Rust学习实践(一) -- 总体说明和Rust基础
Rust学习实践,本篇为开篇,总体说明和Rust基础。
1. 背景
之前学过Rust基本使用,间隔时间有点长且实践较少,遗忘了很多,重新学习一下。
Rust的优势此处不做过多描述,可参见这篇介绍(“自夸”):进入 Rust 编程世界
前面还留了不少坑待填,暂时放一放:
- 网络方面,TCP发送接收过程(二) – 实际案例看TCP性能和窗口、Buffer的关系拥塞 占了坑但一直还没去实践:BDP,结合Wireshark的TCP Stream Graghs看网络性能变化
- 6.824,目前只看了MapReduce、GFS、Raft的论文和课程,还没做lab,以及结合Go相关特性实验,etcd/braft的raft实现待看
- 深入MySQL系列还未完结又开新坑,MySQL学习实践(三) – MySQL索引 目前(9.17)只梳理了小部分,而且其他内容还有不少
- 关于基础,网络、存储目前还算看了一些,CPU(进程)、内存还没投入进去看
- …
几点随想:
- 之前看文章看到Draven大佬2020总结里提到用
OKR管理个人目标,正好在尝试用工作上的Scrum敏捷模式管理自己的工作以外部分事项的进度,收获不少,自己后续也可以按这个方式调整下(OKR+Scrum) - 看木鸟杂记大佬的文章,提到课代表立正,去看了下up主讲的一些方法论和思路,让自己的想法拓展和清晰不少,也很有收获,工作/学习/生活里可以借鉴参考
- 想法:多输入,多输出,产生正循环,让“飞轮”滚动起来
学习实践环境说明:
- Mac:原来学习时是
rustc 1.44.0(2020),升级一下:rustup update,升级后当前版本为rustc 1.81.0(2024-09-04) - CentOS 8.5:之前重装过系统,这次安装下rust
curl https://sh.rustup.rs -sSf | sh,安装的版本也是当前最新的stable版本:rust version 1.81.0 (eeb90cda1 2024-09-04)
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 学习参考资料
网站:
- 官网
- 官方GitHub
- 官网 – 学习Rust 里面推荐了一些开源学习资料,也包括下面提及的部分开源书籍
一、基础内容
- The Rust Programming Language
- 中文翻译版:Rust 程序设计语言
Rustacean中文意思为 Rust 开发者,Rust 用户,Rust 爱好者。注意,Rust开发者不要写成Ruster,另外 Rustacean 一般第一个字母为大写形式,就和 Rust 一样,参考
- 《Rust 程序设计语言》被亲切地称为“圣经”,其中文出版书名为《Rust 权威指南》
- 中文翻译版:Rust 程序设计语言
- Rust开源教程:Rust语言圣经(Rust Course)
- Rust Cookbook
- 极客时间:陈天 · Rust 编程第一课
- rust常用的crates
二、进阶
- The Rustonomicon
- 中文版:Rust 秘典(死灵书)
- 《Rust 秘典》是 Unsafe Rust 的黑魔法指南。它有时被称作“死灵书”
- Rust官方RFC文档
- Rust设计模式
3. Rust基础
前置说明:
- 1、基于《The Rust Programming Language》(中文版:Rust 程序设计语言)大概过一下,部分术语的英文表达参考这里。之前的初步学习笔记在:Rust.md
- 2、上述罗列的参考资料大概看了一下,Rust开源教程:Rust语言圣经(Rust Course) 的内容比较贴合自己当前的偏好,先基于该教程学习梳理,其他作为辅助。
- 3、代码练习还是复用之前的仓库:rust_learning
- 4、VSCode插件(结合《Rust编程第一课》和 墙推 VSCode! 中推荐的插件)
rust-analyzer:它会实时编译和分析你的 Rust 代码,提示代码中的错误,并对类型进行标注。你也可以使用官方的 Rust 插件取代。- 官方的
Rust插件已经不维护了
- 官方的
cratesDependi:帮助你分析当前项目的依赖是否是最新的版本。- crates插件已经不维护了,主页中推荐切换为
Dependi,支持多种语言的依赖管理:Rust, Go, JavaScript, TypeScript, Python and PHP
- crates插件已经不维护了,主页中推荐切换为
better tomlEven Better TOML:Rust 使用 toml 做项目的配置管理。该插件可以帮你语法高亮,并展示 toml 文件中的错误。- better toml插件也不维护了,其主页推荐切换为
Even Better TOML
- better toml插件也不维护了,其主页推荐切换为
Error Lens:更好的获得错误展示,包括错误代码、错误类型、错误位置等- 提示有点密,按需要在单独的workpsace中启用,感觉markdown中提示太频繁了,暂时关闭并仅在此处Rust练习工程中启用
CodeLLDB:Debugger程序,可以调试Rust代码- 其他插件,暂不安装
rust syntax:为代码提供语法高亮(有必要性?前面插件会提供语法高亮)rust test lens:rust test lens:可以帮你快速运行某个 Rust 测试(也不维护更新了)Tabnine:基于 AI 的自动补全,可以帮助你更快地撰写代码(暂时用智普AI的CodeGeeX插件,当作Copilot平替)
3.1. 编译说明
两种方式:
rustc方式:rustc main.rscargo方式:cargo build编译、cargo run运行(若未编译则会先编译)、cargo check只检查不编译- Rust 项目主要分为两个类型:
bin和lib,前者是一个可运行的项目,后者是一个依赖库项目 - 当前cargo默认就创建
bin类型的项目,也可显式指定:cargo new hello_world --bin。(早期的cargo在创建项目时,则需要--bin的参数)
- Rust 项目主要分为两个类型:
以 hello_cargo 为例,说明下cargo编译生成的内容:
Cargo.lock:记录了所有直接依赖和间接依赖的确切版本,确保了项目的依赖关系在每次构建时都保持一致- 倾向于将 Cargo.lock 文件包含在版本控制系统中
- 运行 cargo build 或其他 Cargo 命令时,Cargo 不会从互联网上拉取依赖项的最新版本,而是会使用 Cargo.lock 中记录的确切版本。这样可以确保所有构建都是一致的,并且避免了由于依赖项版本更新而导致的潜在问题。
