并发与异步编程(二) -- 异步编程框架
介绍几种异步编程框架,并学习基本原理。
介绍几种异步编程框架,并学习基本原理。
1. 背景
并发与异步编程(一) – 实现一个简单线程池 中,实现了一个基本的线程池,当时的异步编程实现还留了一个TODO。
本篇先学习异步编程的几个框架和基本原理,后续进行编程实践和性能观察对比。
主要学习了解异步编程相关的:Linux AIO、io_uring、SPDK、C++的Boost.Asio、std::async
参考:
- [译] Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测(2020)
- 浅析开源项目之io_uring
- Linux原生异步IO原理与实现(Native AIO)
- Boost.Asio
- cppreference std::async
- SPDK Doc
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 总体说明
借着 [译] Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测(2020) 中的Linux I/O系统调用演进说明,引入异步IO。
Linux I/O系统调用演进:
- 1、基于fd的阻塞式 I/O:
read()/write()- fd可指向本地文件(storage files)、也可指向网络socket(network sockets)
- 皆为阻塞式系统调用(blocking system calls)
- 2、非阻塞式 I/O:
select()/poll()/epoll()- 只支持 网络sockets 和 pipes管道
- epoll也并不是异步网络IO,epoll回调事件通知,具体的读写操作仍然需要用户去做,而不是内核代替完成
- 3、线程池方式
- storage I/O,经典解决思路是线程池。主线程将 I/O 分发给 worker 线程,worker中阻塞式读写
- 问题是 线程上下文切换开销可能非常大
- 4、Direct I/O
- 数据库软件(database software)有时不想用系统的page cache,而是自己管理缓存,会使用直接IO
- 设置
O_DIRECT选项。- 之前在 Linux存储IO栈梳理(三) – eBPF和ftrace跟踪IO写流程 中也做过直接IO实验,需要保证申请的空间和系统blocksize对齐(
posix_memalign),且write时长度也须为blocksize整数倍。 - 现代盘的blocksize一般为4KB,可
blockdev --getbsz /dev/nvme0n1查看,我PC的盘就是4096(传统盘可能为512字节)
- 之前在 Linux存储IO栈梳理(三) – eBPF和ftrace跟踪IO写流程 中也做过直接IO实验,需要保证申请的空间和系统blocksize对齐(
- 5、异步 IO(AIO)
- 随着存储设备越来越快,主线程和 worker 线性之间的上下文切换开销占比越来越高。
- 市场上有些设备,延迟已经低到和上下文切换一个量级(微秒 us),意味着上下文每切换一次,我们就少一次
dispatchI/O 的机会 - 比如 Intel Optane
- 市场上有些设备,延迟已经低到和上下文切换一个量级(微秒 us),意味着上下文每切换一次,我们就少一次
- 因此,Linux 2.6 内核引入了异步 I/O(asynchronous I/O)接口:
Linux AIO。- 基本原理:1)通过
io_submit()提交 I/O 请求 2)后续io_getevents()检查哪些 events 已经 ready 了
- 基本原理:1)通过
- 对于block层的调度,
bio进入request(简称rq)队列后,设备驱动程序拉取一个rq存到dispatch队列,而后封装成cmd(比如scsi_cmnd)- 可参考 Linux存储IO栈梳理(四) – 通用块层 里梳理的流程
- 但是,Linux AIO有不少问题:只支持
O_DIRECT文件、接口设计未考虑扩展性、很多可能的原因会导致阻塞,可了解:Linux kernel AIO这个奇葩
- 随着存储设备越来越快,主线程和 worker 线性之间的上下文切换开销占比越来越高。
Linux迫切需要一个完善的异步机制。同时在Linux平台上跑的大多数程序都是专用程序,并不需要内核的大多数功能,而且这几年也流行kernel bypass,intel也发起的用户态IO DPDK、SPDK。但是这些用户态IO API不统一,使用成本过高,所以内核便推出了io_uring来统一网络和磁盘的异步IO,提供一套统一完善的异步API,也支持异步、轮询、无锁、zero copy。
