Linux存储IO栈梳理(二) -- Linux内核存储栈流程和接口
梳理学习Linux内核存储栈相关流程和接口。
1. 背景
LevelDB的学习梳理暂告一段落(还有不少东西没完结),继续看Linux存储IO栈。
上一篇:Linux存储IO栈梳理(一) – 存储栈全貌图 中,看了一下总体存储协议栈,本篇看下VFS和文件系统相关的内核代码逻辑。
主要参考下面文章,并结合内核代码梳理学习:
demo运行的本地测试环境为:CentOS Linux release 8.5.2111 系统,内核版本为 4.18.0-348.7.1.el8_5.x86_64
(内核代码基于之前常用的5.10.10版本,分析流程类似)
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 从一个问题开始
问题:read 文件一个字节实际会发生多大的磁盘IO?
2.1. IO栈简图
再看下IO栈的简图:
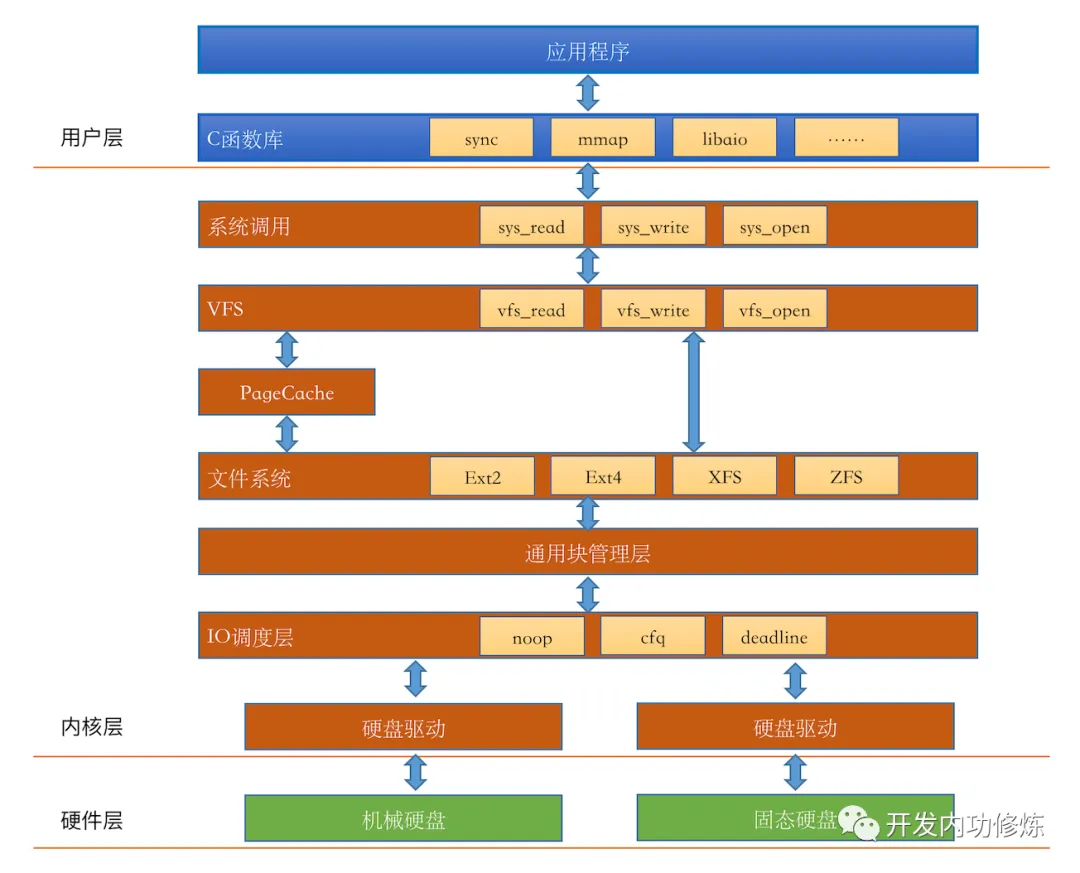
纠错: Page Cache应该是在具体文件系统下层,具体接口中判断是否需要过Page Cache。
典型IO读写流程如下:
- 用户态程序通过
read/write系统调用进行读写时,经过VFS(Virtual File System,虚拟文件系统), - 到具体的文件系统(ext/xfs等)实现
- 然后判断处理是否经过
Page Cache(不指定O_DIRECT时则经过,若指定了该选项则跳过), - 而后以
bio形式到通用块层, - 经块调度后通过硬盘驱动写到具体硬盘介质(HDD/SSD等)上,硬盘自身内部可能有自己的缓存(或者硬盘组RAID时,RAID控制器自身一般也有缓存)
下面看下上述各流程中,在内核中的相关定义。
3. IO栈各层说明
3.1. VFS 虚拟文件系统
Linux 内核中,虚拟文件系统(VFS)是一个抽象层,提供一种统一的方式来处理不同类型的文件系统。
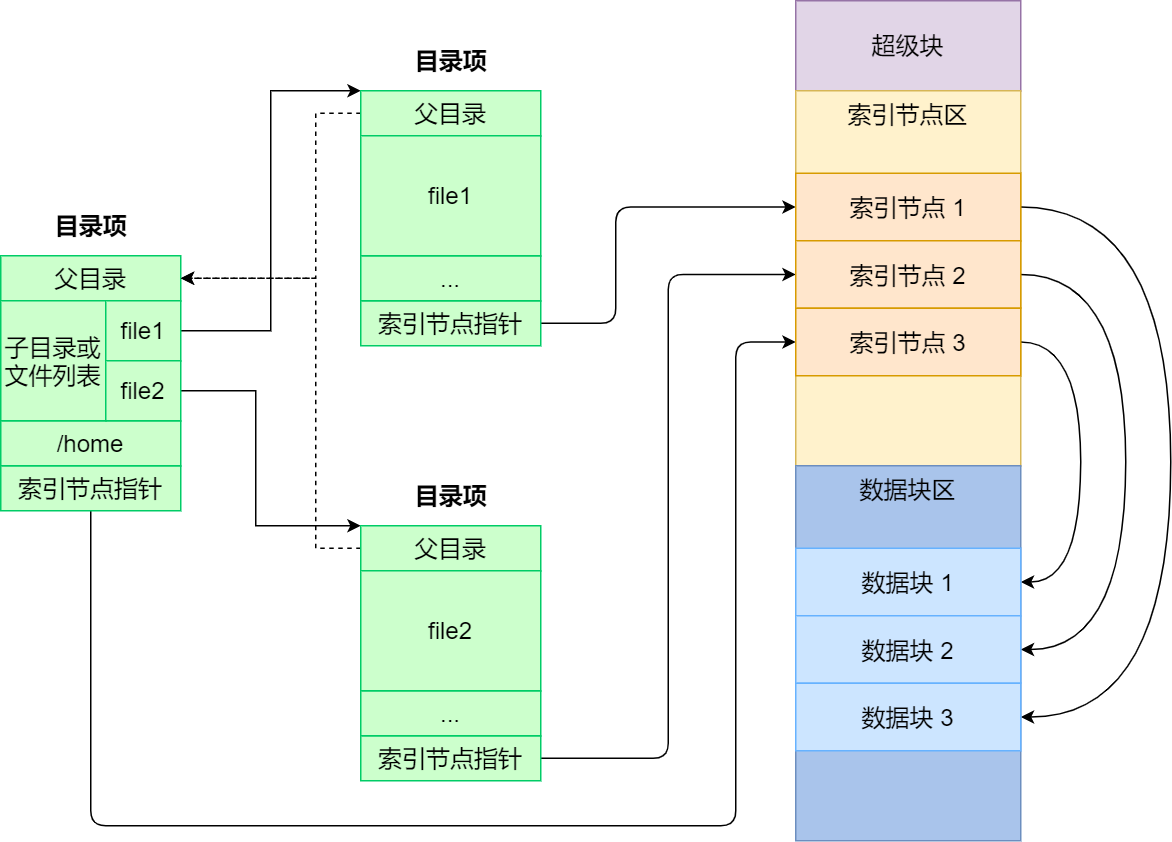
