ioserver服务实验(一) -- 借助trae搭建项目
借助trae快速搭建项目,实现C++读写服务demo,借此作为场景进行实验。
借助 trae 快速搭建项目,实现C++读写服务demo,借此作为场景进行实验。
1. 背景
基于C++实现的读写服务demo,借此作为场景温习并深入学习io多路复用、性能调试、MySQL/Redis等开源组件。
本篇借助 trae 的Builder模式快速搭建项目。cursor 之前只是简单试用了一下,没开Pro后面就一直没用起来,看看之后的体验效果对比再做选择。
trae当前默认使用模型:Claude-3.5-Sonnet
2. demo项目思路
demo实验准备涉及的一些技术点,思路:
1、阶段一:
- io复用select/poll/epoll
- 线程池、内存池、
- 缓存Redis、MySQL
- 性能定位和调试:火焰图、上下文切换、cpu亲和性设置、tcp参数调优
- 容器化,dockerfile
- 监测:Prometheus、Grafana,各项指标设计采集
- 网络,带宽,tcp丢包、重传、rt等指标
- 内存使用
- 磁盘io使用率,带宽
- 服务端的连接数
- 考虑如何结合
ebpf进行监测,如何设计指标,可以用USDT手动往程序里埋一些
2、阶段二:改造分布式服务
- 服务端的负载均衡,reuseport、api网关
- redis集群
- grpc框架
- 服务发现etcd/consoul
- 对称式架构,raft选举
3、阶段三:结合场景实践一些算法和机制方案等
- 一致性hash、分布式锁
- 布隆过滤器,过滤异常请求
- 备份、容灾
3. trae生成项目
一开始没有特别有条理的要求,只有大概的一些发散思路(上小节实际是项目生成后做了梳理),让AI去发挥吧。
3.1. 初次生成
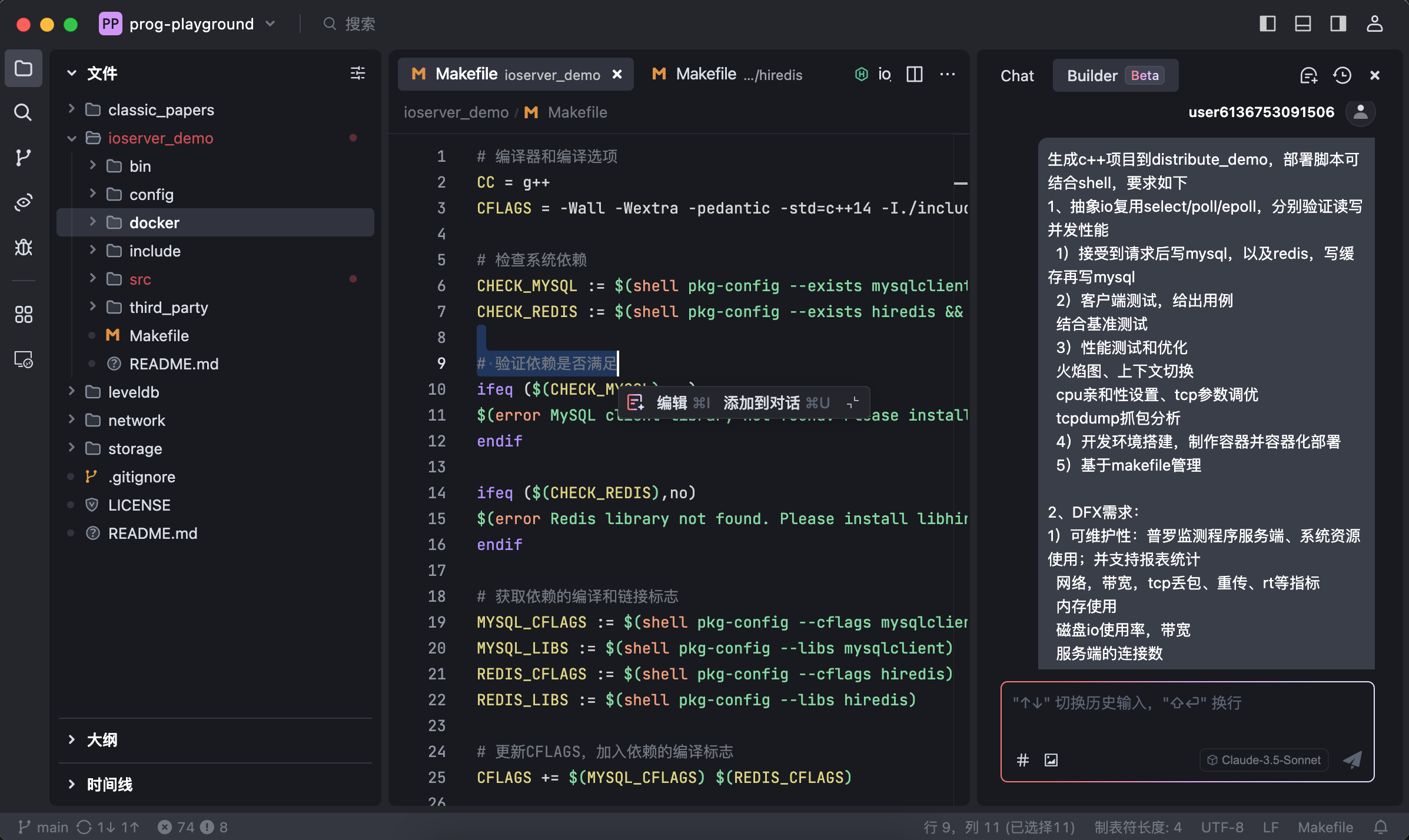
选择Builder模式,如下思路:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
生成c++项目,部署脚本可结合shell,要求如下
1、抽象io复用select/poll/epoll,分别验证读写并发性能
1)接受到请求后写mysql,以及redis,写缓存再写mysql
2)客户端测试,给出用例
结合基准测试
3)性能测试和优化
火焰图、上下文切换
cpu亲和性设置、tcp参数调优
tcpdump抓包分析
4)开发环境搭建,制作容器并容器化部署
5)基于makefile管理
2、DFX需求:
1)可维护性:普罗监测程序服务端、系统资源使用;并支持报表统计
