n是key的个数,这里算出本次传入key需要占用的位数
size_t bits = n * bits_per_key_;
// For small n, we can see a very high false positive rate. Fix it
// by enforcing a minimum bloom filter length.
// 如果数组太短,会有很高的误判率,因此这里加了一个最小长度限定
if (bits < 64) bits = 64;
// bits向上取整为8的倍数
size_t bytes = (bits + 7) / 8;
bits = bytes * 8;
// 布隆过滤器结果是一个简单的string,这里在原来基础上叠加本次要新增的数据长度
const size_t init_size = dst->size();
dst->resize(init_size + bytes, 0);
// 记录下哈希函数的个数,1个字节进行记录
dst->push_back(static_cast<char>(k_)); // Remember # of probes in filter
// 指向string* 里原有数据的最后位置
char* array = &(*dst)[init_size];
// 遍历处理本次所有的key
for (int i = 0; i < n; i++) {
// Use double-hashing to generate a sequence of hash values.
// See analysis in [Kirsch,Mitzenmacher 2006].
// 使用double-hashing方法,仅使用一个 hash 函数来生成k个hash值,近似等价于k个hash函数的效果
// 详细分析可以参考:https://www.eecs.harvard.edu/~michaelm/postscripts/rsa2008.pdf
uint32_t h = BloomHash(keys[i]);
// 循环右移17bits作为步长
const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
for (size_t j = 0; j < k_; j++) {
// 使用上面的hash值来生成k个位置进行设置
const uint32_t bitpos = h % bits;
// 设置对应的bit, k次
array[bitpos / 8] |= (1 << (bitpos % 8));
h += delta;
}
}
}
...
};
4.4. 查找
查找流程:Version::Get -> 里面ForEachOverlapping会依次找各层,通过内部定义的回调函数State::Match具体处理 ->
state->vset->table_cache_->Get 先基于布隆过滤器判断是否存在key,可能存在则继续往下找:
TableCache::Get -> t->InternalGet -> 先filter->KeyMayMatch,可能有则BlockReader()去找文件(文件是否在缓存,不在才去具体file找)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Status DBImpl::Get(const ReadOptions& options, const Slice& key,
std::string* value) {
...
{
// 从文件和memtable中读取时先解锁
mutex_.Unlock();
// First look in the memtable, then in the immutable memtable (if any).
//构造一个查询key,会根据key+seqnumber+key类型 进行编码得到
LookupKey lkey(key, snapshot);
// 到memtable找key,传入key对应的seqnumber
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != nullptr && imm->Get(lkey, value, &s)) { // 找不到则在immutalbe table里找
// Done
} else {
// 上面都找不到则在current Version里找,根据布隆过滤器检查是否存在,若可能存在则去找缓存及sstable
// Version::Get -> 里面ForEachOverlapping会依次找各层,通过内部定义的回调函数State::Match具体处理 ->
// state->vset->table_cache_->Get 先基于布隆过滤器判断是否存在key,可能存在则继续往下找
// TableCache::Get -> t->InternalGet -> 先filter->KeyMayMatch,可能有则BlockReader()去找文件(文件是否在缓存,不在才去具体file找)
s = current->Get(options, lkey, value, &stats);
// 状态直接更新为true?
have_stat_update = true;
}
mutex_.Lock();
}
...
}
current->Get逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// db/table_cache.cc
Status TableCache::Get(const ReadOptions& options, uint64_t file_number,
uint64_t file_size, const Slice& k, void* arg,
void (*handle_result)(void*, const Slice&,
const Slice&)) {
Cache::Handle* handle = nullptr;
Status s = FindTable(file_number, file_size, &handle);
if (s.ok()) {
Table* t = reinterpret_cast<TableAndFile*>(cache_->Value(handle))->table;
s = t->InternalGet(options, k, arg, handle_result);
cache_->Release(handle);
}
return s;
}
t->InternalGet对应逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// table/table.cc
Status Table::InternalGet(const ReadOptions& options, const Slice& k, void* arg,
void (*handle_result)(void*, const Slice&,
const Slice&)) {
...
FilterBlockReader* filter = rep_->filter;
BlockHandle handle;
// 这里 KeyMayMatch 判断k是否存在,布隆过滤器中找不到则一定不存在
// filter不一定创建了,需要外面Open db时指定options,可由 NewBloomFilterPolicy 指定FilterPolicy为布隆过滤器
if (filter != nullptr && handle.DecodeFrom(&handle_value).ok() &&
!filter->KeyMayMatch(handle.offset(), k)) {
// Not found
} else {
// 继续找缓存或者文件
Iterator* block_iter = BlockReader(this, options, iiter->value());
block_iter->Seek(k);
...
}
...
}
filter->KeyMayMatch对应逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// table/filter_block.cc
bool FilterBlockReader::KeyMayMatch(uint64_t block_offset, const Slice& key) {
uint64_t index = block_offset >> base_lg_;
if (index < num_) {
uint32_t start = DecodeFixed32(offset_ + index * 4);
uint32_t limit = DecodeFixed32(offset_ + index * 4 + 4);
if (start <= limit && limit <= static_cast<size_t>(offset_ - data_)) {
Slice filter = Slice(data_ + start, limit - start);
// 这里是具体过滤器的实现,此处就是布隆过滤器了(也可自定义)
return policy_->KeyMayMatch(key, filter);
} else if (start == limit) {
// Empty filters do not match any keys
return false;
}
}
return true; // Errors are treated as potential matches
}
policy_->KeyMayMatch布隆过滤器查找逻辑:
可看到和CreateFilter里的double-hashing计算方式一样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// util/bloom.cc
class BloomFilterPolicy : public FilterPolicy {
...
bool KeyMayMatch(const Slice& key, const Slice& bloom_filter) const override {
const size_t len = bloom_filter.size();
if (len < 2) return false;
// 传入过滤器数据
const char* array = bloom_filter.data();
const size_t bits = (len - 1) * 8;
// Use the encoded k so that we can read filters generated by
// bloom filters created using different parameters.
const size_t k = array[len - 1];
if (k > 30) {
// Reserved for potentially new encodings for short bloom filters.
// Consider it a match.
return true;
}
// 计算hash
uint32_t h = BloomHash(key);
const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
for (size_t j = 0; j < k; j++) {
// 根据hash转换得到每位取值,和传入的过滤器数据比较
const uint32_t bitpos = h % bits;
// 每位进行匹配比较
if ((array[bitpos / 8] & (1 << (bitpos % 8))) == 0) return false;
h += delta;
}
return true;
}
...
};
5. 小结
学习梳理布隆过滤器实现逻辑。
6. 参考
1、leveldb
2、漫谈 LevelDB 数据结构(二):布隆过滤器(Bloom Filter)