VFS中的几个核心结构:
super_block:文件系统的超级块,包含文件系统类型、状态、块大小、根目录等信息。- 每个文件系统在挂载时都会有一个与之相关联的
struct super_block,用于管理文件系统的通用状态信息。
- 每个文件系统在挂载时都会有一个与之相关联的
inode:索引节点,表示文件系统中的一个文件或目录,包含文件类型、权限、所有者信息、大小、时间戳以及数据块在磁盘的位置等。struct inode提供了与文件相关的元数据。- 索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间
dentry:目录项(directory entry),目录中的一个条目,即目录与文件的映射关系,包含文件名和指向相应inode的指针。struct dentry主要用于路径解析,并实现了一个目录项的缓存机制,以提高访问效率。- 目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存
file:每个打开的文件在内核空间都有一个和这个数据结构相关的struct file,包含文件偏移量、访问权限、指向dentry的指针等信息。- 该结构体用于跟踪进程打开的文件实例。
上述结构,super_block、inode、file均定义在 include/linux/fs.h 中, dentry定义在 include/linux/dcache.h 中。
此外还有file_system_type、vfsmount、address_space等,此处暂不做展开。
索引节点、目录项以及文件数据的关系示意图:
3.1.1. super_block
super_block定义如下,截取部分内容:
1
2
3
4
5
6
7
8
9
10
// linux-5.10.10/include/linux/fs.h
struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
...