target目录:这是Cargo用来存放所有编译输出的地方CACHEDIR.TAG:一个特殊的文件,用来标记这个目录是一个缓存目录,不应该被包含在版本控制中debug或者release:分别对应debug模式和release模式,debug模式会包含调试信息,release模式则会进行优化debug/deps目录:存放了所有依赖的编译输出,包含二进制文件(hello_cargo-70b7650f2196efb1和debug/hello_cargo是同一个文件)target/debug/build目录:若toml里通过build指定了构建脚本,则对应输出会在该目录target/debug/examples目录:如果项目包含示例程序(在examples目录下的.rs文件),那么这些程序会被编译并放置在这个目录下target/debug/hello_cargo:项目的主可执行文件target/debug/incremental:该目录存储了增量编译的信息,使得Cargo能够在再次编译时跳过那些没有变化的代码部分,从而加快编译速度target/debug/hello_cargo.d和其他.d文件:这些文件用于支持增量编译。它们记录了编译过程中的依赖关系,帮助Cargo决定哪些模块需要重新编译
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# build编译前
[CentOS-root@xdlinux ➜ hello_cargo git:(master) ✗ ]$ tree
.
├── Cargo.toml
└── src
└── main.rs
# cargo build
[CentOS-root@xdlinux ➜ hello_cargo git:(master) ✗ ]$ cargo build
Compiling hello_cargo v0.1.0 (/home/workspace/rust_path/rust_learning/hello_cargo)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
[CentOS-root@xdlinux ➜ hello_cargo git:(master) ✗ ]$ tree
.
├── Cargo.lock
├── Cargo.toml
├── src
│ └── main.rs
└── target
├── CACHEDIR.TAG
└── debug
├── build
├── deps
│ ├── hello_cargo-70b7650f2196efb1
│ └── hello_cargo-70b7650f2196efb1.d
├── examples
├── hello_cargo
├── hello_cargo.d
└── incremental
└── hello_cargo-3haf20exhib74
├── s-h00uhsc9pb-05zloq4-45etctwclne9bdzz71m5zmpm7
│ ├── 0bcqf7ztek5t6s4d87ed816uz.o
│ ├── 0vf1n5voilrp7673zix3s1mk8.o
│ ├── 48zynk25prcjtyan91sp1xfvo.o
│ ├── 53zmz46glgdq0hhcx61nbxdn6.o
│ ├── 61k02pkquc42pjwqtetozi8sf.o
│ ├── 6oeh93pcajoe4x07y2xnxmueg.o
│ ├── 76cr3fg6p6n8csy70e1d5ugvs.o
│ ├── al8okrhaqv7m0kggosakeijdw.o
│ ├── b4wsfus5ugvvekyy3brvvakrf.o
│ ├── dep-graph.bin
│ ├── dqqzbj9vq1ggxsduc75riz3xs.o
│ ├── e39bv2imh011dqqelnop4qaf6.o
│ ├── query-cache.bin
│ └── work-products.bin
└── s-h00uhsc9pb-05zloq4.lock
9 directories, 23 files
结果物说明:相对于Go编译产物,rust运行时还是需要依赖系统libc库(Go自带运行时,不需要依赖libc和其他库即可运行,更便于分发)
3.2. 基本类型和函数
- 变量绑定:
let a = "hello world"- Rust 的变量在默认情况下是不可变的,可通过
mut关键字让变量变为可变:let a mut = "hello world" - 创建了一个变量却不在任何地方使用它,Rust通常会给一个警告,可以用下划线作为变量名的开头来消除警告:
let _x = 5;
- Rust 的变量在默认情况下是不可变的,可通过
- 整型:
i8/u8、i16/u16、i32/u32、i64/u64、i128/u128、isize/usize- 不指定则默认
i32
- 不指定则默认
- 浮点型:
f32/f64 - 序列(Range):
1..5表示1, 2, 3, 4,1..=5表示1, 2, 3, 4, 5for i in 1..5:i是1..5的迭代器- 序列只允许用于
数字或字符类型
- 单元类型:只有一个,唯一的值就是
(),是一个零长度的元组- 例如常见的
println!()的返回值也是单元类型() - 比如,可以用
()作为map的值,表示我们不关注具体的值,只关注key。 这种用法和 Go 语言的struct{}类似,可以作为一个值用来占位,但是完全不占用任何内存。
- 例如常见的
- 语句(
statement)和表达式(expression)- 语句会执行一些操作但是不会返回一个值,而表达式会在求值后总有一个返回值
- 表达式不能包含分号,否则就变成一条语句
- 表达式如果不返回任何值,会隐式地返回一个
()单元类型
关于语句和表达式,需要能区分开。示例:使用一个语句块表达式将值赋给y变量
1
2
3
4
5
6
7
8
fn main() {
let y = {
let x = 3;
x + 1
};
println!("The value of y is: {}", y);
}
注意:x + 1不能以分号结尾,否则就会从表达式变成语句, 表达式不能包含分号。这一点非常重要,一旦在表达式后加上分号,它就会变成一条语句,再也不会返回一个值。
- 函数
- 函数命名规则:蛇形命名法(snake case),即小写字母,单词之间用下划线连接,比如
fn add_two() -> i32 {} - 函数的位置可以随便放,Rust 不关心我们在哪里定义了函数,只要有定义即可(不像C/C++,需要声明在前)
- 每个函数参数都需要标注类型
- 返回值:
- 表达一个函数没有返回值:
fn test(i: i32) {}或者fn test(i: i32) -> () {},返回值类型都是单元类型() - 发散函数(
diverging function):fn dead_end() -> ! { xxx },!是一个特殊标记,表示空类型,表示函数永不返回(diverge function),这种语法往往用做 终止进程 或者 永远循环 的函数,比如下面的示例fn dead_end() -> ! { panic!("This call never returns") }fn forever() -> ! { loop {} }
- 表达一个函数没有返回值:
- 函数命名规则:蛇形命名法(snake case),即小写字母,单词之间用下划线连接,比如
表达式返回值示例:
1
2
3
4
fn add(i: i32, j: i32) -> i32 {
// 这里没有分号,是一个表达式,返回值就是 i + j;也可以用return语句显式返回
i + j
}
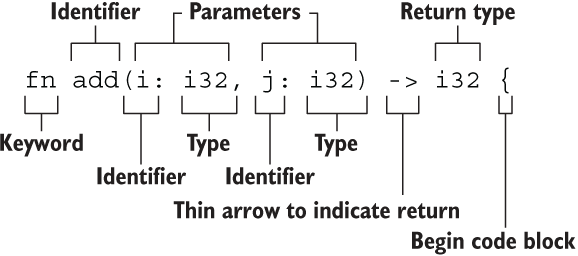
Rust函数构成结构示意图:
- 闭包(closures):Rust的
闭包是可以保存在变量中或作为参数传递给其他函数的匿名函数(类比C++中的lamba表达式 和 Go的匿名函数)- 闭包通常不要求像
fn函数那样对参数和返回值进行类型注解(fn是因为要显式暴露给用户,达成一致理解) - 闭包通常较短,并且只与特定的上下文相关,而不是适用于任意情境。在这些有限的上下文中,编译器可以推断参数和返回值的类型,类似于它推断大多数变量类型的方式
- 闭包:可以捕获环境的匿名函数
- 闭包通常不要求像
闭包示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
let expensive_closure = |num: u32| -> u32 {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};
// 下述定义都是正常的
// 定义函数
fn add_one_v1 (x: u32) -> u32 { x + 1 }
// 完整闭包定义
let add_one_v2 = |x: u32| -> u32 { x + 1 };
// 省略了类型注解 的闭包定义
let add_one_v3 = |x| { x + 1 };
// 去掉了可选的大括号 的闭包定义
let add_one_v4 = |x| x + 1 ;
可在 Rust By Practice 上进行练习,直接网页上修改运行即可。
3.3. 流程控制
- 分支控制(
if/else if/else)- if 语句块是表达式,因此可以赋值给变量:
let number = if condition { 5 } else { 6 };
- if 语句块是表达式,因此可以赋值给变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
fn main() {
let n = 6;
if n % 4 == 0 {
println!("number is divisible by 4");
} else if n % 3 == 0 {
println!("number is divisible by 3");
} else if n % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
}
- 3种循环控制方式:
for、while和loop- break 可以单独使用,也可以带一个返回值,有些类似 return
- loop 是一个表达式,因此可以返回一个值
- 相对而言,
for比while和loop更常用,因为for可以遍历序列,而while和loop需要手动控制循环条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
fn test_for() {
// 从1到5,包含5
for i in 1..=5 {
println!("{}", i);
}
// 若不需要使用控制变量,可以用 _ 来忽略变量,否则定义了不使用会有编译警告
for _ in 1..=5 {
println!("loop again");
}
}
fn test_while() {
let mut n = 0;
while n <= 5 {
println!("{}!", n);
n = n + 1;
}
println!("test_while end!");
}
fn test_loop() {
let mut n = 0;
loop {
if n > 5 {
// 加不加分号都可以,因为loop是一个表达式,可以返回值
break
}
println!("{}", n);
n+=1;
}
println!("test_loop end!");
}
3.4. 所有权和借用
所有权(ownership)的规则:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的
所有者 - 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
基本类型(比如整型)在编译时是已知大小的,会被存储在栈上,不会发生所有权转移(transfer ownership)。比如如下示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
fn test_owner_ship() {
let s = String::from("hello");
// 所有权转移,会影响s的生命周期;若需要拷贝,则可以使用 s.clone()
// let s2 = s;
println!("{}", s);
task_ownership(s);
// 这里所有权转移到task_ownership后,已经释放了s,所以这里会报错
// println!("{}", s);
println!("===============");
let n = 888;
// 这里不影响n的所有权,基本类型不会发生所有权转移
let n2 = n;
println!("n: {}, n2: {}", n, n2);
}
fn task_ownership( s : String ) {
println!("input string: {}", s);
// 调用结束后,s移出作用域,被释放
}
Rust有一个叫做Copy的特征,可以用在类似整型这样在栈中存储的类型,不会发生所有权转移。Copy特征判断规则:任何基本类型的组合可以Copy,不需要分配内存或某种形式资源的类型是可以Copy的。
下面都是具有Copy特征的类型:
- 所有整数类型、bool、浮点数类型、字符类型
char - 元组且其成员都是
Copy的,比如:(i32, i32)是 Copy 的,但(i32, String)就不是 - 不可变引用
&T- 比如:
let x: &str = "hello, world";,而后let y = x;,此处的x只是引用,所以不会发生所有权转移,此时y和x都引用了同一个字符串
- 比如:
上面的let x: &str = "hello, world";示例,此处的&str其实是借用。
借用(Borrowing):获取变量的引用,称之为借用(borrowing)。
&表示借用,*表示解引用(dereference)。- 比如:
let x = 5; let y = &x,*y就是5
- 比如:
- 引用指向的值默认是不可变(immutable)的
fn change(some_string: &String) { some_string.push_str(", world"); },这里some_string是借用,不能修改,会报错