见:浅析开源项目之io_uring。
3. Linux AIO
先来了解Linux原生(Native)的AIO处理流程。加原生是因为Linux存在很多第三方异步IO库,如 libeio 和 glibc AIO,所以为了加以区别,Linux内核提供的异步IO就称为 原生异步IO。
很多第三方的异步IO库都不是真正的异步IO,而是使用多线程来模拟异步IO,如 libeio 就是使用多线程来模拟异步IO的。
异步IO流程示意图:
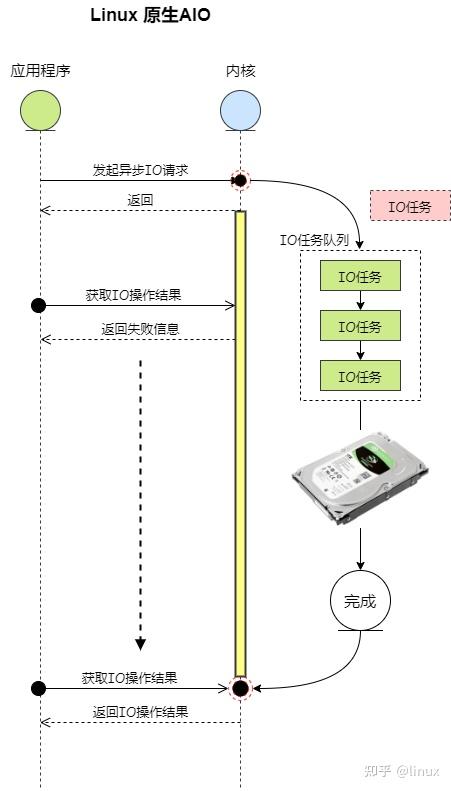
上图流程说明:
- 当应用程序调用
io_submit系统调用发起一个 异步IO操作 后,会向内核的 IO任务队列 中添加一个IO任务,并且返回成功 - 内核会在后台处理 IO任务队列 中的IO任务,然后把处理结果存储在IO任务中
- 应用程序可以调用
io_getevents系统调用来获取异步IO的处理结果,如果IO操作还没完成,那么返回失败信息,否则会返回 IO处理结果
API(具体实现源码在fs/aio.c中)使用步骤:
- 1、调用
io_setup函数创建一个 异步IO上下文struct kioctx结构来表示上下文,其中的ring_info成员是一个环形缓冲区(Ring Buffer),用于存放异步IO操作的结果
- 2、调用
io_submit函数向内核提交一个 异步IO操作- 从用户空间复制 异步IO操作信息 到内核空间,而后提交异步IO操作
- 3、调用
io_getevents函数获取异步IO操作结果- 当异步IO操作完成后,内核会调用
aio_complete函数来把处理结果放进异步IO上下文的环形缓冲区ring_info中 - 当把异步IO操作的结果保存到
环形缓冲区后,用户层就可以通过调用io_getevents函数来读取IO操作的结果了
- 当异步IO操作完成后,内核会调用
参考:Linux原生异步IO原理与实现(Native AIO)
4. io_uring
4.1. 基本介绍
io_uring的作者是 Jens Axboe,同时也是fio、blktrace的作者。
io_uring的高性能依赖以下几个方面:
- 用户态和内核态共享
提交队列(SQ,submission queue)和完成队列(CQ,completion queue)- 两个队列都是单生产者、单消费者;
- 队列提供
无锁接口(lock-less access interface),内部使用内存屏障(memory barriers)做同步
- 用户态支持Polling模式,不依赖硬件的中断,通过调用
IORING_ENTER_GETEVENTS不断轮询收割(reap)完成事件 - 内核态支持Polling模式,IO 提交和收割可以 offload 给 Kernel,且提交和完成不需要经过系统调用(system call)
- 在Direct I/O下可以提前注册用户态内存地址,减小地址映射的开销
io_uring 实例支持三种工作模式:
- 中断驱动模式(interrupt driven),也是默认模式
- 轮询模式(polled)
- 内核轮询模式(kernel polled)
4.2. 使用流程简要说明
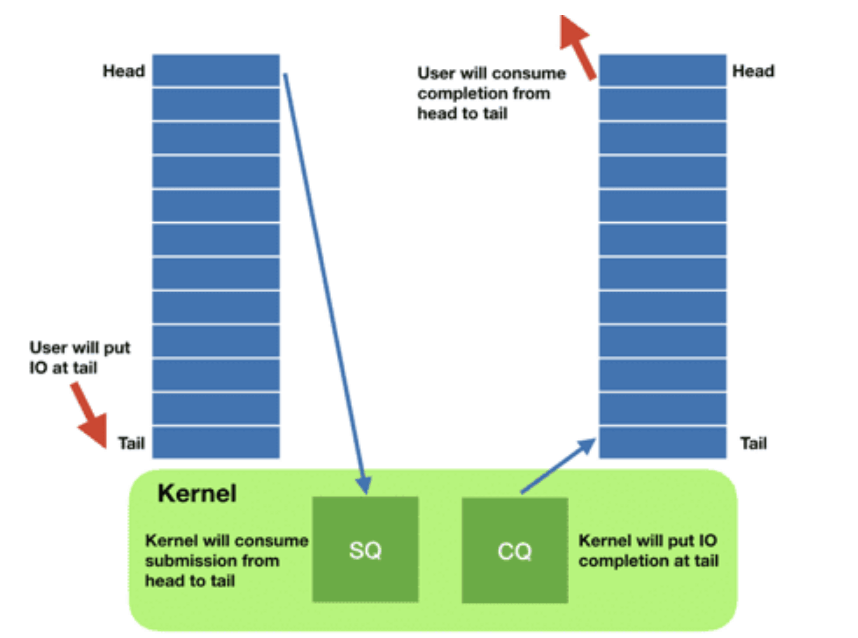
SQ、CQ队列示意图如下:
参考
使用流程:
- 请求
- 应用创建 SQ entries (
SQE),更新 SQ tail - 内核消费
SQE,更新 SQ head
- 应用创建 SQ entries (
- 完成
- 内核为完成的一个或多个请求创建 CQ entries (
CQE),更新 CQ tail - 应用消费
CQE,更新 CQ head
- 内核为完成的一个或多个请求创建 CQ entries (
io_uring提供了3个系统调用API:
io_uring_setup- 执行异步 I/O 需要先设置上下文,该接口创建一个
SQ和一个CQ - SQ 和 CQ 在应用和内核之间共享,避免了在初始化和完成 I/O 时(initiating and completing I/O)拷贝数据
- 函数声明:int io_uring_setup(u32 entries, struct io_uring_params *p);
- 执行异步 I/O 需要先设置上下文,该接口创建一个
io_uring_register- 注册文件或用户缓冲区(files or user buffers)