struct file_system_type *s_type;
// 超级块的操作接口
const struct super_operations *s_op;
...
};
超级块的操作接口super_operations也定义在include/linux/fs.h中,这里都只是函数指针:
1
2
3
4
5
6
7
8
9
// linux-5.10.10/include/linux/fs.h
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
...
void (*dirty_inode) (struct inode *, int flags);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
int (*drop_inode) (struct inode *);
...
};
3.1.2. inode
inode定义截取部分内容:
1
2
3
4
5
6
7
8
9
10
// linux-5.10.10/include/linux/fs.h
struct inode {
umode_t i_mode;
unsigned short i_opflags;
...
// inode操作
const struct inode_operations *i_op;
struct super_block *i_sb;
...
}
对应的操作接口inode_operations也定义在include/linux/fs.h中:
1
2
3
4
5
6
7
8
9
// linux-5.10.10/include/linux/fs.h
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int);
...
int (*create) (struct inode *,struct dentry *, umode_t, bool);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*mkdir) (struct inode *,struct dentry *,umode_t);
...
};
3.1.3. file
file定义截取部分内容:
1
2
3
4
5
6
7
8
9
10
11
12
// linux-5.10.10/include/linux/fs.h
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
// file对应操作
const struct file_operations *f_op;
...
};
file对应的不少操作就比较眼熟了:
1
2
3
4
5
6
7
8
9
10
11
12
13
// linux-5.10.10/include/linux/fs.h
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
...
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
...
};
3.1.4. dentry
dentry则定义在include/linux/dcache.h中,定义截取部分内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
// linux-5.10.10/include/linux/dcache.h
struct dentry {
...
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct inode *d_inode;
...
// dentry对应操作
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
...
};
对应操作定义也在dcache.h中:
1
2
3
4
5
6
7
8
9
10
// linux-5.10.10/include/linux/dcache.h
struct dentry_operations {
int (*d_revalidate)(struct dentry *, unsigned int);
int (*d_weak_revalidate)(struct dentry *, unsigned int);
int (*d_hash)(const struct dentry *, struct qstr *);
int (*d_compare)(const struct dentry *,
unsigned int, const char *, const struct qstr *);
int (*d_delete)(const struct dentry *);
...
};
3.2. 具体文件系统(xfs为例)
3.2.1. 先看下ext系统
参考文章中,do_generic_file_read接口基于3.10的ext系统(在5.10内核里面没有该接口)。
找一份3.10代码,do_generic_file_read是在generic_file_aio_read中被调用的,ext4对应的file_operations中会进行注册:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// linux-3.10.89/fs/ext4/file.c
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read = do_sync_read,
.write = do_sync_write,
.aio_read = generic_file_aio_read,
.aio_write = ext4_file_write,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.splice_read = generic_file_splice_read,
.splice_write = generic_file_splice_write,
.fallocate = ext4_fallocate,
};
3.2.2. xfs系统
根据自己测试环境(5.10内核)的目录对应的fs,这里是xfs文件系统。
1
2
[root@xdlinux ➜ simple_io git:(main) ✗ ]$ mount|grep /home
/dev/mapper/cl_desktop--mme7h3a-home on /home type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)
对应上面VFS的核心结构,找到部分相关定义如下:
struct super_operations xfs_super_operations- linux-5.10.10/fs/xfs/xfs_super.c
struct xfs_inode- linux-5.10.10/fs/xfs/xfs_inode.h
struct file_operations xfs_file_operations- linux-5.10.10/fs/xfs/xfs_file.c
看下对应的文件操作:里面貌似没有直接注册read、write等接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// linux-5.10.10/fs/xfs/xfs_file.c
const struct file_operations xfs_file_operations = {
.llseek = xfs_file_llseek,
.read_iter = xfs_file_read_iter,
.write_iter = xfs_file_write_iter,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.iopoll = iomap_dio_iopoll,
