MySQL学习实践(二) -- MySQL事务
MySQL学习实践,本篇学习梳理MySQL事务。
1. 背景
本篇梳理学习MySQL事务。
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 事务特性
ACID:
- 原子性(Atomicity):一个事务中的所有操作,要么全部完成,要么全部不完成
- 一致性(Consistency):事务操作前和操作后,数据满足完整性约束,数据库保持一致性状态
- 隔离性(Isolation):多个事务并发执行使用相同的数据时,不会相互干扰
- 持久性(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失
InnoDB引擎通过如下技术保证事务的ACID特性:
持久性通过redo log(重做日志)来保证原子性通过undo log(回滚日志)来保证隔离性通过MVCC(多版本并发控制)或锁机制来保证一致性通过持久性+原子性+隔离性来保证
事务是由MySQL的引擎来实现的,InnoDB引擎是支持事务的,而MySQL原生的MyISAM引擎不支持事务。
3. 事务隔离级别
3.1. 事务并行存在的问题
隔离性(ACID中的Isolation):多个事务同时执行的时候,可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)问题。
脏读:一个事务读到了另一个未提交事务修改过的数据。- 场景:事务A和B均访问相同数据,A修改数据后提交事务前,事务B读取数据,但是事务A回滚了之前修改操作然后提交事务,B之前读取的数据就是过期数据
不可重复读:在一个事务内多次读取同一个数据,前后两次读到的数据不一样- 场景:事务A和B均访问相同数据,A读取数据,B修改数据并提交事务,事务A再次读取数据,发现同一个事务中两次读取的数据不同
幻读:在一个事务内多次查询某个符合查询条件的记录数,前后两次读取的记录数量不一样- 场景:事务A和B均查询某个条件的记录,A插入一条满足条件的新数据并提交事务,B再次查询发现前后结果不同(即同一个事务中查询两次),像产生了”幻觉”
严重程度排序:脏读 > 不可重复读 > 幻读
3.2. 4种隔离级别
为了解决这些问题,于是有了不同的隔离级别。
SQL标准的4种事务隔离级别:
- 读未提交(read uncommitted),事务未提交时,其做的变更就能被其他事务看到
- 可能出现:脏读、不可重复读、幻读
- 读提交(read committed),事务提交后,其变更才能被其他事务看到
- 可能出现:不可重复读、幻读
- 可重复读(repeatable read),事务提交前,看到的数据和事务启动时一直是一致的
- 可能出现:幻读
InnoDB引擎默认该隔离级别。虽然该级别可能出现幻读,但InnoDB很大程度上避免了幻读现象(并不是完全解决)快照读(普通 select 语句)通过MVCC方式解决了幻读(具体下面对应的小节);当前读(select … for update 等语句)通过next-key lock(记录锁+间隙锁)方式解决了幻读- 可参考:MySQL 可重复读隔离级别,完全解决幻读了吗?
- 串行化(serializable),通过加锁(读写锁)机制,读写锁冲突时,后访问的事务必须等待前一个事务执行完成,才能继续执行
- 上述3种问题都不会出现,但性能低
隔离级别排序:串行化 > 可重复读 > 读提交 > 读未提交。隔离级别越高,性能效率就越低。
当前会话隔离级别:可看到默认级别是可重复读
1
2
3
4
5
6
7
mysql> show variables like 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
1 row in set (0.01 sec)
全局隔离级别:默认也是可重复读
1
2
3
4
5
6
7
mysql> show global variables like 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
1 row in set (0.01 sec)
4. 事务隔离的实现
4.1. 总体说明
上述4种隔离级别的实现方式:
读未提交隔离级别的事务:因为可以读到未提交事务修改的数据,所以直接读取最新的数据就好读提交和可重复读隔离级别的事务:都是通过Read View来实现的,它们的区别在于创建Read View的时机不同读提交是在 每个语句执行前 都会重新生成一个Read View可重复读是在 启动事务时 生成一个Read View,然后整个事务期间都在用这个Read View
串行化隔离级别的事务:通过读写锁避免并行事务访问
注意:启动事务和开始事务/开启事务有区别,开始并不代表启动了
MySQL有2种开启事务的命令,对应的启动事务时机是不同的:
- 1、
begin/start transaction命令。执行后并不代表事务启动了,之后执行了第一条select语句,才是事务真正启动的时机。- 配套的提交语句是
commit,回滚语句是rollback
- 配套的提交语句是
- 2、start transaction with consistent snapshot 命令。执行后就会马上启动事务。