网络,带宽,tcp丢包、重传、rt等指标
内存使用
磁盘io使用率,带宽
服务端的连接数
2)如何结合ebpf进行监测,如何设计指标
3、分阶段需求:
1、阶段一:单机服务,mysql和redis均是单机
2、阶段二:分布式服务
redis集群
部署多个分布式服务,增加api网关,reuseport、nginx
服务发现,etcd consoul
3、对称式集群架构,raft选举
trae builder模式生成项目:
3.2. 过程调整
1、有些内容由于没有给出提示词做限定,比如都是终端打印、逻辑都在main里等,依次进行调整:
- 1)开发基本的工具类,用于日志记录,优化项目里的日志记录
- 可使用开源的 spdlog header-only C++日志库
- 2)main函数优化一下,逻辑分离到单独线程,支持优雅退出
- 3)连接任务处理调整为线程池
- 4)服务端参数调整为json配置文件,并支持动态加载
- 5)段错误等原因导致core时,日志里记录退出堆栈
- 6)makefile里基于c+14编译
- 7)提供MySQL初始化脚本,init.sql
2、项目里用到的mysql和redis依赖,自动生成的无法使用。手动调整:
1
2
3
安装 yum install mysql-devel
下载hiredis(https://github.com/redis/hiredis),手动编译并安装make install
调整pkg-config对应路径,过程中梳理查看ldd脚本流程
3、编译问题,复制编译报错,让IDE(下面或称AI)自己去调整
自己在家用的是Mac,IDE/浏览器等都在这台,但Mac的环境开发包有点问题,是scp到一台Linux PC机进行编译的。要不然trae应该能自己进行编译过程和自行修改代码,不用这么拷来拷去了。
4、AI提供学习思路
项目里有mysql、redis,还要编译及运行server和client,环境做隔离,AI建议Docker Compose进行组织,之前没用过只是简单用docker,学习一下。
3.3. 代码简要说明
项目代码在:ioserver_demo
项目虽小,但包含的小模块也不少:线程池、io多路复用包装、json解析、spdlog日志库,集成MySQL、Redis客户端api,配置文件解析和动态加载、优雅关闭、docker构建等等。
其中的一些实现可作为学习参考。
3.3.1. 线程池
可以学习其中的lambda和future、move等用法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