.unlocked_ioctl = xfs_file_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = xfs_file_compat_ioctl,
#endif
.mmap = xfs_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = xfs_file_open,
.release = xfs_file_release,
.fsync = xfs_file_fsync,
.get_unmapped_area = thp_get_unmapped_area,
.fallocate = xfs_file_fallocate,
.fadvise = xfs_file_fadvise,
.remap_file_range = xfs_file_remap_range,
};
3.3. Page Cache 页高速缓存
Page Cache用于加速文件系统访问,通过缓存磁盘数据来减少直接磁盘I/O操作,从而加速文件读取和写入。
上述具体文件系统接口读写时,会根据open时传入参数(是否指定O_DIRECT)判断是否需要经过Page Cache。
我们在 Linux存储IO栈梳理(一) – 存储栈全貌图 中贴的耗时体感图,里面有个耗时对比:磁盘缓存命中时在100微秒内,磁盘连续读则在约1ms级别,随机读约8ms(这里可能是指磁盘内部缓存?还是FS缓存?)。
在 Linux 内核中,页面缓存由一系列 struct page 组成,每个页结构代表一个内存页,页面缓存通过这些页结构来管理和存储缓存的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// linux-5.10.10/include/linux/mm_types.h
struct page {
unsigned long flags; /* Atomic flags, some possibly updated asynchronously */
union {
struct { /* Page cache and anonymous pages */
struct list_head lru;
// 页面缓存的核心结构,用于管理文件内容在内存中的表示。
// 每个文件都拥有一个 `address_space` 结构,用来跟踪文件的数据在页面缓存中的位置。
// 所属的地址空间
struct address_space *mapping;
pgoff_t index;
unsigned long private;
};
struct { /* page_pool used by netstack */
dma_addr_t dma_addr;
};
struct { /* slab, slob and slub */
...
struct kmem_cache *slab_cache; /* not slob */
...
};
...
};
...
};
3.4. 通用块层
通用块层 -> 驱动,后面就不跟踪贴代码了。直接在实际demo里跟踪下调用栈过程。
3.5. 读取时的简要代码流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// linux-5.10.10/fs/read_write.c
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
return ksys_read(fd, buf, count);
}
ssize_t ksys_read(unsigned int fd, char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
...
ret = vfs_read(f.file, buf, count, ppos);
...
}
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
...
ret = rw_verify_area(READ, file, pos, count);
...
if (file->f_op->read)
// 调用具体文件系统的 read
ret = file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
// 里面调用具体文件系统的 read_iter
// `read` 常用于简单的同步 I/O,适合标准文件系统操作;`read_iter` 则在需要最大效率的文件系统或高负载的应用中更有用
// `read_iter` 更适合高性能的异步操作,而 `read` 是传统的阻塞操作
ret = new_sync_read(file, buf, count, pos);
else
ret = -EINVAL;
if (ret > 0) {
fsnotify_access(file);
add_rchar(current, ret);
}
...
}
4. eBPF跟踪读取流程
4.1. 追踪点说明
看下系统支持的tracepoint和kprobe。直接到 /sys/kernel/tracing/available_events 和 /sys/kernel/tracing/available_filter_functions 中找下,可用下述tracepoint 或 kprobe:
- tracepoint:
syscalls:sys_enter_read、syscalls:sys_exit_read - kprobe:
vfs_read、__x64_sys_read
4.2. 追踪工具说明
经过前面的学习实践(eBPF学习实践系列、追踪内核网络堆栈的几种方式等),手头已经有不少工具集了(太富裕了。。),这里做下简单梳理。
bpftrace写简便的eBPF功能,能满足日常大部分追踪需要了- tools里面还有很多现成的bt脚本,也可以用
bcc toolsbcc提供了很多现成的工具集- 安装bcc后在/usr/share/bcc/tools/
libbpf-toolsbcc仓库里基于libbpf的工具,直接编译出来的bin就可以用了- 很快而且不用另外去装
bcc
- 很快而且不用另外去装
perf-tools里面基于ftrace和perf也提供了很多便捷功能(funcgraph特别好用)- 都是脚本,直接拷贝可用
- 直接用
perf record/perf report,功能也强就是多了一点点步骤 - 其他
- 如果是看网络,还有cilium的
pwru(package, where are you) 和 最近字节开源的 net-cap
- 如果是看网络,还有cilium的
追踪调用栈经验:结合bpftrace和funcgraph跟踪前后调用栈
bpftrace用来从上到下来跟踪到指定函数,即只能看到谁调用到指定追踪点funcgraph用来从指定函数往下追踪调用栈
下面是简单实验对比的过程,可以略过不看,这里只放在这里作对比回忆。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
* 1、bpftrace 从上往下到本次指定的event/kprobe
bpftrace -e 'tracepoint:syscalls:sys_enter_read / comm=="a.out"/ { printf("comm:%s, kstack:%s\n", comm, kstack) }'
bpftrace -e 'kprobe:vfs_read /comm=="a.out"/ { printf("comm:%s, kstack:%s\n", comm, kstack) }'
[root@home bin]# bpftrace -e 'kprobe:vfs_read /comm=="a.out"/ { printf("comm:%s, kstack:%s\n", comm, kstack) }'
Attaching 1 probe...
