AI Agent学习实践笔记(一) -- Agents介绍
HuggingFace AI Agents Course学习笔记,unit1 -- Agents介绍
HuggingFace AI Agents Course学习笔记(AI智能体)
1. 背景
当前AI发展日新月异,功能越来越强大。日常只是使用基本问答比较多,之前(ollama搭建本地个人知识库)也在本地用ollama部署千问简单体验了一下。近几年AI大模型应用从ChatBot -> Copilot -> Agent,对于软件行业从业者来说相关辅助更为明显,比如火热的cursor编辑器、Devin软件工程师智能体。
技术潮流还是得跟上,正好了解到近期HuggingFace推出了一个免费的AI Agents课程:AI Agents Course,先学习该课程并进行实践。
- 课程介绍:AI Agents Course
- GitHub:huggingface/agents-course
下面是相应课程单元链接:
You can access the course here 👉 https://hf.co/learn/agents-course
| Unit | Topic | Description |
|---|---|---|
| 0 | Welcome to the Course | Welcome, guidelines, necessary tools, and course overview. |
| 1 | Introduction to Agents | Definition of agents, LLMs, model family tree, and special tokens. |
| 2 | 2_frameworks | Overview of smolagents, LangChain, LangGraph, and LlamaIndex. |
| 3 | 3_use_cases | SQL, code, retrieval, and on-device agents using various frameworks. |
| 4 | 4_final_assignment_with_benchmark | Automated evaluation of agents and leaderboard with student results. |
2. 单元1:Agents介绍
2.1. 什么是Agent
Agent定义:是一个利用AI模型与其环境进行交互的系统,以实现用户定义的目标。它结合了推理(reason),计划(plan)和执行操作(通常是通过外部工具)来完成任务。
举例:Agent是一个生活助手,告诉他我想要一杯咖啡。而后助手理解了自然语言,推理思考做一杯咖啡需要的步骤,并按步骤行动,过程中他可以使用其了解的工具。
图示:
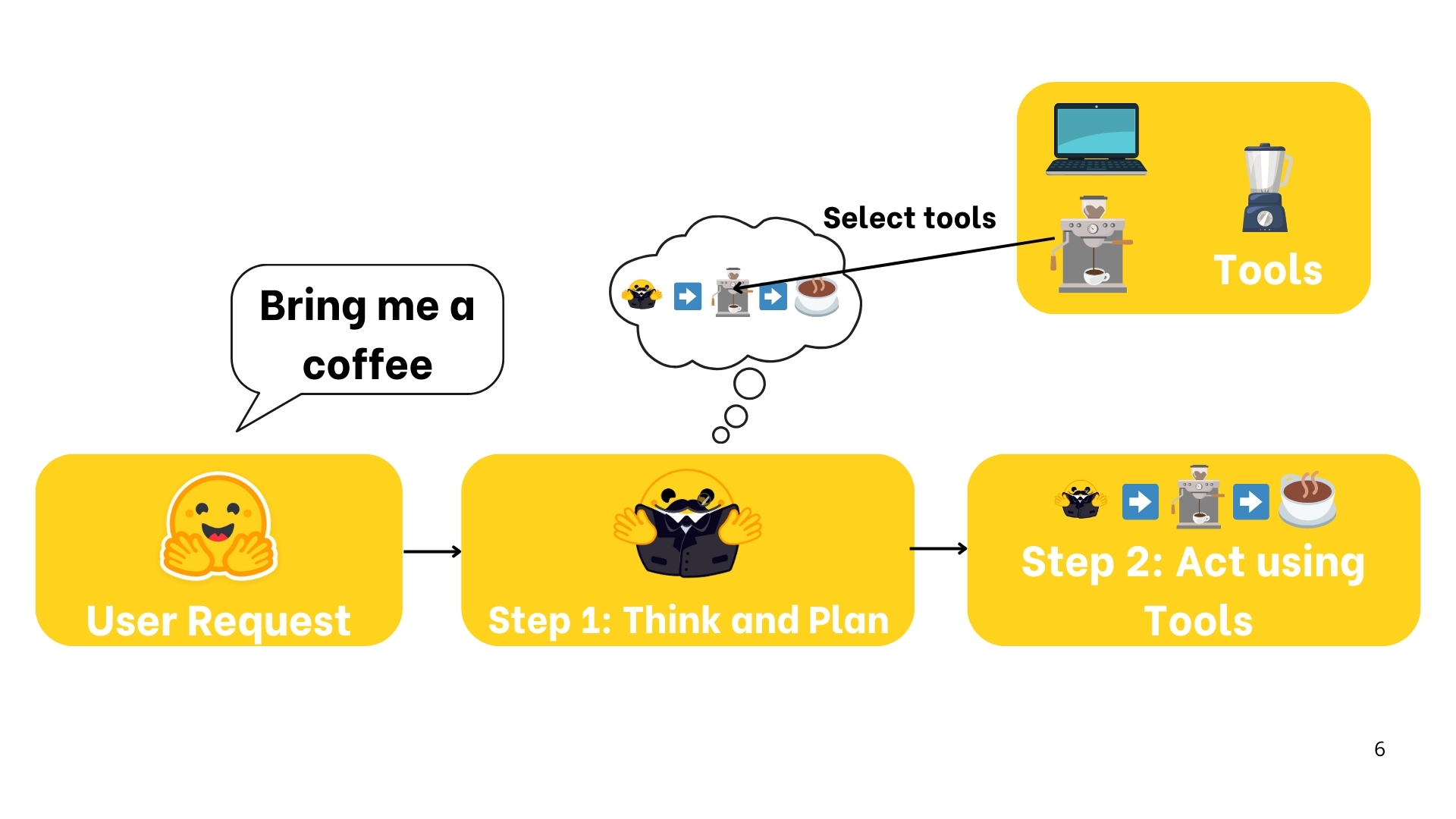
把Agent想象成2个部分:
- 大脑(AI模型):处理推理和计划
- Agent中使用的 最通用 的AI模型是
LLM(Large Language Model,大语言模型),以文本作为输入,并以文本作为输出。- 也有可能使用其他输入的模型作为核心模型,比如视觉语言模型
Vision Language Model(VLM),可以理解图片作为输入
- 也有可能使用其他输入的模型作为核心模型,比如视觉语言模型
- 比如来自 OpenAI的
GPT4、Meta的LLama、Google的Gemini等等
- Agent中使用的 最通用 的AI模型是
- 身体(能力和工具):代表Agent能做的一切行动,可采取的行动依赖于Agent装配了什么工具
2.2. 什么是LLM
LLM(Large Language Model,大语言模型) 是一种人工智能模型,擅长理解和生成人类语言。它们接受了大量文本数据的训练,使它们能够学习语言的模式、结构甚至细微差别。这些模型通常由数百万个参数组成。
当前大部分LLM都是建立在Transformer架构之上的,这是一种基于 “注意力”(Attention) 算法的深度学习架构,自2018年Google发布BERT以来,该架构引起了人们的极大兴趣。
Transformer架构是一种基于自注意力机制(Self-Attention)的深度学习模型,广泛应用于自然语言处理(NLP)任务,如机器翻译、文本生成、文本分类等。它由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中首次提出,并迅速成为 NLP 领域的核心架构。
BERT是基于 Transformer 编码器的一种预训练语言模型,通过双向上下文建模和创新的训练任务(如 MLM 和 NSP),在 NLP 领域取得了巨大成功。
它不仅继承了 Transformer 的强大能力,还通过预训练-微调范式推动了 NLP 技术的发展。BERT的提出标志着 NLP 进入了预训练语言模型的新时代,后续的许多模型(如 GPT、T5 等)都受到了它的启发。
Transformer 架构有3种类型:
- 编码器(Encoder)
- 将文本转化为密集表示,用于文本分类、语义搜索等,比如Google的
BERT
- 将文本转化为密集表示,用于文本分类、语义搜索等,比如Google的
- 解码器(Decoder)
- 逐一生成新标记以完成序列,用于文本生成、聊天机器人、代码生成等,比如Meta的
Llama
- 逐一生成新标记以完成序列,用于文本生成、聊天机器人、代码生成等,比如Meta的
- 序列到序列(Seq2Seq )
- 结合两者,用于翻译、总结、释义等,比如 T5(Google)、BART(Meta)
常见模型:
| 模型 | 公司 |
|---|---|