可变引用(mutable reference):
可变引用可以解决上述问题,可修改引用指向的值fn change(some_string: &mut String) { some_string.push_str(", world"); },这里some_string是可变借用,可以修改- 需要在定义时指定
mut,传参时也指定mut。定义:let mut s = String::from("hello");,调用:change(&mut s);,否则会报错
- 同一作用域,特定数据只能有一个可变引用(脱离作用域后,引用失效,再进行可变引用不会报错)。编译器会进行
借用检查(borrow checker),确保引用有效性,在编译期就避免数据竞争(data race)- 数据竞争可能由下述行为造成
- 两个或更多的指针同时访问同一数据
- 至少有一个指针被用来写入数据
- 没有同步数据访问的机制
- 可通过大括号
{}手动限定变量的作用域,从而解决编译器借用检查的问题
- 数据竞争可能由下述行为造成
可变引用与不可变引用不能同时存在- Rust 的编译器一直在优化,早期的(
Rust 1.31前)编译器,引用的作用域跟变量作用域是一致的,这对日常使用带来了很大的困扰 - 但是在新的编译器中,引用作用域的结束位置从花括号变成
最后一次使用的位置 - 对于这种编译器优化行为,Rust 专门起了一个名字 ——
Non-Lexical Lifetimes(NLL),专门用于找到某个引用在作用域(})结束前就不再被使用的代码位置。
- Rust 的编译器一直在优化,早期的(
悬垂引用(dangling reference):
悬垂引用也叫做悬垂指针:指针指向某个值后,这个值被释放掉了,而指针仍然存在,其指向的内存可能 不存在任何值 或 已被其它变量重新使用。
Rust编译器中可以确保引用永远也不会变成悬垂状态。
3.5. 复合类型
- 结构体:
struct- 基本操作
- 结构体定义:
struct User { username: String, email: String } - 使用:
let user1 = User { username: String::from("test"), email: String::from("test@gmaild.com") }; - 访问,使用
.:println!("{}", user1.email);- Rust中的结构体,不存在使用
->进行访问成员(不像C/C++),使用.时会自动引用和解引用(automatic referencing and dereferencing)
- Rust中的结构体,不存在使用
- 修改:若需要修改,则需要定义为
let mut user1 = xxx,而后可修改赋值user1.username = "test222"
- 结构体定义:
- 结构体更新语法:
let user2 = User {email: String::from("another@example.com"), ..user1};..语法表明凡是我们没有显式声明的字段,全部从 user1 中自动获取。需要注意的是..user1必须在结构体的尾部使用。- 执行后,user1 的部分字段所有权被转移到 user2 中;user1无法再被使用,但其未转移所有权的其他字段(
Copy类型)可继续使用
- 结构体信息打印:使用
#[derive(Debug)]结合{:?}/{:#?},后者会带缩进- 如果要使用
{}来格式化输出,那对应的类型就必须实现Display特征,以前学习的基本类型,都默认实现了该特征(比如i32、f64等) #[derive(Debug)] struct Rectangle { width: u32, height: u32,}(继承实现了Debug特征)- 另外,还有个
dbg!宏,会拿走表达式的所有权,然后打印出相应的文件名、行号等debug信息,以及表达式求值结果。如:dbg!(&rect1)
- 如果要使用
- 基本操作
- 切片(slice):
[开始索引..终止索引](右边是开区间)- 切片是引用,所以不会发生所有权转移。
- 字符串切片:
let s = String::from("hello world");,let h = &s[0..5];,此处的h就是切片,表示字符串s的0到5个字符,即hello。h切片的类型为&str
- 数组切片:
let a = [1, 2, 3, 4, 5];,let slice = &a[1..3];,此处的slice就是切片,表示数组a的1到3个元素,即[2, 3]。- 该数组切片的类型是
&[i32]
- 该数组切片的类型是
- 字符串
- Rust 在语言级别,只有一种字符串类型:
str,它通常是以引用类型出现:&str,也就是上文提到的字符串切片。- Rust 中的
字符是Unicode类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是UTF-8编码,也就是字符串中的字符所占的字节数是变化的(1 - 4)
- Rust 中的
- 虽然语言级别只有上述的
str类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的即是String类型。 - 转换
&str生成String:String::from("hello,world")和"hello,world".to_string()String生成&str:let s = String::from("hello,world");,let s_slice: &str = &s;,即通过引用实现切片
String操作:push_str()追加字符串,push()追加单个字符。如s.push_str("rust");、s.push('!');insert_str和insert分别插入字符串和字符。如s.insert(5, ',');replace替换:如s.replace("rust", "Rust");replacen、replace_range、pop()、remove()、truncate()、clear()等
- Rust 在语言级别,只有一种字符串类型:
- 元组(tuple):多种类型组合
- 如
let tup = (500, 6.4, 1);,let (x, y, z) = tup; - 通过
.访问指定索引的元素,索引从0开始:let five_hundred = tup.0;
- 如
- 枚举(enum):定义一组类型,每个类型都有名字和一组相关的值
- 如
enum IpAddrKind { V4, V6 },let four = IpAddrKind::V4; Option 枚举:包含两个成员,一个成员表示含有值:Some(T), 另一个表示没有值:None- 定义如下:
enum Option<T> { Some(T), None, }。其中T是泛型参数,Some(T)表示该枚举成员的数据类型是T,换句话说,Some可以包含任何类型的数据。 - 使用示例:
let some_number = Some(5);,let some_string = Some("a string");,let absent_number: Option<i32> = None;
- 定义如下:
- 如
- 数组:固定大小的类型组合
- 如
let a = [1, 2, 3, 4, 5];,let a: [i32; 5] = [1, 2, 3, 4, 5];(i32 是元素类型,分号后面的数字5是数组长度),let a = [3; 5];(数组初始化为3,长度为5) - 在实际开发中,使用最多的是数组切片
[T],我们往往通过引用的方式去使用&[T],因为后者有固定的类型大小
- 如
3.6. 模式匹配
在 Rust 中,模式匹配(Pattern Matching)最常用的就是 match 和 if let。
match跟其他语言中的 switch case 非常像,_ 类似于 switch 中的 default。
- match 的匹配必须要穷举出所有可能,因此用
_来代表未列出的所有可能性 - match 的每一个分支都必须是一个表达式,且所有分支的表达式最终返回值的类型必须相同
- 如果分支有多行代码,那么需要用
{}包裹,同时最后一行代码需要是一个表达式 match本身也是一个表达式,因此可以用它来赋值:let ip_str = match ip1 { Direction::V4 => "IPv4", Direction::V6 => "IPv6" };
- 如果分支有多行代码,那么需要用
- 一个分支有两个部分:一个
模式和针对该模式的处理代码- 通过
=>运算符将模式和将要运行的代码分开,Direction::East => println!("East"),
- 通过
- 变量遮蔽:
match处理中若使用同名变量,会发生变量遮蔽,相当于新变量- match 中的变量遮蔽其实不是那么的容易看出,最好不要使用同名,避免难以理解
- 比如:
match some_number { Some(some_number) => println!("{}", some_number), },Some中绑定的some_number会遮蔽外部的some_number,最好是使用不同的变量名,如Some(value) => println!("{}", value),
示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
enum Direction {
East,
West,
North,
South,
}
fn main() {
let dire = Direction::South;
match dire {
// 每一个分支都是一个表达式
// 使用 `=>`运算符 进行模式匹配后的处理
Direction::East => println!("East"),
// 使用{}表达式,里面是语句块,可以包含多个语句
Direction::North | Direction::South => {
println!("South or North");
},
// 其他情况
_ => println!("West"),
};
}
- 模式绑定:可以在匹配过程中,将匹配到的值绑定到一个变量上,从枚举中提取值。具体可见:模式绑定
if let 匹配,当只需要匹配一个条件,且忽略其他条件时就可以用if let,否则都用match- 示例:
if let Some(x) = some_option_value { println!("x is {}", x); } - 若用
match方式,则需要写两个分支,如:match some_option_value { Some(x) => println!("x is {}", x), _ => (), }
- 示例:
3.7. 方法(Method)
Rust的方法(Method)和函数(Function)类似,区别在于方法是定义在某个类型上的,而函数是定义在某个作用域上的。
- Rust的对象定义和方法定义是分离的,对于其他语言(如C++、Java)来说,对象和方法的定义是放在一起的,都是放在类中。
self、&self和&mut selfself表示对象本身,&self表示对象的引用,&mut self表示可变引用- 对于下述示例,
self表示Point对象本身,&self表示Point对象的引用,&mut self表示可变引用
使用impl关键字来定义方法,并通过.访问,示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
struct Point {
x: i32,
y: i32,
}
impl Point {
// 定义一个关联函数,不需要实例化对象就可以调用
fn new(x: i32, y: i32) -> Point {
Point { x, y }
}
// 定义一个方法,需要实例化对象才可以调用(此处`&self`是Point对象的不可变引用)
fn get_x(&self) -> i32 {
self.x
}
}
fn main() {
let p = Point::new(1, 2);
println!("x is {}", p.get_x());
}
3.8. 泛型(Generic)、特征(Trait)和生命周期(Lifetime)
泛型(Generic):泛型允许我们定义一个可以在多种类型上工作的函数、结构体或枚举,而不需要具体地指定每个类型。
- 使用泛型参数,有一个先决条件,必需在使用前对其进行声明
- 如:
fn largest<T>(list: &[T]) -> T { xxx }- 首先
largest<T>对泛型参数T进行了声明,然后才在函数参数中进行使用该泛型参数list: &[T]
- 首先
- 泛型参数的命名:通常使用单个字母,如
T、U、V等(可使用任意字母,通常使用简短的字母)
- 如:
- 结构体中使用泛型
struct Point<T> { x: T, y: T },其中T是泛型参数,x和y的类型都是T
- 枚举中使用泛型
enum Option<T> { Some(T), None },其中T是泛型参数,Some成员的数据类型是T
- 方法中使用泛型
impl<T> Point<T> { fn get_x(&self) -> &T { &self.x } },其中T是泛型参数,get_x方法返回的是Point对象的x字段的引用
- const泛型:
Rust1.51版本引入了const泛型,允许我们定义一个泛型参数,该参数的值在编译时是已知的。- 此处暂时留个印象,后续按需再深入了解
泛型的性能说明:
- 在Rust中泛型是零成本的抽象,意味着你在使用泛型时,完全不用担心性能上的问题。
- 代价(tradeoff)是损失了 编译速度 和 增大了最终生成文件的大小
- Rust在
编译期会为泛型对应的多个类型,生成各自的代码,因此损失了编译速度和增大了最终生成文件的大小。 - 即:Rust 通过在编译时进行泛型代码的
单态化(monomorphization)来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。