comm:a.out, kstack:
vfs_read+1
ksys_read+95
do_syscall_64+61
entry_SYSCALL_64_after_hwframe+98
* 2、bcc tools里的trace:只能看到调用了,没有具体信息
e.g. trace 'do_sys_open "%s", arg2' -n main
/usr/share/bcc/tools/trace 'vfs_read' -n "a.out"
[root@home bin]# /usr/share/bcc/tools/trace 'vfs_read' -n "a.out"
PID TID COMM FUNC
27696 27696 a.out vfs_read
27696 27696 a.out vfs_read
27696 27696 a.out vfs_read
27696 27696 a.out vfs_read
* 3、perf tools里的functrace也满足不了需求
[root@home bin]# ./functrace vfs_read
Tracing "vfs_read"... Ctrl-C to end.
tuned-14187 [009] .... 2991651.244559: vfs_read <-ksys_read
tuned-14187 [009] .... 2991651.244571: vfs_read <-ksys_read
<...>-8506 [029] .... 2991651.244586: vfs_read <-ksys_read
* 4、perf tools里的 funcgraph 看起来可以,追踪指定函数后面的堆栈(相对于bpftrace可以互补),但是过滤不了进程名(调整demo接收信号即可)
* 5、再看下perf tools里的kprobe,和上面的functrace和bcc tools里trace感觉差别不大
[root@home bin]# ./kprobe 'p:vfs_read'
Tracing kprobe vfs_read. Ctrl-C to end.
awk-14786 [010] .... 2992198.369464: vfs_read: (vfs_read+0x0/0x1b0)
awk-14786 [010] .... 2992198.369491: vfs_read: (vfs_read+0x0/0x1b0)
sh-14754 [001] .... 2992198.369503: vfs_read: (vfs_read+0x0/0x1b0)
4.3. 读取的demo程序
由于funcgraph不支持过滤进程名,读取demo调整成接收信号(这里用USR1)触发的方式,通过pid跟踪过滤,要不系统里read操作太多了。
funcgraph用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[root@xdlinux ➜ bin git:(master) ]$ ./funcgraph -h
USAGE: funcgraph [-aCDhHPtT] [-m maxdepth] [-p PID] [-L TID] [-d secs] funcstring
-a # all info (same as -HPt)
-C # measure on-CPU time only
-d seconds # trace duration, and use buffers
-D # do not show function duration
-h # this usage message
-H # include column headers
-m maxdepth # max stack depth to show
-p PID # trace when this pid is on-CPU
-L TID # trace when this thread is on-CPU
-P # show process names & PIDs
-t # show timestamps
-T # comment function tails
eg,
funcgraph do_nanosleep # trace do_nanosleep() and children
funcgraph -m 3 do_sys_open # trace do_sys_open() to 3 levels only
funcgraph -a do_sys_open # include timestamps and process name
funcgraph -p 198 do_sys_open # trace vfs_read() for PID 198 only
funcgraph -d 1 do_sys_open >out # trace 1 sec, then write to file
使用read系统调用读取 /etc/fstab 文件内容,代码如下:
此处也有归档。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
// read_by_signal.cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <signal.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <errno.h>
// 信号处理器函数
void signal_handler(int signum) {
if (signum == SIGUSR1) {
// 打开 /etc/fstab 文件
int fd = open("/etc/fstab", O_RDONLY);
if (fd == -1) {
perror("Error opening file");
return;
}
char buffer[1024];
ssize_t bytes_read;
// 读取文件内容
while ((bytes_read = read(fd, buffer, sizeof(buffer))) > 0) {
write(STDOUT_FILENO, buffer, bytes_read); // 输出到标准输出
}
if (bytes_read == -1) {
perror("Error reading file");
}
close(fd); // 关闭文件描述符
}
}
int main() {
pid_t pid = getpid();
// 打印进程ID
printf("Process ID: %d\n", pid);
// 设置信号处理器
signal(SIGUSR1, signal_handler);
// 进入无限循环等待信号
for (;;) {
pause();
}
return 0;
}
编译:g++ read_by_signal.cpp -o read_fstab
4.4. 运行追踪
4.4.1. 本地CentOS8环境实验
1、运行demo:
1
2
[root@xdlinux ➜ read_by_signal git:(main) ✗ ]$ ./read_fstab
Process ID: 8397
2、启动前后堆栈追踪
bpftrace -e 'kprobe:vfs_read /pid==8397/ { printf("comm:%s, kstack:%s\n", comm, kstack) }'./funcgraph -H -p 8397 vfs_read
3、发送信号 kill -USR1 8397,触发读取,下面是追踪结果
bpftrace 结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
[root@xdlinux ➜ ~ ]$ bpftrace -e 'kprobe:vfs_read /pid==8397/ { printf("comm:%s, kstack:%s\n", comm, kstack) }'
Attaching 1 probe...