上面所述的不同时刻启动的事务会有不同的Read View,同一条记录在系统中可以存在多个版本,这就是数据库的 MVCC(多版本并发控制,Multi-Version Concurrency Control) 机制。
MySQL InnoDB引擎实现的MVCC,主要依赖数据行的 隐式字段 与 undo log 生成的日志版本链,再结合Read View可见性判断机制实现。
4.1.1. 隐式字段
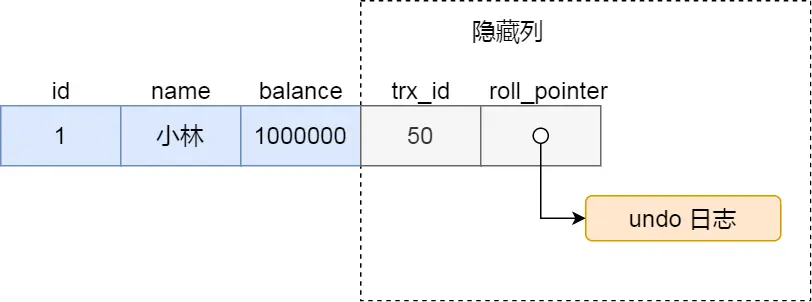
InnoDB向数据库中存储的每一行添加三个字段:
DB_ROW_ID:隐藏的自增ID,对于MVCC可忽略该字段- 如果InnoDB自动生成聚集索引,则索引包含这个行ID值。否则,
DB_ROW_ID列不会出现在任何索引中
- 如果InnoDB自动生成聚集索引,则索引包含这个行ID值。否则,
DB_TRX_ID:插入或更新行的最后一个事务ID,用于MVCC的Read View判断事务idDB_ROLL_PTR:回滚指针,用于MVCC中指向undo log记录
对于使用InnoDB存储引擎的数据库表,它的聚簇索引记录中都包含DB_TRX_ID和DB_ROLL_PTR两个隐藏列。插入一条记录,记录示意如下图所示:
对应逻辑在dict_table_add_system_columns中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// mysql-server_8.0.26/storage/innobase/dict/dict0dict.cc
void dict_table_add_system_columns(dict_table_t *table, mem_heap_t *heap) {
...
dict_mem_table_add_col(table, heap, "DB_ROW_ID", DATA_SYS,
DATA_ROW_ID | DATA_NOT_NULL, DATA_ROW_ID_LEN, false);
dict_mem_table_add_col(table, heap, "DB_TRX_ID", DATA_SYS,
DATA_TRX_ID | DATA_NOT_NULL, DATA_TRX_ID_LEN, false);
if (!table->is_intrinsic()) {
dict_mem_table_add_col(table, heap, "DB_ROLL_PTR", DATA_SYS,
DATA_ROLL_PTR | DATA_NOT_NULL, DATA_ROLL_PTR_LEN,
false);
}
}
4.1.2. undo log
在事务中,insert/update/delete每一个sql语句的更改都会写入undo log,当事务回滚时,可以利用 undo log 来进行回滚。
undo log相关操作在trx_undo_report_row_operation函数中(mysql-server_8.0.26/storage/innobase/trx/trx0rec.cc)
- insert undo log:指在
insert操作中产生的undo log,仅用于事务回滚- 因为insert操作的记录只对事务本身可见,对其它事务不可见,所以该日志可以在事务
commit后直接删除,不需要进行purge(后台清除线程)操作 - 对应函数:
trx_undo_page_report_insert
- 因为insert操作的记录只对事务本身可见,对其它事务不可见,所以该日志可以在事务
- update undo log:对
delete和update操作产生的的undo log- 该undo log可能需要提供MVCC机制,因此不能在事务commit后就进行删除。提交时放入undo log链表,等待
purge(后台清除线程)进行最后的删除 - 对应函数:
trx_undo_page_report_modify
- 该undo log可能需要提供MVCC机制,因此不能在事务commit后就进行删除。提交时放入undo log链表,等待
- 相关流程梳理可参考:【MySQL】MVCC原理分析 + 源码解读,此处暂不展开分析。
4.1.3. Read View
ReadView定义在read0types.h中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// mysql-server_8.0.26/storage/innobase/include/read0types.h
class ReadView {
// 类似于vector
class ids_t {
...
ulint capacity() const { return (m_reserved); }
void assign(const value_type *start, const value_type *end);
void insert(value_type value);
...
void push_back(value_type value);
...
};
...
inline void prepare(trx_id_t id);
inline void copy_prepare(const ReadView &other);
inline void copy_complete();
void creator_trx_id(trx_id_t id) {
...