特征(Trait):特征类似于其他语言中的接口(interface或抽象类),用于定义共享的行为。
- 特征定义了一组可以被共享的行为,只要实现了特征,就能使用这组行为
- 定义特征:使用
trait关键字- 如:
trait Summary { fn summarize(&self) -> String; } - 还可以添加public关键字,表示该特征是公开的,可以被其他模块使用:
pub trait Summary { fn summarize(&self) -> String; }
- 如:
- 实现特征中的方法:使用
impl关键字- 实现特征的语法与为结构体、枚举实现方法很像:
impl Summary for Post,读作“为Post类型实现Summary特征”,然后在impl的花括号中实现该特征的具体方法。 - 如:
impl Summary for Tweet { fn summarize(&self) -> String { format!("{}: {}", self.username, self.content) } }
- 实现特征的语法与为结构体、枚举实现方法很像:
生命周期(Lifetime):生命周期用于指定引用的有效期,确保引用在有效期内不会悬垂(dangling)。
生命周期标注语法:以 ' 开头,名称往往是一个单独的小写字母,大多数人都用 'a 来作为生命周期的名称。
- 为什么需要生命周期标注:因为Rust编译器需要知道引用的寿命,以便在编译时检查引用的有效性。
- 在存在多个引用时,编译器有时会无法自动推导生命周期,此时就需要我们手动去标注,通过为参数标注合适的生命周期来帮助编译器进行借用检查的分析。
- 示例:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {},其中'a是一个生命周期参数,表示x和y的生命周期都至少要和'a一样长。 - 不使用则会报错的示例:
fn longest(x: &str, y: &str) -> &str {},因为编译器无法确定x和y的生命周期,可能会出现悬垂引用。
- 一个生命周期标注,它自身并不具有什么意义,因为生命周期的作用就是告诉编译器多个引用之间的关系。
- 例如,有一个函数,它的第一个参数 first 是一个指向 i32 类型的引用,具有生命周期
'a,该函数还有另一个参数 second,它也是指向 i32 类型的引用,并且同样具有生命周期'a fn useless<'a>(first: &'a i32, second: &'a i32) {}
- 例如,有一个函数,它的第一个参数 first 是一个指向 i32 类型的引用,具有生命周期
- 如果是引用类型的参数,那么生命周期会位于引用符号
&之后,并用一个空格来将生命周期和引用参数分隔开&i32一个引用&'a i32具有显式生命周期的引用&'a mut i32具有显式生命周期的可变引用
- 函数签名中的生命周期标注
- 在通过函数签名指定生命周期参数时,我们并没有改变传入引用或者返回引用的真实生命周期,而是告诉编译器当不满足此约束条件时,就拒绝编译通过。
- 还有结构体、方法等生命周期的使用场景,后面具体用到时,再参考:生命周期
- 生命周期消除规则、编译器标注规则;生命周期省略规则
- 静态生命周期
'static:拥有该生命周期的引用可以和整个程序活得一样久。字符串字面量的生命周期都是'static,因为它们在编译时就已经被写入到程序的二进制文件中。
3.9. 集合(Collection)
Rust提供了多种内置的集合类型,如Vec、HashMap、String等。String也是一个集合类型,它是一个可变的、动态分配的、UTF-8编码的字符串。
Vec:动态数组,可以动态地增加和减少元素- 创建
- 使用
new关联函数创建:let v: Vec<i32> = Vec::new(); - 使用
with_capacity创建:如果预先知道要存储的元素个数,可以使用Vec::with_capacity(capacity)创建动态数组- 这样可以避免因为插入大量新数据导致频繁的内存分配和拷贝,提升性能
with_capacity示例:let v = Vec::with_capacity(10);,此处创建了一个容量为10的动态数组
- 使用宏
vec!创建数组:let v = vec![1, 2, 3];
- 使用
- 操作
- 添加元素:
v.push(4); - 读取元素:通过下标或者
get函数,let third = &v[2];,let third = v.get(2);。其中get函数返回一个Option类型,需要match匹配来解构 - 迭代:
for i in &v { println!("{}", i); };也可以迭代时修改元素:for i in &mut v { *i += 50; }
- 添加元素:
- Vector常用方法
len:返回Vector的长度is_empty:判断Vector是否为空push:向Vector中添加元素pop:从Vector中移除并返回最后一个元素remove:从Vector中移除指定位置的元素insert:在指定位置插入元素- 还可以像数组切片的方式获取动态数组的部分元素:
let v = vec![11, 22, 33, 44, 55];,assert_eq!(&v[1..=3], &[22, 33, 44]) - 排序:
v.sort()、v.sort_unstable()、v.sort_by_key(|k| k.to_string()) - …
- 创建
HashMap:键值对集合,可以快速地通过键来查找值- 使用
HashMap时,需要从标准库中引入到当前的作用域中来:use std::collections::HashMap;(String和Vec则不用,默认在prelude中) - 创建:
- 使用
new关联函数创建:let mut scores = HashMap::new(); - 使用
迭代器和collect方法创建:teams_list是个Vec动态数组,let teams_map: HashMap<_,_> = teams_list.into_iter().collect();into_iter方法将列表转为迭代器,接着通过collect进行收集collect方法在内部实际上支持生成多种类型的目标集合,因此需要通过类型标注HashMap<_,_>来告诉编译器:请帮我们收集为HashMap集合类型,具体的KV类型
- 使用
- 操作
- 插入或更新键值对:
scores.insert(String::from("Blue"), 10); - 查询新插入的值:
scores.get("Blue");
- 插入或更新键值对:
- 使用
3.10. 返回值和错误处理
panic!:当程序遇到无法处理的错误时,可以使用panic!宏来使程序崩溃并输出错误信息- 比如:
panic!("crash and burn");
- 比如:
- 错误返回值:
Result<T, E>枚举(T/E都是泛型参数)- 其定义为:
enum Result<T, E> { Ok(T), Err(E), },其中T是成功时返回的类型,E是错误时返回的类型 - 用法:
let f = File::open("hello.txt");,f的类型是Result<T, E>,其中T是std::fs::File,E是std::io::Error,表示文件打开失败时的错误类型。而后可以使用match匹配来处理错误,或者使用unwrap方法来直接返回错误
- 其定义为:
- 传播错误返回值
- 可从函数中返回错误,交给调用链的上游,比如:
fn read_username_from_file() -> Result<String, io::Error> { ... } - 通过
?操作符,将错误传播给调用者,?操作符会返回Result类型,如果Ok则返回Ok中的值,如果Err则返回Err中的值- 比如:
let f = File::open("hello.txt")?;,如果文件打开失败,则返回Err,否则返回Ok中的文件句柄 - 和
match匹配相比,?操作符可以简化代码,避免重复的错误处理逻辑。相对于Go中的if err != nil,Rust的?操作符更加简洁和优雅。
- 比如:
try!宏:在?之前,Rust有一个try!宏,用于将错误传播给调用者,但是try!宏已经被弃用,建议使用?操作符。
- 可从函数中返回错误,交给调用链的上游,比如:
下面是通过match和?操作符两种方式来处理错误的示例,都可以传递错误给调用者:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// match方式
fn read_username_from_file() -> Result<String, io::Error> {
let f = File::open("hello.txt");
// 判断open函数的返回值,并向调用者返回错误
let mut f = match f {
Ok(file) => file,
Err(e) => return Err(e),
};
...
// 保证返回和返回值类型一致
return Ok("success");
}
// ?方式
fn read_username_from_file() -> Result<String, io::Error> {
// ?操作符会返回Result类型,如果Ok则返回Ok中的值,如果Err则返回Err中的值
// 和上面的match方式类似,但是更简洁
let mut f = File::open("hello.txt")?;
...
return Ok("success");
}
3.11. 包和模块
Rust提供的包管理相关机制:
包(Crate):一个包是一个独立的可编译单元,可以包含多个库或可执行文件
- 编译后会生成一个
可执行文件或者一个库 - 同一个包中不能有同名的类型,但是在不同包中就可以
项目(Package):一个项目是一个工作空间,可以包含多个包
- 包的名称被crate占用,此处Package就翻译为项目了
- 由于 Package 就是一个项目,因此它包含有独立的
Cargo.toml文件,以及因为功能性被组织在一起的一个或多个包。 - 一个 Package 只能包含一个库(library)类型的包(crate),但是可以包含多个二进制可执行类型的包。
- 二进制Package:前面示例创建的都是默认的二进制Package
- 库Package:
cargo new my-lib --lib,创建一个库Package,库Package会生成一个src/lib.rs文件,用于定义库的公共API。cargo run会报错,因为库类型的 Package 不能直接运行,只能作为三方库被其它项目引用。
典型的Package结构:(这种目录结构基本上是 Rust 的标准目录结构,在 GitHub 的大多数项目上,你都将看到它的身影。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
.
├── Cargo.toml
├── Cargo.lock
├── src
│ ├── main.rs # 默认二进制包:src/main.rs,编译后生成的可执行文件与 Package 同名
│ ├── lib.rs # 唯一库包:src/lib.rs
│ └── bin # 其余二进制包,会分别生成一个文件同名的可执行文件
│ └── main1.rs
│ └── main2.rs
├── tests # 集成测试文件
│ └── some_integration_tests.rs
├── benches # 基准性能测试 benchmark 文件
│ └── simple_bench.rs
└── examples # 项目示例
└── simple_example.rs
模块(Module):一个模块是一个逻辑上的代码组织单元,可以包含多个函数、结构体、枚举等
- 使用
模块可以将包中的代码按照功能性进行重组,最终实现更好的可读性及易用性。还能灵活地控制代码的可见性,进一步强化Rust的安全性。 - 使用
mod关键字来创建新模块,后面紧跟着模块名称- 模块可以嵌套;
- 可以定义各种 Rust 类型,例如函数、结构体、枚举、特征等
- 所有模块均定义在同一个文件中
- 模块可见性
- Rust出于安全的考虑,默认情况下,所有的类型都是
私有化的,包括函数、方法、结构体、枚举、常量,就连模块本身也是私有化的。- 父模块完全无法访问子模块中的私有项,但是子模块却可以访问父模块的私有项
- 模块可见性不代表模块内部项的可见性,模块的可见性仅仅是允许其它模块去引用它,但是想要引用它内部的项,还得继续将对应的项标记为
pub
pub关键字,类似于其他语言的public和Go中的首字母大写
- Rust出于安全的考虑,默认情况下,所有的类型都是
模块定义和使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
mod my_module {
// 模块中的函数
pub fn my_function() {
println!("Hello from my_module!");
}
// 模块中的结构体
pub struct MyStruct {
// 结构体字段
pub field: i32,
}
// 模块中的枚举
pub enum MyEnum {
// 枚举变体
Variant,
}
// 模块中的特征
pub trait MyTrait {
// 特征方法
fn my_method(&self);
}
}
// 模块的使用示例
fn main() {
// 使用模块中的函数
my_module::my_function();
// 使用模块中的结构体
let my_struct = my_module::MyStruct { field: 42 };
println!("Field value: {}", my_struct.field);
// 使用模块中的枚举
let my_enum = my_module::MyEnum::Variant;