comm:read_fstab, kstack:
vfs_read+1
ksys_read+79
do_syscall_64+91
entry_SYSCALL_64_after_hwframe+101
comm:read_fstab, kstack:
vfs_read+1
ksys_read+79
do_syscall_64+91
entry_SYSCALL_64_after_hwframe+101
funcgraph 结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
[root@xdlinux ➜ bin git:(master) ]$ ./funcgraph -H -p 8397 vfs_read
Tracing "vfs_read" for PID 8397... Ctrl-C to end.
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
4) | vfs_read() {
4) ==========> |
4) | smp_irq_work_interrupt() {
4) | irq_enter() {
4) 0.040 us | irqtime_account_irq();
4) 0.401 us | }
4) | __wake_up() {
4) | __wake_up_common_lock() {
4) 0.010 us | _raw_spin_lock_irqsave();
4) | __wake_up_common() {
4) | ...
4) 9.397 us | }
4) 0.020 us | _raw_spin_unlock_irqrestore();
4) + 10.119 us | }
4) + 10.259 us | }
4) | irq_exit() {
4) 0.030 us | irqtime_account_irq();
4) 0.010 us | idle_cpu();
4) 0.341 us | }
4) + 11.952 us | }
4) <========== |
4) 7.835 us | } /* vfs_read */
4) | vfs_read() {
4) ==========> |
4) | smp_irq_work_interrupt() {
4) | irq_enter() {
4) 0.070 us | irqtime_account_irq();
4) 0.251 us | }
4) | __wake_up() {
4) | __wake_up_common_lock() {
4) 0.020 us | _raw_spin_lock_irqsave();
4) 0.020 us | __wake_up_common();
4) 0.020 us | _raw_spin_unlock_irqrestore();
4) 0.501 us | }
4) 0.631 us | }
4) | irq_exit() {
4) 0.030 us | irqtime_account_irq();
4) 0.020 us | idle_cpu();
4) 0.341 us | }
4) 2.024 us | }
4) <========== |
4) 0.912 us | } /* vfs_read */
4、结果分析
bpftrace调用栈:do_syscall->ksys_read->vfs_read
funcgraph:
CentOS8(或者4.18内核?)有毒吧!!!每次funcgraph只能看到中断,别的信息都不打出来。坑货。
还不明确什么原因 待定 TODO 见下面尝试定位的小节。
4.4.2. 阿里云ECS实验
起一个阿里云抢占式ECS:Alibaba Cloud Linux 3.2104 LTS 64位(内核版本:5.10.134-16.1.al8.x86_64)
文件系统是ext4:/dev/vda3 on / type ext4 (rw,relatime)
环境安装工具:yum install bpftrace g++ -y、perf-tools传上去
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
[root@iZ2ze46ejz8k5jlayp9h26Z bin]# ./funcgraph -H -p 4879 vfs_read
Tracing "vfs_read" for PID 4879... Ctrl-C to end.
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
0) | vfs_read() {
0) | irq_enter_rcu() {
0) 0.217 us | irqtime_account_irq();
0) 0.771 us | }
0) | __sysvec_irq_work() {
0) | __wake_up() {
# (中间的中断相关处理省略)
0) | ...