class ThreadPool {
public:
// 构造函数,创建指定数量的工作线程
explicit ThreadPool(size_t numThreads);
// 析构函数,确保所有任务完成并停止所有线程
~ThreadPool();
// 禁用拷贝构造和赋值操作
ThreadPool(const ThreadPool&) = delete;
ThreadPool& operator=(const ThreadPool&) = delete;
// 调整线程池大小
void resize(size_t numThreads);
// 提交任务到线程池
// 返回一个future对象,可以用来获取任务的执行结果
template<class F, class... Args>
auto enqueue(F&& f, Args&&... args)
-> std::future<typename std::result_of<F(Args...)>::type>;
// 停止线程池
void stop();
private:
// 工作线程向量
std::vector<std::thread> workers;
// 任务队列
std::queue<std::function<void()>> tasks;
// 同步相关成员
std::mutex queue_mutex;
std::condition_variable condition;
bool stop_;
};
3.4. io多路复用说明
抽象了select、poll、epoll多路复用。
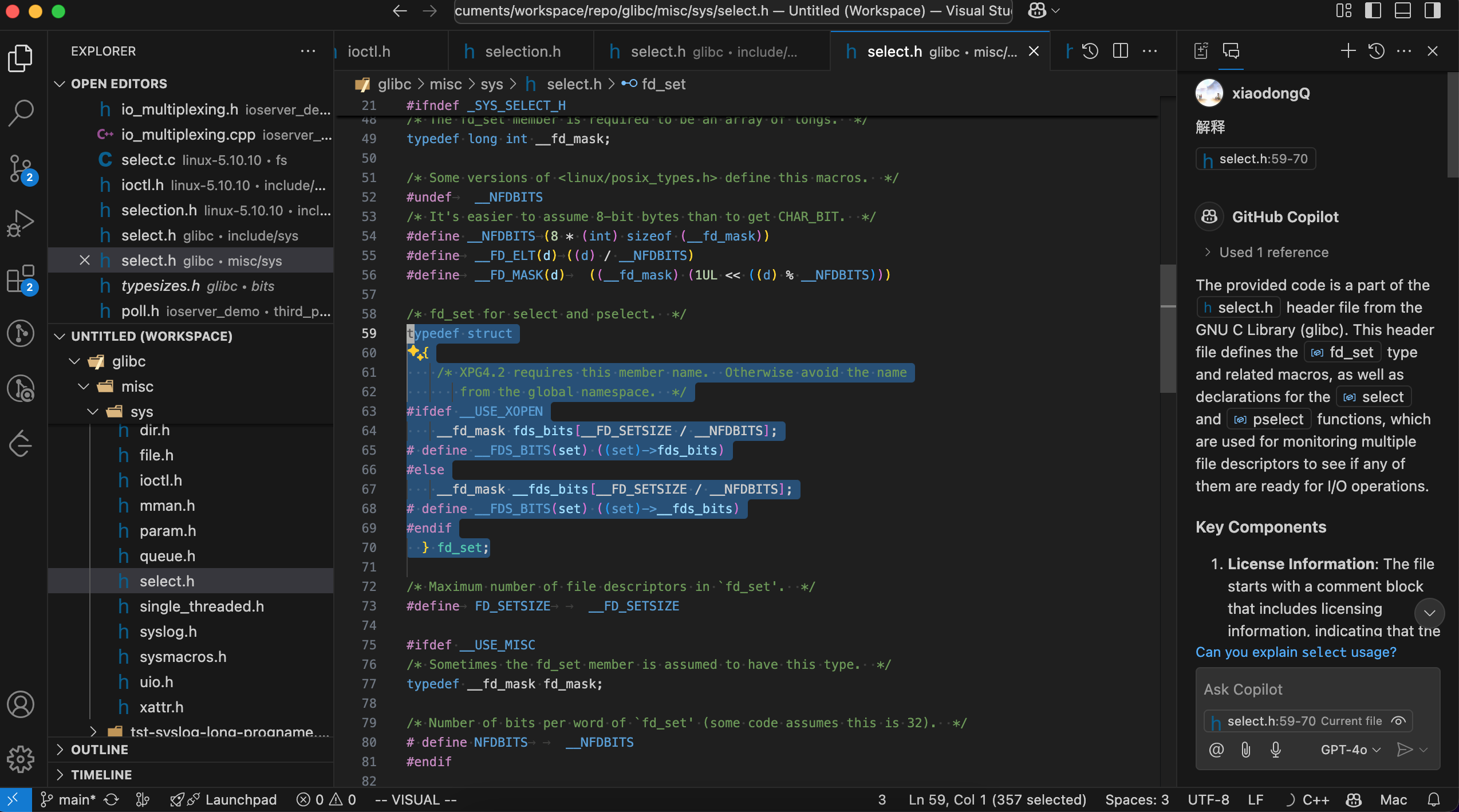
其中sys/select.h、sys/poll.h、sys/epoll.h等文件,位于glibc中(而不是linux内核),可以到/usr/include下去找对应文件内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
// IO多路复用接口抽象类
class IOMultiplexing {
public:
virtual ~IOMultiplexing() = default;
// 添加监听事件
virtual bool addEvent(int fd, EventType type) = 0;
// 移除监听事件
virtual bool removeEvent(int fd, EventType type) = 0;
// 修改监听事件
virtual bool modifyEvent(int fd, EventType type) = 0;