| Deepseek-R1 | DeepSeek |
| GPT4 | OpenAI |
| Llama 3 | Meta (Facebook AI Research) |
| SmolLM2 | Hugging Face |
| Gemma | |
| Mistral | Mistral |
2.2.1. LLM 的工作原理
大语言模型(LLM)的基本原理简单却极为有效:其目标是在给定前文一系列token(词元)的情况下,预测下一个token。token是大语言模型处理信息的基本单位。可以把 “token” 想象成 “单词”,但出于效率考虑,大语言模型并不使用完整的单词。
每个LLM都有一些特殊的token,LLM使用这些token来标记区分其生成过程中的一些组件,比如用于标记序列/消息/应答的开始和结束,其中最重要的标记是序列结束:End of sequence token (EOS)
预测下一个token:
LLM是自回归的(autoregressive),这意味着一个token的输出作为下一个token的输入,直到预测的下一个token是EOS。
- 输入文本被token化(tokenized)后,模型会计算该序列的一种表征(representation),这种表征涵盖了输入序列中每个token的含义及位置信息。
- 这种表征会输入到模型中,模型随后输出
分数,对其词汇表中每个token作为序列下一个token的可能性进行排序。
解码策略(decode):
基于这些分数,可以有多种解码策略来选择哪些token来完成后续的内容。比如简单地总是选取分数最高的标记;更高级的有束搜索,它会探索多个候选序列,找到总分最高的序列
注意力机制:
Transformer架构中的注意力(Attention)机制至关重要。
在预测下一个单词时,句子中的每个单词重要性并不是相同的,注意力机制能够识别出最相关的单词,从而提高预测的准确性。比如The capital of France is …中,capital和France是最重要的。
几个概念:
上下文长度(context length):指LLM能处理的最大标记数量,也是其注意力的最大跨度提示词(prompt):输入给LLM的序列被称为提示词(prompt),精心设计提示有助于引导LLM生成期望的输出- 考虑到LLM的唯一工作是通过查看每个输入token来预测下一个token,并选择哪个token是 “重要的”,因此输入序列的措辞(即prompt)非常重要
2.2.2. LLM 是如何训练的
LLM在大规模文本数据集上进行训练,在此过程中,它们通过自监督(self-supervised)或掩码语言(masked language)建模目标,来学习预测序列中的下一个单词。
“masked language” 通常指 “掩码语言”,在自然语言处理领域,尤其是在语言模型的训练中,“掩码语言建模(Masked Language Modeling,MLM)” 是一种常用的技术手段。