0) + 19.971 us | }
0) + 20.655 us | }
0) | irq_exit_rcu() {
0) 0.183 us | irqtime_account_irq();
0) 0.169 us | sched_core_idle_cpu();
0) 0.862 us | }
0) | rw_verify_area() {
0) | security_file_permission() {
0) 0.155 us | __fsnotify_parent();
0) 0.457 us | }
0) 0.730 us | }
0) | new_sync_read() {
0) | ext4_file_read_iter() {
0) | generic_file_read_iter() {
0) | generic_file_buffered_read() {
0) | _cond_resched() {
0) 0.149 us | rcu_all_qs();
0) 0.431 us | }
0) | generic_file_buffered_read_get_pages() {
0) | find_get_pages_contig() {
0) 0.217 us | PageHuge();
0) 0.206 us | rcu_read_unlock_strict();
0) 1.410 us | }
0) 2.012 us | }
0) 0.252 us | mark_page_accessed();
0) | touch_atime() {
0) | atime_needs_update() {
0) | current_time() {
0) 0.207 us | ktime_get_coarse_real_ts64();
0) 0.635 us | }
0) 1.143 us | }
0) 1.623 us | }
0) 6.038 us | }
0) 6.507 us | }
0) 6.908 us | }
0) 7.379 us | }
0) 0.216 us | __fsnotify_parent();
0) + 34.563 us | }
# 又是一个vfs_read,跟上面调用栈差不多
0) | vfs_read() {
0) | rw_verify_area() {
0) | security_file_permission() {
0) 0.171 us | __fsnotify_parent();
0) 0.495 us | }
0) 0.845 us | }
0) | new_sync_read() {
0) | ...
0) 4.224 us | }
0) 5.719 us | }
4.4.3. 本地funcgraph结果不完整问题定位
perf-tools是基于ftrace和perf写的脚本,里面控制各种ftrace的参数,形式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
# funcgraph
...
if (( opt_time )); then
if ! echo funcgraph-abstime > trace_options; then
edie "ERROR: setting -t (funcgraph-abstime). Exiting."
fi
fi
if (( opt_proc )); then
if ! echo funcgraph-proc > trace_options; then
edie "ERROR: setting -P (funcgraph-proc). Exiting."
fi
fi
...
trace_options文件:
1
2
[root@xdlinux ➜ kernel git:(master) ✗ ]$ find /sys/kernel/tracing -name trace_options
/sys/kernel/tracing/trace_options
当前实验结果只有中断调用栈,搜了下如果不跟踪中断呢:使用ftrace追踪内核函数调用
- 修改:拷贝一份
funcgraph脚本修改:cp funcgraph tmp_funcgraph,添加:echo nofuncgraph-irqs > trace_options - 结果:(靠巧合)追踪到一个相关调用栈了
问题:(原因待定位 TODO)
- 虽然靠巧合追踪到了堆栈,但多试几次读取发现堆栈又没了
- 对比
trace_options文件(cat出来),ecs环境里多了nopause-on-trace- 试了下
echo nopause-on-trace > trace_options,起funcgraph报错echo: write error: Invalid argument
- 试了下
1
2
3
4
5
[root@xdlinux ➜ kernel git:(master) ✗ ]$ diff trace_options_ecs trace_options_centos8
23d22
< nopause-on-trace
[root@xdlinux ➜ kernel git:(master) ✗ ]$ grep nopause-on-trace trace_options_*
trace_options_ecs:nopause-on-trace
追踪结果如下,可以看到xfs相关流程了:vfs_read -> __vfs_read -> new_sync_read -> xfs_file_read_iter 里面会经过pagecache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
[root@xdlinux ➜ kernel git:(master) ✗ ]$ ./tmp_funcgraph -H -p 9294 vfs_read
Tracing "vfs_read" for PID 9294... Ctrl-C to end.