- int io_uring_register(unsigned int fd, unsigned int opcode, void *arg, unsigned int nr_args);
io_uring_enter- 用于初始化和完成(initiate and complete)I/O,使用共享的
SQ和CQ - io_uring_enter即可以提交I/O,也可以来收割完成的I/O,一般I/O完成时内核会自动将
SQE的索引放入到CQ中,用户可以遍历CQ来处理完成的IO - int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t *sig);
- 用于初始化和完成(initiate and complete)I/O,使用共享的
4.3. liburing
io_uring虽然仅提供了3个系统API,但是用起来还是比较复杂的,所以io_uring作者封装了一个高层API:liburing,简化了io_uring的使用。
比如:manpage中,io_uring_setup()获得一个ring文件描述符后,应用必须调用mmap()等进行后续操作,在liburing中,只要使用io_uring_queue_init函数,其中把上述流程已经封装好了。
项目仓库:liburing,仓库的examples下有使用示例
4.4. io_uring性能对比
[译] Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测(2020) 参考链接中的描述了基于fio进行的性能测试情况,此处暂简单列举参考,后续了解fio中的不同io引擎的使用实现。
fio分别使用:sync(同步read)、posix-aio(基于线程池实现)、linux-aio、io_uring 等ioengine测试。
(8个CPU执行 72 个fio job,每个 job 随机读取 4 个文件,iodepth=8)
1、场景一:direct I/O 1KB 随机读(绕过 page cache)
Direct I/O(绕过系统页缓存):1KB 随机读,CPU 100% 下的 I/O 性能:
| backend | IOPS | context switches | IOPS ±% vs io_uring |
|---|---|---|---|
| sync | 814,000 | 27,625,004 | -42.6% |
| posix-aio (thread pool) | 433,000 | 64,112,335 | -69.4% |
| linux-aio | 1,322,000 | 10,114,149 | -6.7% |
| io_uring (basic) | 1,417,000 | 11,309,574 | — |
| io_uring (enhanced) | 1,486,000 | 11,483,468 | 4.9% |
结果分析:
- io_uring 相比 linux-aio 确实有一定提升,但并非革命性的
- io_uring 和 linux-aio 都比 同步read 接口快 2 倍,而后者又比 posix-aio 快 2 倍
同步read性能差,是由于没有page cache时,每次read会阻塞,涉及一次上下文切换posix-aio性能更差,是由于不仅内核和应用程序之间要频繁上下文切换,线程池之间也在频繁切换
2、场景二:buffered I/O 1KB 随机读(数据提前加载到内存,100% hot cache)
Buffered I/O(数据全部来自 page cache,100% hot cache):1KB 随机读,100% CPU 下的 I/O 性能:
| Backend | IOPS | context switches | IOPS ±% vs io_uring |
|---|---|---|---|
| sync | 4,906,000 | 105,797 | -2.3% |
| posix - aio (thread pool) | 1,070,000 | 114,791,187 | -78.7% |
| linux - aio | 4,127,000 | 105,052 | -17.9% |
| io_uring | 5,024,000 | 106,683 | — |
结果分析:
- 同步读和 io_uring 性能差距确实很小,二者都是最好的
- 该实验场景下构造了数据都在page cache,实际应用中,同步读性能会比io_uring差
- posix-aio 性能最差,直接原因是上下文切换次数太多