// 等待事件发生
virtual int wait(std::vector<Event>& events, int timeout = -1) = 0;
};
// Select实现
class SelectIO : public IOMultiplexing {
private:
// 要监听的fd集合,按事件类型分: 读、写、错误
// fd_set 是一个描述符位图,glibc中定义最大长度为 1024,所以select能处理的数量受限于1024
// glibc/misc/sys/select.h
// #define FD_SETSIZE __FD_SETSIZE
// #define __FD_SETSIZE 1024
fd_set readfds_, writefds_, errorfds_;
int maxfd_;
public:
// 构造时通过 `FD_ZERO(&readfds_)` 方式,将上述fd_set初始化为空
SelectIO();
~SelectIO() override;
// `FD_SET(fd, &readfds_)` 方式添加要关注的fd到对应的fd_set中,并更新最大的fd:maxfd_
bool addEvent(int fd, EventType type) override;
// 使用 `FD_CLR(fd, &readfds_)` 方式,从对应的fd_set中移除fd
bool removeEvent(int fd, EventType type) override;
// 移除再添加到新fd_set,相当于修改
bool modifyEvent(int fd, EventType type) override;
/*
使用 `select(maxfd_+1, &readfds_, &writefds_, &errorfds_, timeout)` 进行阻塞等待,直到有事件发生(或超时)
不需要关注某事件类型则可传NULL,如 select(maxfd_+1, &readfds_, NULL, NULL, timeout)
且每次调用 select 时,都要将文件描述符集合从用户空间复制到内核空间
且内核要遍历所有fd,性能较差
select返回后,需要遍历fd:[0, maxfd_],通过 `FD_ISSET(fd, &readfds_)` 方式检查是否触发了对应事件,比如:
for (int fd = 0; fd < maxfd_ + 1; ++fd) {
if (FD_ISSET(fd, &rfds)){xxx}
else if (FD_ISSET(fd, &wfds)){xxx}