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
10) | vfs_read() {
10) 7.314 us | }
10) | vfs_read() {
10) | rw_verify_area() {
10) | security_file_permission() {
10) 0.031 us | bpf_lsm_file_permission();
10) | __fsnotify_parent() {
10) 0.040 us | dget_parent();
10) | dput() {
10) | dput.part.34() {
10) | _cond_resched() {
10) 0.030 us | rcu_all_qs();
10) 0.221 us | }
10) 0.461 us | }
10) 0.641 us | }
10) 1.232 us | }
10) 0.040 us | fsnotify();
10) 1.964 us | }
10) 2.144 us | }
10) | __vfs_read() {
10) | new_sync_read() {
10) | xfs_file_read_iter [xfs]() {
10) | xfs_file_buffered_aio_read [xfs]() {
10) | xfs_ilock [xfs]() {
10) | down_read() {
10) | _cond_resched() {
10) 0.030 us | rcu_all_qs();
10) 0.220 us | }
10) 0.411 us | }
10) 0.591 us | }
10) | generic_file_read_iter() {
10) | generic_file_buffered_read() {
10) | _cond_resched() {
10) 0.020 us | rcu_all_qs();
10) 0.240 us | }
10) | pagecache_get_page() {
10) | find_get_entry() {
10) 0.030 us | PageHuge();
10) 0.270 us | }
10) 0.471 us | }
10) | touch_atime() {
10) | atime_needs_update() {
10) | current_time() {
10) 0.030 us | ktime_get_coarse_real_ts64();
10) 0.030 us | timestamp_truncate();
10) 0.431 us | }
10) 0.631 us | }
10) 0.832 us | }
10) 2.094 us | }
10) 2.284 us | }
10) | xfs_iunlock [xfs]() {
10) 0.031 us | up_read();
10) 0.231 us | }
10) 3.627 us | }
10) 3.827 us | }
10) 4.077 us | }
10) 4.278 us | }
10) 6.793 us | }
4.4.4. 映证读取代码逻辑
通过上面ext4和xfs的读取堆栈,可看到都是走了new_sync_read,通过f_op->read_iter进行读取,而没有走f_op->read分支。
可以往前翻下struct file_operations xfs_file_operations 定义时没有直接注册read、write等接口,而是read_iter、write_iter,跟这里是对应的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// linux-5.10.10/fs/read_write.c
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
...
ret = rw_verify_area(READ, file, pos, count);
...
if (file->f_op->read)
// 调用具体文件系统的 read
ret = file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
// 里面调用具体文件系统的 read_iter
// `read` 常用于简单的同步 I/O,适合标准文件系统操作;`read_iter` 则在需要最大效率的文件系统或高负载的应用中更有用
// `read_iter` 更适合高性能的异步操作,而 `read` 是传统的阻塞操作
ret = new_sync_read(file, buf, count, pos);
else
ret = -EINVAL;
if (ret > 0) {
fsnotify_access(file);
add_rchar(current, ret);
}
...
}
另外看下5.10内核的ext4文件系统file_operations定义,也是只注册了read_iter而没有read(上面3.10内核是read)
对比:5.10 read_iter; 3.10 read和aio_read
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// linux-5.10.10/fs/ext4/file.c
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.iopoll = iomap_dio_iopoll,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
};
5. 小结
学习梳理内核中文件系统相关的结构定义,并进行eBPF跟踪读取流程。
限于篇幅,写入流程单独再实验跟踪。
开头的问题:”read 文件一个字节实际会发生多大的磁盘IO?”,此处直接贴一下参考链接的说明。
- Page Cache 是以页为单位的,Linux 页大小一般是 4KB
- 如果 Page Cache 命中的话,根本就没有磁盘 IO 产生
- 文件系统是以块(block)为单位来管理的。使用 dumpe2fs 可以查看,一般一个块默认是 4KB
- 说明:ext系列用
dumpe2fs,xfs则是xfs_info
- 说明:ext系列用
- 通用块层是以段为单位来处理磁盘 IO 请求的,一个段为一个页或者是页的一部分
- IO 调度程序通过 DMA 方式传输 N 个扇区到内存,扇区一般为 512 字节
- 硬盘也是采用“扇区”的管理和传输数据的
- 现在的磁盘本身就会带一块缓存。另外现在的服务器都会组建磁盘阵列,在磁盘阵列里的核心硬件Raid卡里也会集成RAM作为缓存。
- 只有所有的缓存都不命中的时候,机械轴带着磁头才会真正工作。
虽然我们从用户角度确实是只读了 1 个字节。但是在整个内核工作流中,最小的工作单位是磁盘的扇区,为512字节,比1个字节要大的多。
另外 block、page cache 等高层组件工作单位更大。其中 Page Cache 的大小是一个内存页 4KB。所以一般一次磁盘读取是多个扇区(512字节)一起进行的。假设通用块层 IO 的段就是一个内存页的话,一次磁盘 IO 就是 4 KB(8 个 512 字节的扇区)一起进行读取。
6. 参考
5、GPT