- 在这种CPU饱和的情况下,posix-aio的线程池反而是累赘,会完全拖慢性能
- linux-aio 并不是针对 buffered I/O 设计的,在这种 page cache 直接返回的场景,其异步接口反而有性能损失
小结:
- 上述极端应用/场景(100% CPU + 100% cache miss/hit)下的测试,真实应用通常处于两者之间,阻塞和非阻塞操作都有
- 阻塞和非阻塞场景下,io_uring 都有很好的表现
4.5. 使用io_uring的线上应用
几个使用io_uring的项目:
- rocksdb
- PosixRandomAccessFile::MultiRead()
- ceph
- ceph的io_uring主要使用在 block_device,抽象出了统一的块设备
- spdk
- 其抽象的通用块层加入了io_uring的支持,可了解:SPDK与io_uring新异步IO机制
- 第三方适配(nginx、redis、echo_server),event poll模式调整为io_uring
5. C++中的异步编程组件
5.1. Boost.Asio
Boost.Asio 是一个跨平台的C++库,用于处理各种网络和底层 I/O操作,使用现代C++方法为开发人员提供了一致的异步模型。
支持丰富的功能,包括网络、定时器(Timers)、文件(Files)、管道(Pipes)、串口(Serial Port)、信号(Signal Handling)等等。
Boost.Asio 官网中:
- Overview 提供了整体索引链接
- Using 里说明了编译器要求、依赖要求
- 若使用g++,g++ 4.6 or later 会定期测试(regularly tested)
- 依赖:
Boost.System用于错误码- 可选:若使用协程则还要
Boost.Coroutine、若使用正则则需要Boost.Regex、若使用SSL则要OpenSSL
- 可选:若使用协程则还要
- Examples 里有基于不同C++标准的示例,如C++11、14、17、20。
用户程序使用boost.asio的基本流程(具体见Basic Boost.Asio Anatomy):
- 1、至少要一个I/O执行上下文(
I/O execution context),表示程序链接到操作系统的IO服务(I/O services)- 比如
boost::asio::io_context对象、boost::asio::thread_pool对象 或boost::asio::system_context对象 - 定义示例:
boost::asio::io_context io_context;
- 比如
- 2、需要一个IO对象(I/O Object),用于执行I/O操作
- 比如一个TCP socket,
boost::asio::ip::tcp::socket test_socket(io_context);,传入的参数即上面定义的I/O执行上下文
- 比如一个TCP socket,
- 3、基于上面定义的 test_socket,有同步、异步编程模式。下面仅说明异步方式
- 1)初始化连接:
socket.async_connect(server_endpoint, your_completion_handler);your_completion_handler是自定义的回调函数,不同异步操作的回调函数签名不同,可参考API文档- 一个示例:
void your_completion_handler(const boost::system::error_code& ec);
- 2)I/O对象转发该请求给
I/O execution context(以下简称上下文) - 3)上下文 通知 操作系统 启动一个异步连接操作
- 4)一段时间后,操作系统提示异步连接操作完成,将结果放入队列,准备好可供 上下文 获取
- 5)用户程序定义的
io_context作为上下文时,需要执行io_context::run(),异步操作结束前,该函数阻塞 - 6)在
io_context::run()中,上下文会将异步操作的结果出队(dequeue),转换结果后将其传给自定义回调函数
- 1)初始化连接:
5.2. std::async
std::async 是 C++11 标准库引入的一个函数模板,位于 <future> 头文件中,用于启动一个异步任务。
声明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// std::async 声明1 (C++11起)