xxx
}
*/
int wait(std::vector<Event>& events, int timeout = -1) override;
};
// Poll实现
class PollIO : public IOMultiplexing {
private:
// poll 使用 struct pollfd 数组来管理文件描述符,没有固定的文件描述符数量限制
// 或者该形式:struct pollfd fds[MAXNUMFDS],MAXNUMFDS自定义
std::vector<pollfd> pollfds_;
public:
/*
创建 struct pollfd,如`pollfd pfd;`;并注册感兴趣事件,如`pfd.events |= POLLIN;`;然后添加到pollfds_数组中
对应的定义在 glibc/io/sys/poll.h 中:
struct pollfd
{
int fd; // poll fd
short int events; // 关注的事件
short int revents; // 实际发生的事件
};
*/
bool addEvent(int fd, EventType type) override;
// 从pollfds_数组中移除
bool removeEvent(int fd, EventType type) override;
// 从pollfds_数组中移除再添加,相当于修改
bool modifyEvent(int fd, EventType type) override;
/*
使用 poll(pollfds_.data(), pollfds_.size(), timeout) 进行阻塞等待,直到有事件发生(或超时)
和select一样,还是会有用户空间和内核空间的数据复制
且内核要遍历所有pollfd
poll返回后,需要遍历所有的 pollfds_,检查其 revents 字段,看是否有事件发生,比如:
for (const auto& pfd : pollfds_) {
if (pfd.revents & POLLIN) {xxx}
else if (pfd.revents & POLLOUT) {xxx}
xxx
}
*/
int wait(std::vector<Event>& events, int timeout = -1) override;
}
// Epoll实现
class EpollIO : public IOMultiplexing {
private:
int epollfd_;