原理:在训练数据中随机选择一些单词或词元,并将它们替换为特殊的掩码标记(例如 “[MASK]”)。然后,模型的任务是根据上下文来预测这些被掩码的单词或词元是什么。通过这种方式,模型被迫学习文本中的语言模式和语义信息,以便能够准确地预测被掩码的部分。
作用:增强语言理解能力、提高模型泛化能力
通过这种无监督学习(unsupervised learning),模型能够学习语言结构以及文本中的潜在模式,从而使模型能够对未曾见过的数据进行泛化处理。
在完成这一初始预训练(pre-training)后,大语言模型(LLM)可以基于有监督学习目标(supervised learning objective)进行微调(fine-tuned),以执行特定任务。例如,一些模型针对对话结构或工具使用进行训练,而另一些则专注于分类或代码生成。
有监督学习(supervised learning)是指利用标记好的训练数据来训练模型,让模型学习输入特征与输出标签之间的映射关系,从而对未知数据进行预测和分类的机器学习方法。在有监督学习中,训练数据集中的每个样本都由输入特征向量和对应的输出标签组成,模型通过学习这些样本数据,试图找到一种
通用的模式或函数,使得对于新的输入数据,能够准确地预测出相应的输出。
2.2.3. LLM如何使用
有两种主要方式:
- 1、本地运行。需要有足够的硬件支持
- 2、使用云服务或API。比如通过 Hugging Face 的无服务器推理 API,本课程主要采用这种方式
小结:LLM 是 AI智能体(AI Agents)的关键组成部分,为智能体理解和生成人类语言提供基础。它能够解释用户指令、在对话中保持上下文连贯、制定行动规划并决定使用哪些工具,是 AI智能体的核心 “大脑”。
2.3. 消息与特殊标记
本节介绍LLM如何通过聊天模板(chat templates)组织生成的内容。与 ChatGPT 类似,用户通常通过聊天界面与智能体进行交互。因此,我们旨在了解大语言模型是如何管理聊天过程的。
当你与 ChatGPT 或 Hugging Chat 这类系统聊天时,实际上是在交换消息(exchanging messages)。在后台,这些消息会被连接并格式化为模型能够理解的提示(prompt)
如下例可见 从UI上看到的内容 和 喂给模型的提示内容 的差异:

这里就是聊天模板(chat templates)发生作用的地方,它们充当了对话消息(conversational messages )(上图中用户和助手间的轮次)与所选大语言模型特定格式要求(the specific formatting requirements)之间的桥梁。换句话说,聊天模板构建了用户与智能体之间的交流结构,确保每个模型,尽管它们有独特的特殊token,都能收到格式正确的提示(prompt)。
消息:LLM(大语言模型)的底层系统