template< class F, class... Args >
std::future</* see below */> async( F&& f, Args&&... args );
// std::async 声明2 (C++11起)
// std::launch 主要用于指定 std::async 函数启动异步任务的策略。
template< class F, class... Args >
std::future</* see below */> async( std::launch policy,
F&& f, Args&&... args );
// 返回类型 为 std::future<V>,V 的定义如下:
// C++17前
typename std::result_of<typename std::decay<F>::type(
typename std::decay<Args>::type...)>::type
// C++17起
std::invoke_result_t<std::decay_t<F>, std::decay_t<Args>...>.
说明:
std::async返回值类型的定义有点复杂,具体见 std::async- 其中
std::decay的主要功能是对输入的类型进行转换,以模拟函数参数传递时的类型退化(decay)过程decay看起来有点抽象,举几个类型退化的例子就有体感了,比如:- 移除引用:如果输入类型是引用类型(左值引用或右值引用),则将其转换为对应的非引用类型
- 数组到指针的转换:如果输入类型是数组类型,则将其转换为指向数组元素类型的指针类型。类似函数传参
- 函数到函数指针的转换
- 移除 const 和 volatile 限定符,如果输入类型带有 const 或 volatile 限定符,在完成上述转换后,会移除这些限定符
- 使用场景:在模板函数或类中,当需要处理不同类型的参数时,std::decay 可以帮助我们获取参数的 “退化” 类型,从而进行统一的处理
std::launch主要用于指定 std::async 函数启动异步任务的策略。- 包含2个枚举值:
std::launch::async和std::launch::deferred,并可组合使用 std::launch::async表示 立即启动一个新的线程来异步执行指定的任务std::launch::deferred表示 延迟任务的执行,直到调用 std::future 对象的get()或wait()方法时才会执行任务- 如果在调用 std::async 时不指定启动策略,默认的策略是
std::launch::async | std::launch::deferred,这意味着实现可以选择异步执行(在新线程中)或延迟执行(在调用 get() 或 wait() 的线程中),具体的执行方式由编译器和运行时环境决定
- 包含2个枚举值:
使用示例,可参考:C++ 并发三剑客future, promise和async
std::promise,也是<future>头文件中提供的一个模板类,用于在多线程编程中实现线程间的同步和数据传递。- 一般和 std::future 组合使用,允许一个线程存储一个值或异常,供另一个线程通过关联的 std::future 对象来获取
- std::promise 本身不涉及线程管理,需要手动创建和管理线程(std::async 会根据启动策略自动处理线程的创建和管理)
- 适用场景:std::async 更适合简单的异步任务,可以自动管理线程的创建和销毁;std::promise 更适合需要手动控制线程间通信的场景,允许一个线程在某个时刻设置结果,另一个线程在合适的时候获取结果
比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include <iostream>
#include <future>
#include <chrono>
// 定义一个异步任务
std::string fetchDataFromDB(std::string query) {
// 模拟一个异步任务,比如从数据库中获取数据
std::this_thread::sleep_for(std::chrono::seconds(5));
return "Data: " + query;
}
int main() {
// 使用 std::async 异步调用 fetchDataFromDB
std::future<std::string> resultFromDB = std::async(std::launch::async, fetchDataFromDB, "Data");