std::vector<epoll_event> events_;
public:
// 构造时就会创建epollfd:`epollfd_ = epoll_create1(0);`
EpollIO(int max_events = 1024); // 此处可优化,参考下篇muduo实现
~EpollIO() override;
// epoll_ctl向epoll注册事件,如:`epoll_ctl(epollfd_, EPOLL_CTL_ADD, fd, &ev)`
bool addEvent(int fd, EventType type) override;
// epoll_ctl从epoll移除,如:`epoll_ctl(epollfd_, EPOLL_CTL_DEL, fd, nullptr)`
bool removeEvent(int fd, EventType type) override;
// epoll_ctl进行修改,如:epoll_ctl(epollfd_, EPOLL_CTL_MOD, fd, &ev)
bool modifyEvent(int fd, EventType type) override;
/*
使用 int ret = epoll_wait(epollfd_, events_.data(), events_.size(), timeout) 进行阻塞等待,直到有事件发生(或超时)
这里的返回值ret表示就绪的fd数量,即 events_ 中就绪事件的个数
使用红黑树管理文件描述符,没有固定的文件描述符数量限制,链表来管理就绪的文件描述符
通过 epoll_ctl 系统调用将文件描述符的注册和修改操作在内核中完成,不需要像select和poll那样复制
支持 边缘触发(Edge Triggered,ET) 和 水平触发(Level Triggered,LT),默认水平触发。边缘触发模式可进一步提升性能(但更复杂)
循环处理 ret 个事件即可,如
for (int i = 0; i < ret; ++i) {
if (events_[i].events & EPOLLIN) {xxx}
else if (events_[i].events & EPOLLOUT) {xxx}
xxx
}
*/
int wait(std::vector<Event>& events, int timeout = -1) override;
}
PS:当前GitHub Copilot也可以直接用了,不用绑定银行卡
4. 代码构建
- 本地编译方式
- 直接make,调整hiredis库的
.pc配置路径后,make编译正常