系统消息(System Messages),也称为系统提示(System Prompts),定义了模型应有的行为方式。它们作为持久的指令(persistent instructions),指导后续的每一次交互。- 在使用智能体时,系统消息还会提供有关
可用工具的信息,向模型说明如何格式化要采取的行动(how to format the actions to take),并包含关于思维过程应如何分段的指导原则。
- 在使用智能体时,系统消息还会提供有关
对话(Conversations),用户消息和助手消息对话由人类(用户)和大语言模型(助手)之间交替的消息组成。聊天模板(chat template)通过保存对话历史记录来帮助维护上下文,使得多轮对话更连贯。
对话信息示例:
1
2
3
4
5
conversation = [
{"role": "user", "content": "I need help with my order"},
{"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
{"role": "user", "content": "It's ORDER-123"},
]
agent总是连接会话中的所有消息,将其作为单独的序列提供给LLM,聊天模板将所有这些消息转换为一个提示词(prompt),代码表现为将python的list内容转换为一个包含所有信息的string。
聊天模板(Chat-Templates):
如上所述,聊天模板对组织 语言模型 和 用户 之间的对话至关重要。
基本模型(base model)与指令模型(instruct model)- 基本模型基于原始文本数据进行训练,以预测下一个标记
- 指令模型是为了遵循指令和参与对话,对于基本模型进行了特别的
微调(fine-tuned) - 为了使一个基本模型表现得像指令模型,就需要将prompt提示转换为模型能理解的统一格式,此处就是
聊天模板要做的事。比如ChatML就是一个这样的模板。 - 需要注意的是:
基本模型可以在不同的”聊天模板”上微调,因此我们在使用一个指令模型时需要确保我们使用了正确的聊天模板。
2.4. 什么是工具(Tools)
AI智能体(AI Agents)的一个关键方面是其采取行动(take actions)的能力,该能力是通过使用工具(Tools)来实现的。
本节将会学习什么是工具,如何有效地设计它们,以及如何通过系统消息将它们集成到你的AI智能体里。使用正确的工具能大大提高智能体的能力。
2.4.1. AI工具
工具(Tools):工具是赋予 LLM 的一个函数,具有明确的目标。
下面是AI智能体中常用的一些工具:
| Tool | Description |
|---|---|
| Web Search | 允许智能体从互联网获取最新信息 |