}
private:
// 尚未分配的最小事务id,>= 这个ID的事务均不可见
trx_id_t m_low_limit_id;
// 最小活动未提交事务id,< 这个ID的事务均可见
trx_id_t m_up_limit_id;
// 创建该 Read View 的事务ID
trx_id_t m_creator_trx_id;
// 创建视图时的所有活跃未提交事务id列表
ids_t m_ids;
trx_id_t m_low_limit_no;
trx_id_t m_view_low_limit_no;
// 标记视图是否被关闭
bool m_closed;
typedef UT_LIST_NODE_T(ReadView) node_t;
byte pad1[64 - sizeof(node_t)];
node_t m_view_list;
};
参考链接里的4个重要字段:m_ids、min_trx_id、max_trx_id、creator_trx_id,和上述类定义对应(其中min_trx_id对应m_low_limit_id)。
部分内联函数在声明时实现了,其余函数实现在:mysql-server_8.0.26/storage/innobase/read/read0read.cc中,此处不做展开,后续再深入梳理。
4.2. 可重复读 过程说明
可重复读的过程说明(启动事务时创建Read View):
- 开始事务后(执行
begin语句后),并在执行第一个查询语句(select)后,会创建一个Read View,后续的查询语句利用这个Read View,通过这个Read View就可以在undo log版本链找到事务开始时的数据,所以事务过程中每次查询的数据都是一样的,即使中途有其他事务插入了新纪录,是查询不出来这条数据的,所以就很好了避免幻读问题。
结合上面的4个重要字段和参考链接的示例:
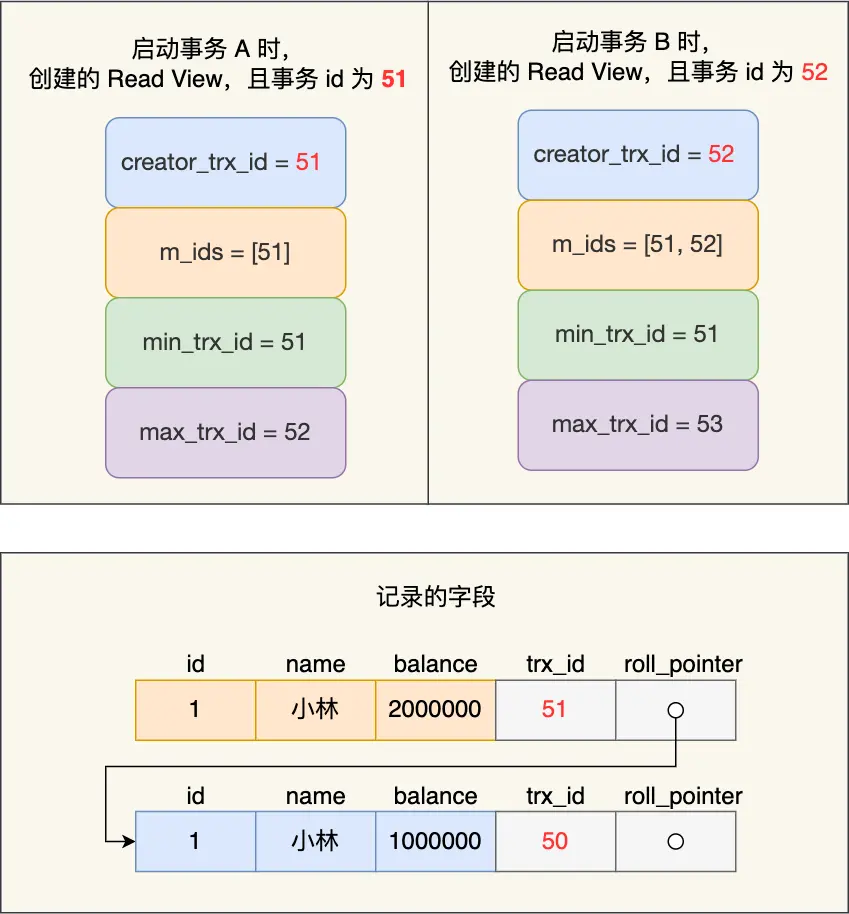
- 原有记录的事务id为50
- 余额记录为 100 万
- 两个新事务:事务A(事务id为51)和事务B(事务id为52)
- 事务 A 将余额记录修改成200万,并没有提交事务。此次修改,以前的记录就变成旧版本记录了,于是最新记录和旧版本记录通过链表的方式串起来,而且最新记录的
trx_id是事务 A 的事务 id(trx_id = 51) - 然后事务 B 第二次去读取该记录,发现这条记录的
trx_id值为 51,在事务 B 的 Read View 的min_trx_id和max_trx_id之间,且在m_ids范围内,说明这条记录是被还未提交的事务修改的,这时事务 B 并不会读取这个版本的记录。 - 于是沿着
undo log 链条往下找旧版本的记录,直到找到trx_id小于 事务 B 的 Read View 中的min_trx_id值的第一条记录,所以事务 B 能读取到的是trx_id为 50 的记录,读取到余额为100万
- 事务 A 将余额记录修改成200万,并没有提交事务。此次修改,以前的记录就变成旧版本记录了,于是最新记录和旧版本记录通过链表的方式串起来,而且最新记录的
4.3. 读提交 过程说明
读提交的过程说明(每次读取数据时创建Read View):
- 事务A、事务B。
- 事务A修改后提交,对应行记录的
trx_id会+1 - 由于隔离级别是
读提交,所以事务 B 在每次读数据的时候,会重新创建Read View(其trx_id会加1),会发现其中的min_trx_id更小,这意味着修改这条记录的事务早就在创建 Read View 前提交过了,所以该版本的记录对事务 B 是可见的。
4.4. 事务类定义
事务类struct trx_t定义如下,可看到前面小节对应的4种隔离级别枚举值。
InnoDB引擎中的源代码文件一般为xx0yy.h/xx0yy.cc形式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// mysql-server_8.0.26/storage/innobase/include/trx0trx.h
struct trx_t {
// 4种隔离级别枚举
enum isolation_level_t {
READ_UNCOMMITTED,
READ_COMMITTED,
REPEATABLE_READ,
SERIALIZABLE
};
...