// 在主线程中做其他事情
std::cout << "Doing something else..." << std::endl;
// 从 future 对象中获取数据
// std::future::get() 是一个阻塞调用,用于获取 std::future 对象表示的值或异常。
// get() 只能调用一次,因为它会移动或消耗掉 std::future 对象的状态
// 作为对比:std::future::wait() 也是阻塞调用,只是等待任务完成,可以被多次调用
std::string dbData = resultFromDB.get();
std::cout << dbData << std::endl;
return 0;
}
6. SPDK
SPDK(Storage Performance Development Kit,存储性能开发套件)是一套用于构建高性能、可扩展、用户态存储应用的工具和库集合(由英特尔开源)。
核心技术点:
- 用户态驱动:将所有必要驱动移至
用户空间,避免系统调用并实现应用层零拷贝访问- 比如 直接通过用户态访问 SSD 的 NVMe 驱动
- 轮询模式:通过硬件来轮询 完成事件(Polling hardware for completions) 替代 中断机制(interrupts),降低总延迟和延迟变化(lowers both total latency and latency variance)
- 无锁 I/O 路径:采用消息传递(message passing)替代锁机制,实现 I/O 路径完全无锁化
官网文档:SPDK Doc
- Concepts 里介绍了一些基本概念
- 用户空间驱动:传统驱动运行于内核空间(
Ring 0),需通过系统调用与用户程序交互;SPDK 驱动运行于用户空间(Ring 3),直接通过硬件映射实现零拷贝访问- 设备控制流程:通过
sysfs解除内核驱动绑定,绑定 Linux 内置的uio或vfio虚拟驱动;通过uio/vfio将设备映射到用户进程虚拟地址空间,直接通过MMIO(内存映射 I/O)操作硬件寄存器 - 轮询替代中断、异步回调机制,I/O操作完成后通过回调函数通知应用,避免阻塞主线程
- 设备控制流程:通过
- 用户空间的直接内存访问(DMA)
- 用户空间驱动:传统驱动运行于内核空间(
SPDK 并不局限于只能用于SSD,支持NVMe SSD、SCSI设备、虚拟块设备(用于KVM等虚拟化平台)、网络存储设备,如 NVMe over Fabrics(NVMe-oF)和 iSCSI。
暂做初步了解,后续按需深入。
7. DPDK
简单了解了专注存储的SPDK,DPDK也了解下。
官网介绍:ABOUT DPDK
DPDK(Data Plane Development Kit,数据平面开发套件)是Linux基金会(Linux Foundation)旗下的开源项目,包含一系列用于加速跨多种CPU架构(比如 Intel x86, ARM, and PowerPC)运行的数据包处理工作负载的库(libraries)。(也由英特尔开源)
网络性能、吞吐量和延迟 对于无线/有线基础设施、路由器、负载均衡器、防火墙、视频流和 VoIP 等多样化应用至关重要。DPDK通过高效的 “运行至完成”(run-to-completion model) 模型和预分配资源的优化库,显著提升网络应用性能。
一些核心组件:
- EAL(Environment Abstraction Layer,环境抽象层),为应用抽象硬件细节,支持 x86/ARM/PowerPC 等平台的可移植代码
- 内存管理:大页支持、内存池和缓冲区管理
- PMD(Poll Mode Drivers,轮询模式驱动):绕过内核网络栈,优化网络接口驱动
- 环形缓冲区(Ring Buffers):无锁 FIFO 队列,实现高速进程间通信
- 数据包处理 API:提供头部解析、分类、转发等功能
- 加密与安全:支持加密操作和安全通信
- 事件与定时器:事件驱动编程和时间管理
相关文档:
- Programmer’s Guide 介绍软件架构信息、开发环境信息和优化参考
- Sample Applications 里可查看DPDK的示例程序
- 从简单的helloworld、到各层网络的数据转发、QoS调度等等
- System Requirements 系统依赖
- 部分依赖:系统内核 >= 4.19、glibc >= 2.7、一些内核配置
8. 小结
学习了解几种异步编程框架和机制,建立基本的体感,为后续使用和深入打个基础。