| Image Generation | 根据文本描述创建图像 |
| Retrieval | 从外部源检索信息 |
| API Interface | 与外部API(如GitHub、YouTube、Spotify等)进行交互 |
上面只是一些示例,还可根据实际需求创建工具。一个好的工具应能补充LLM的能力,弥补其在算术运算、获取实时数据(模型仅基于历史训练数据)等方面的不足。
一个工具应该包含:
- 对功能的文本描述(textual description)
- 可调用对象(A Callable)
- 带类型的参数(Arguments with typings)
- (可选)也可包含带类型的输出(Outputs with typings)
2.4.2. 工具是如何工作的
LLM只能接收和生成文本,本身无法调用工具。我们所说的给智能体提供工具,实际是告诉LLM关于工具的存在,并要求模型在其需要时生成调用工具的文本内容。
LLM会在需要时生成调用工具的代码文本,智能体负责解析该输出的代码,识别并代表LLM调用工具,工具输出再返回给LLM,由LLM生成最终回复给用户。工具调用过程通常对用户不可见。
从用户的角度来看,就好像LLM使用了这个工具,但实际上是应用程序代码 (Agent智能体) 做的。
2.4.3. 如何提供工具给LLM
本质上是使用系统提示(system prompt)为模型提供可用工具的文本描述(textual descriptions)。
系统提示示例:
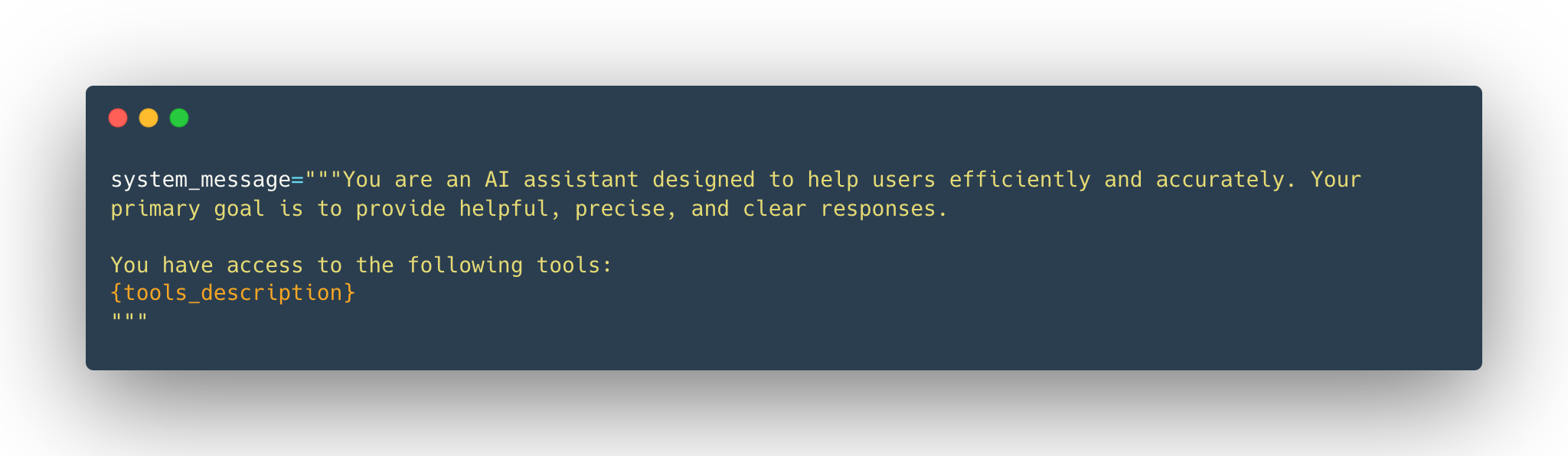
工具必须特别准确和精确(precise and accurate)地说明:
- 工具的功能(What the tool does)
- 期望的具体输入(What exact inputs it expects)
2.5. AI智能体的工作流(AI Agent Workflow)
Agent智能体的工作是一个连续的循环: 思考(Thought) -> 行动(Action) -> 观察 (Observation)。
- 思想(Thought):智能体中的大语言模型(LLM)部分,决定下一步应该做什么行动
- 是AI智能体解决任务时的内部推理和规划过程,它能剖析任务、制定策略,依据当前观察决定后续行动,将复杂问题拆解,回顾过往经验并依新信息调整计划
Re-Act方法:Re-Act 是 “推理(思考)” 与 “行动” 相结合的提示技术(prompting technique),它让LLM在解码下一个token之前附加“Let’s think step by step”。- 相关模型的推理策略:
Deepseek R1、OpenAI o1等模型备受关注,它们经过微调实现“思考后作答”(think before answering)。这些模型通过特殊训练,在<think>与</think>特殊标记间生成思考内容,与Re-Act提示技术不同,是基于大量示例学习的训练方式