}
4. Rust规范
4.1. 注释和文档
注释类型:
- 单行注释:
// - 多行注释/块注释:
/* ... */ - 文档注释:
///用于生成文档行注释,/** ... */文档块注释- 通过
cargo doc,可直接生成 HTML 文件,放入target/doc目录下
- 包和模块级别的注释(其实也算文档注释)
- 除了函数、结构体等 Rust 项的注释,还可以给包和模块添加注释,这些注释要添加到包、模块的最上方
- 包级别的注释也分为两种:行注释
//!和块注释/*! ... */
文档测试:
- Rust 允许我们在文档注释中写单元测试用例,这些测试用例会在我们运行
cargo test时自动运行
比如,下面的注释不仅仅是文档,还可以作为单元测试的用例运行,可使用cargo test运行测试。
1
2
3
4
5
6
7
8
9
10
11
12
13
/// `add_one` 将指定值加1
///
/// # Examples11
///
/// ```
/// let arg = 5;
/// let answer = world_hello::compute::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}
4.2. 代码规范
上面链接里也贴了一些社区公开的Rust编码规范:
- 官方:Rust API Guidelines
- 官方:Rust Style Guide
- 还有PingCAP、Google Fuchsia 操作系统、RustAnalyzer编码风格等
此处贴几个常用的:
- 空格使用
- 在冒号之后添加空格,在冒号之前不要加空格
fn lorem<T: Eq>(t: T)
- 在范围(range)操作符(..和..=)前后不要使用空格
let ipsum = 0..=10;、let lorem = 0..10;
- 在+或=操作符前后要加空格
let lorem: Dolor = Loremlet answer = 1 + 2;
- 参考:P.FMT.09 不同的场景,使用不同的空格风格
- 在冒号之后添加空格,在冒号之前不要加空格
1
2
3
4
5
6
fn lorem<T: Eq>(t: T) {
let lorem: Dolor = Lorem {
ipsum: dolor,
sit: amet,
};
}
- 括号:
- 左花括号与其定义保持同一行,包括 控制结构(if / match 等)、函数、结构体、枚举等
- 但是如果携带
where语句,则要求换行,并且where 子句和 where 关键字不在同一行 - 参考:P.FMT.04 左花括号位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
fn main() {
if lorem {
println!("ipsum!");
} else {
println!("dolor!");
}
}
// 左花括号和 函数语言项定义在同一行
fn lorem() {
// body
}
fn lorem<T>(ipsum: T)
where // `where` 子句和 `where` 关键字不在同一行
T: Add + Sub + Mul + Div,
{ // 当有 `where` 子句的时候,花括号换行
// body
}
// 结构体
struct Lorem {
ipsum: bool,
}
- 函数设计
- 函数返回值不要使用
return- Rust中函数块会自动返回最后一个表达式的值,不需要显式地指定
return - 只有在函数过程中需要提前返回的时候再加
return
- Rust中函数块会自动返回最后一个表达式的值,不需要显式地指定
- 函数的参数最长不宜超过五个
- 参考:3.9 函数设计
- 函数返回值不要使用
1
2
3
4
5
6
fn foo(x: usize) -> usize {
if x < 42{
return x;
}
x + 1 // 符合
}
- 布尔值,使用
not()方法代替逻辑取反运算符!- 相对较长的逻辑表达式来说很不显眼,
.not()更容易吸引注意力 if cache.contains(&key).not() { xxx }
- 相对较长的逻辑表达式来说很不显眼,
- 结构体:Rust的惯用方式是构建即初始化,避免先
::new()再set,而是直接在初始化时赋值 - 表达式
- 自增或自减运算使用
+=或-=++i、i++、i--等不是合法的Rust表达式,--i虽然是合法的Rust表达式,但是表达对i取反两次,而不是自减语义
- 自增或自减运算使用
- 控制流程
- 当需要通过多个
if判断来比较大小来区分不同情况时,优先使用match和cmp来代替if表达式 if条件表达式分支中如果包含了else if分支,也应该包含else分支
- 当需要通过多个
- 集合容器
- 创建
HashMap、VecDeque时,可以预先分配大约足够的容量来避免后续操作中产生多次分配let mut map = HashMap::with_capacity(3);vslet mut map = HashMap::new();
- 创建
- 错误处理
- 在确定
Option<T>和Result<T, E>类型的值不可能或不应该是None或Err时,请用expect代替unwrap()- 虽然直接
unwrap()也是可以的,但使用expect会有更加明确的语义 - 并且,在指定
expect输出消息的时候,请使用肯定的描述,而非否定,用于提升可读性 expect 的语义:我不打算处理 None 或 Err 这种可能性,因为我知道这种可能性永远不会发生,或者,它不应该发生。但是 类型系统并不知道它永远不会发生。所以,我需要像类型系统保证,如果它确实发生了,它可以认为是一种错误,并且程序应该崩溃,并带着可以用于跟踪和修复该错误的栈跟踪信息。
let config = Config::read("some_config.toml").expect("Provide the correct configuration file");- vs
let config = Config::read("some_config.toml").expect("No configuration file provided");
- 虽然直接
- 不要滥用
expect,请考虑用unwrap_or_系列方法代替
- 在确定
- 模块
- 将模块的测试移动到单独的文件,有助于增加编译速度。如
src/codes.rs和src/codes_test.rs - 导入模块不要随便使用 通配符
*
- 将模块的测试移动到单独的文件,有助于增加编译速度。如
5. 小结
Rust学习系列开篇,并学习梳理了Rust的基础语法,进行基本的demo练习操作。相关特性及使用和实现细节,在后续的学习实践中进一步深入理解。
6. 参考
1、Rust开源教程:Rust语言圣经(Rust Course)
2、《The Rust Programming Language》
8、GPT