mutable TrxMutex mutex;
...
trx_id_t id; /*!< transaction id */
trx_id_t no; /*!< transaction serialization number */
std::atomic<trx_state_t> state;
bool skip_lock_inheritance;
ReadView *read_view; /*!< consistent read view used in the
transaction, or NULL if not yet set */
UT_LIST_NODE_T(trx_t) no_list;
...
bool is_read_uncommitted() const {
return (isolation_level == READ_UNCOMMITTED);
}
...
};
事务系统trx_sys_t定义在trx0sys.h中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// mysql-server_8.0.26/storage/innobase/include/trx0sys.h
struct trx_sys_t {
// 代码中有很多cache line对齐的处理,减少缓存污染(cache thrashing),提升性能
char pad0[ut::INNODB_CACHE_LINE_SIZE];
// 多版本并发控制管理
MVCC *mvcc;
// rollback segments
Rsegs rsegs;
Rsegs tmp_rsegs;
char pad1[ut::INNODB_CACHE_LINE_SIZE];
// 用于生成下一个事务ID
std::atomic<trx_id_t> next_trx_id_or_no;
...
// 事务在完全提交之前会保持在这个列表中,确保事务的正确序列化顺序
UT_LIST_BASE_NODE_T(trx_t, no_list) serialisation_list;
// 当前活跃事务的最大事务号
trx_id_t rw_max_trx_no;
// 确保下一个成员变量与前一个成员变量位于不同的缓存行上,以避免缓存竞争(cache contention)
char pad3[ut::INNODB_CACHE_LINE_SIZE];
// 用于管理事务序列化级别下的最小事务号。这在事务隔离级别为可重复读(REPEATABLE READ)或更高时尤为重要
std::atomic<trx_id_t> serialisation_min_trx_no;
...
// 当前系统中最旧活跃事务的事务ID,这对于确定哪些事务可以提交或回滚非常重要
std::atomic<trx_id_t> min_active_trx_id;
char pad5[ut::INNODB_CACHE_LINE_SIZE];
// 管理当前活跃的读写事务
// 列表是根据事务ID (trx_id) 排序的,最大的事务ID排在最前面
UT_LIST_BASE_NODE_T(trx_t, trx_list) rw_trx_list;
char pad6[ut::INNODB_CACHE_LINE_SIZE];
// 管理MySQL客户端发起的事务
UT_LIST_BASE_NODE_T(trx_t, mysql_trx_list) mysql_trx_list;
// 用于MVCC快照管理,存储当前活跃的读写事务ID
// 当一个事务创建一个ReadView时,它会基于rw_trx_ids中的事务ID创建一个快照(snapshot),这个快照决定了哪些更改对该事务是可见的
trx_ids_t rw_trx_ids;
// 当前系统中的最大事务ID
std::atomic<trx_id_t> rw_max_trx_id;
...
};
5. 小结
梳理学习事务并行时可能存在的问题,MySQL中InnoDB引擎的事务隔离逻辑,简要实现流程学习,初步查看相关代码,后续按需再深入梳理。
6. 参考
1、MySQL实战45讲-3 事务隔离:为什么你改了我还看不见?
4、数据库内核月报-2015/04:MySQL · 引擎特性 · InnoDB undo log 漫游
5、MySQL · 源码分析 · InnoDB的read view,回滚段和purge过程简介
7、GPT