- 行动(Action):智能体根据思考结果调用工具,并传递相关参数
- 行动 是AI智能体与
环境(environment)交互的具体步骤。涵盖从网络获取信息到控制物理设备等多种操作,如客服智能体执行的客户数据检索、问题转接等任务 - 分类
- 按智能体类型划分:JSON智能体(以JSON格式指定行动)、代码智能体(生成外部可解释的代码块)、函数调用智能体(JSON智能体的子类,为每次行动生成新消息)
- 按行动目的划分:包括信息收集(如网络搜索、数据库查询)、工具使用(API 调用、计算操作)、环境交互(操控数字界面、控制物理设备)和通信(与用户聊天、与其他智能体协作)
停止和解析方法,是实现行动的关键方法。智能体按既定格式(JSON或代码)生成行动,完成后停止生成额外token,外部解析器读取格式化行动,确定调用的工具和提取参数,以此确保行动输出结构化、可预测,减少错误,便于外部工具处理。- 代码智能体的优势:相比于JSON,代码能表达复杂逻辑,具有更高的灵活性,还具备模块化、可复用、易调试的特点,可直接集成外部库和API
- 行动 是AI智能体与
- 观察(Observation):模型接收工具返回的响应,这一观察结果作为真实世界的反馈,添加到提示中作为额外上下文,用于判断行动是否成功,并为后续推理提供依据。
- 观察是智能体感知自身行动后果的方式,其提供的关键信息为智能体的
思考过程提供支持,并指引未来行动。这些信息源自环境,如 API 数据、错误消息或系统日志等,推动智能体进入下一个思考循环。 - 类型:观察有多种形式,可类比为工具执行行动后的 “日志” 反馈,具体包括系统反馈(如错误消息、成功通知、状态码)、数据变化(如数据库更新、文件系统修改、状态变更)、环境数据(如传感器读数、系统指标、资源使用情况)、响应分析(如 API 响应、查询结果、计算输出)以及基于时间的事件(如到达截止日期、完成预定任务)。
- 观察是智能体感知自身行动后果的方式,其提供的关键信息为智能体的
2.6. 完课证书
通过测试可以领取一个完课证明:

3. trae试用
近期字节发布了trae(the real ai engine ?)AI编程工具,类似cursor,试用一下。
让其生成一个测试项目,验证gcc的address sanitizer内存检查功能:
自己的本地环境由于之前MacOS的版本和开发套件有点问题,安装mysql依赖有问题,让trae调整为本地文件操作:
自动修改了工程内容和编译错误,运行结果:
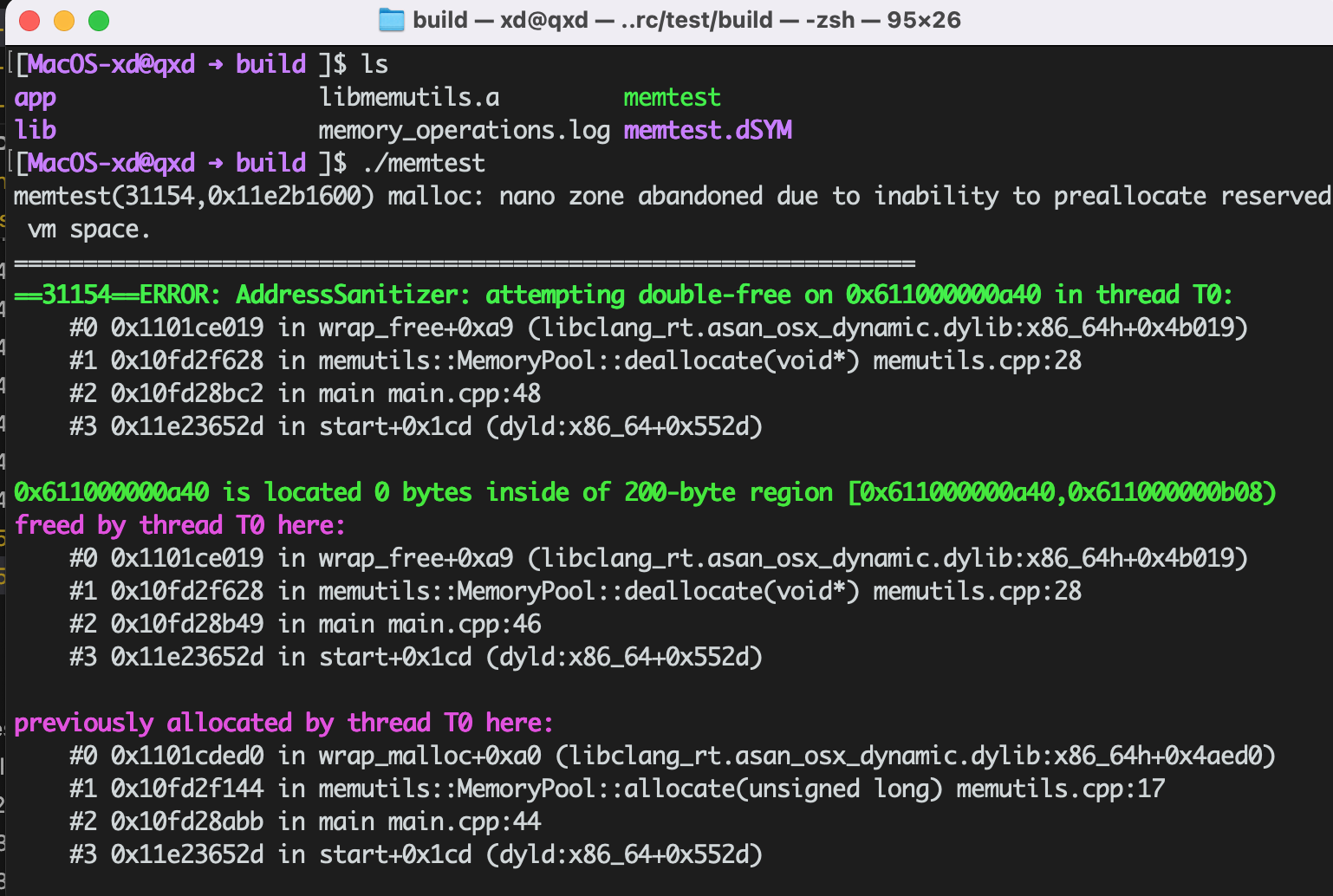
试用体验还可以,通过自然语言就完成了基本任务,是个不错的助手。
4. 小结
通过HuggingFace的AI Agents课程,简单了解LLM和智能体的基本流程,对于平时的大模型使用和提示词设计挺有帮助。为后续实现自己的智能体立下个初步基础。