- 直接make,调整hiredis库的
- docker构建方式(TODO)
- 到docker目录,开始构建
docker compose up --build。 - 问题记录:
- CentOS已停止维护,yum源部分项失败。跟AI来回捣腾几次,调整为本地下载yum源配置文件,dockerfile里集成,还是失败了
- 按意见在docker-compose.yml里新增dns、在dockerfile里修改resolv.conf但是只读,均失败,先基于宿主机调试了
- 到docker目录,开始构建
5. 运行调试
准备:安装redis并启动、初始化MySQL数据:mysql -uroot -ptest < docker/init.sql
1、基本运行
2、进一步优化和问题修改:调整新增日志、空数据处理、主键冲突调整
结果:
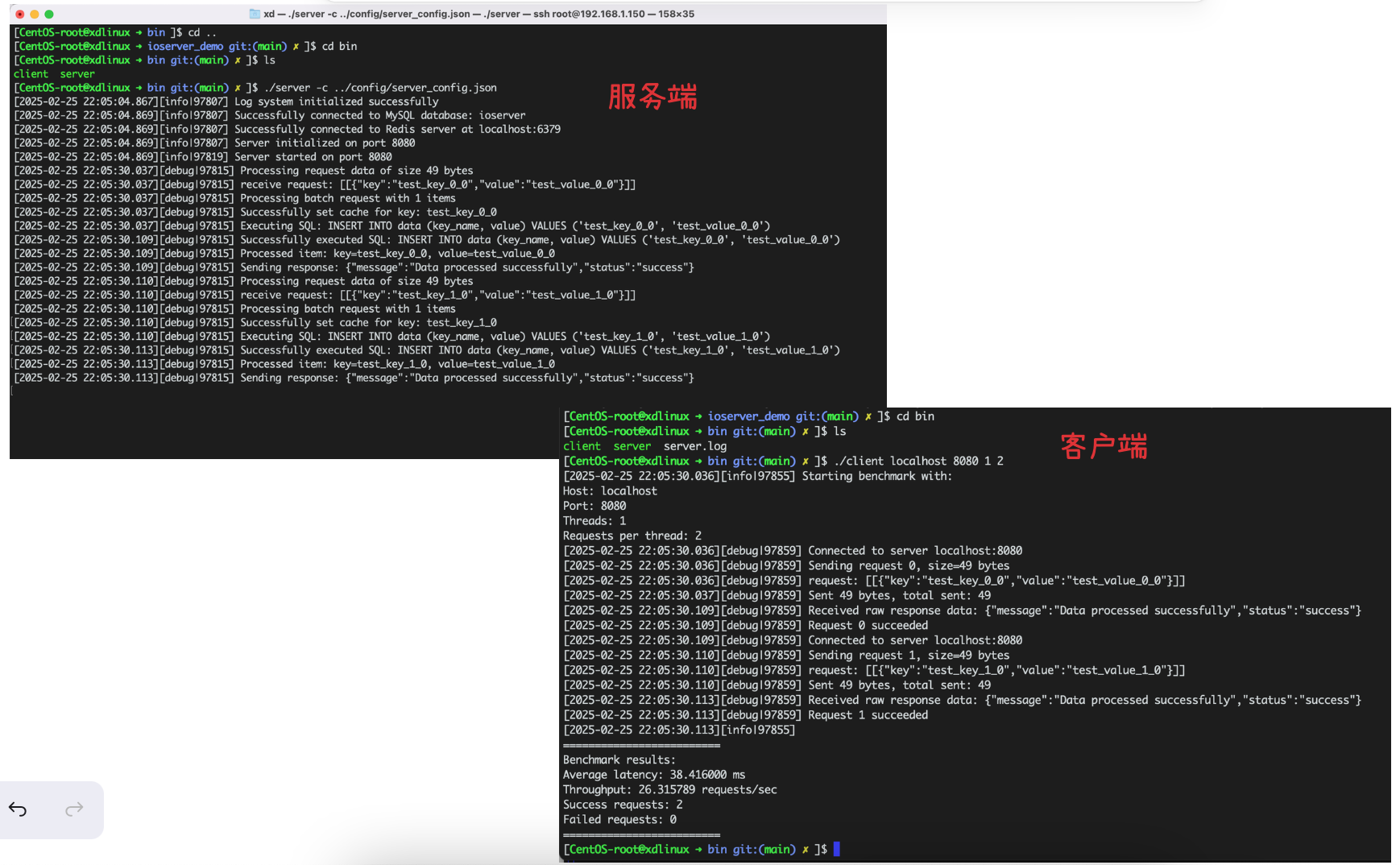
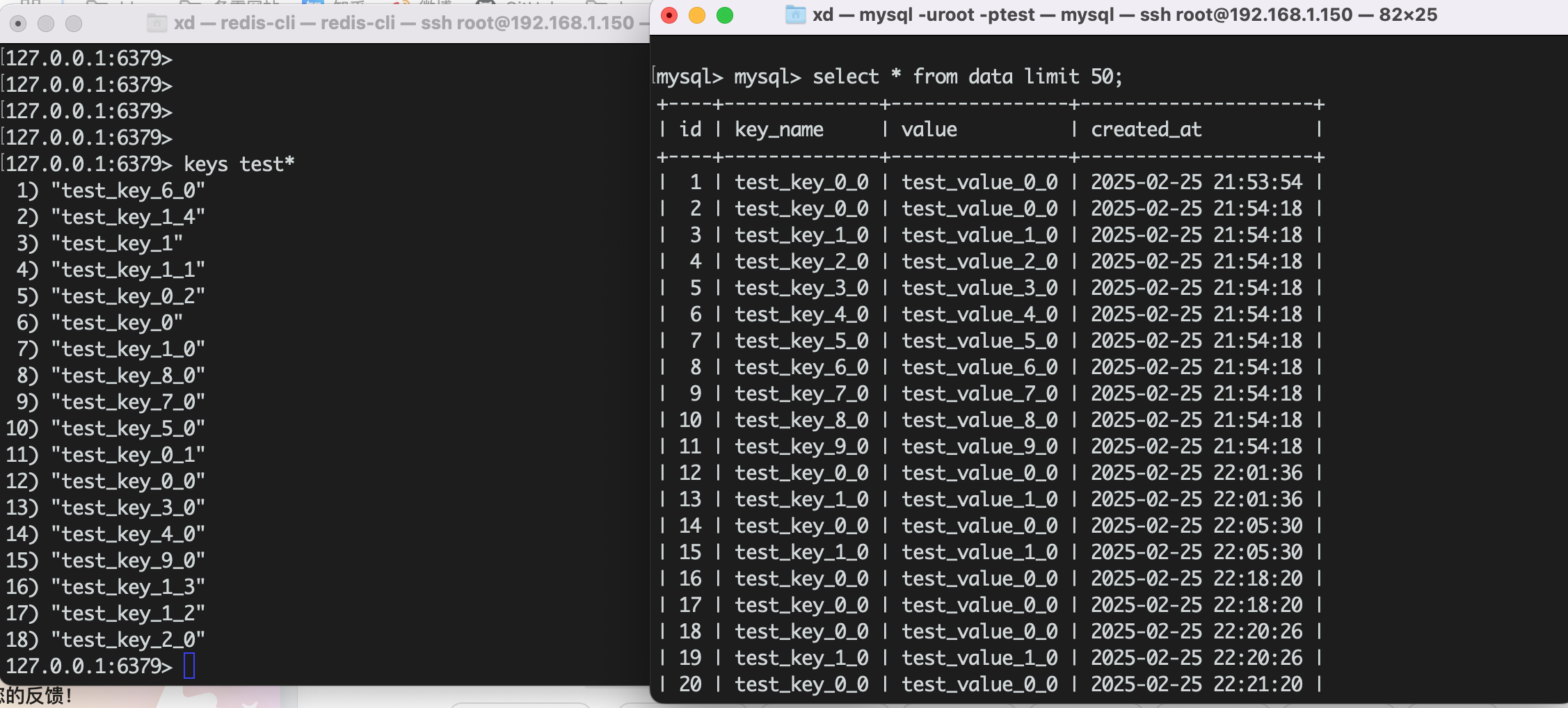
redis和MySQL结果:
3、发送信号动态调整日志等级为info,kill -HUP 97807,调整正常
[CentOS-root@xdlinux ➜ bin git:(main) ✗ ]$ cat ../config/server_config.json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
{
"server": {
"port": 8080,
"num_threads": 4
},
"database": {
"mysql": {
"host": "localhost",
"user": "root",
"password": "test",
"database": "ioserver"
},
"redis": {
"host": "localhost",
"port": 6379
}
},
"logging": {
"log_file": "server.log",
"log_level": "info",
"console_output": true
}
}
4、客户端上并发就出问题了,不过简单流程是跑起来了
6. 小结
基于AI工具生成项目框架和逻辑,从其中实现可以学习不少东西,虽然不能完全即拿即用。先理解整体代码逻辑后,再结合手动调整和指示AI优化,效率提升明显。
当前阶段TODO问题:
- 客户端并发问题
- docker构建问题
- 数据库连接池问题
下一步定位问题并优化,并基于当前项目扩展深入。
7. 参考
- trae + Claude-3.5-Sonnet