Redis学习实践(一) -- 数据类型和底层数据结构
Redis数据类型和对应的底层数据结构。
本篇说明Redis数据类型和对应的底层数据结构。
1. 背景
前面梳理的知识脉络中或多或少覆盖了网络、存储、内存、进程管理等,虽然不少东西还没太深入,不过已经打了一个底子,后续逐步添砖加瓦。开始基于实际的优秀产品和开源项目补充夯实技能栈,梳理并进行相关实践。
先梳理学习存储领域相关内容(内容很多,忌贪多嚼不烂,过程中拓展广度和深度):
Redis、MySQL、Ceph、RocksDB、HDFS- 后续进一步梳理学习:
PostgreSQL,以及之前关注了解的Curve、TiDB、JuiceFS、CubeFS、GlusterFS,以及近期比较火热的DeepSeek开源的3FS(Fire-Flyer File System,萤火文件系统)等
Redis之前看过代码但未系统梳理,本篇开始,先来梳理学习其相关内容并进行部分实验。
简要介绍:
- Redis(
Remote Dictionary Server)是一个使用ANSI C编写的支持网络、基于内存、分布式、可选持久性的键值对存储数据库,作者是 Salvatore Sanfilippo(也叫 antirez)。 - 2024年,开源许可从Redis 7.4版本开始,由
BSD-3-Clause协议转换为SSPLv1和RSALv2双重许可证。介绍可见:Redis。
Redis应用场景很多,比如缓存系统、消息队列、分布式锁等,比如下述缓存系统简单示意图(主要为了试下Follow Animation动态箭头效果):

说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 前置说明
梳理代码基于支持了多线程特性的6.0版本:redis 6.0。并进行 fork。
几个参考:
3. 数据类型和底层数据结构
5种最常用数据类型:String、List、Hash、Set、Zset
1、String
- 最大容纳
512MB - 底层数据结构:
SDS,可保存文本以及二进制数据、长度获取复杂度O(1)、字符串操作安全(因为有了头中的长度) - 基本命令:GET、SET、EXIST、STRLEN、DEL;MGET、MSET;SETEX、EXPIRE、TTL;INCR、INCRBY、DECR、DECRBY;SETNX等
- 应用场景
- 缓存对象:方式1)直接缓存json 方式2)按k-v分离,通过MSET存储、MGET获取
- 常规计数:如访问次数、点赞、转发、库存。
SET aritcle:readcount:1001 0初始化,而后INCR aritcle:readcount:1001 - 分布式锁:SET有个
NX参数可以实现“key不存在才插入”,可以用它来实现分布式锁SET lock_key unique_value NX PX 10000,若不存在则设置,表示加锁成功;- 删除key则表示解锁,需要保证删除者是加锁客户端,需要 Lua脚本 保证原子性
- 共享Session信息:分布式系统中同用户多次请求可能分配到不同服务器,通过Redis共享统一的会话状态可避免重复登录
2、List
- 字符串列表,最大元素个数:
2^32-1(40亿) - 底层数据结构
- 3.2版本前:双向链表 或 压缩列表(ziplist),当
(列表元素个数<512 && 元素值<64字节)时,会用ziplist作底层数据结构,否则用双向链表 - 3.2之后:只用
quicklist,替代了双向链表和压缩列表
- 3.2版本前:双向链表 或 压缩列表(ziplist),当
- 基本命令:LPUSH、RPUSH、LPOP、RPOP、LRANGE、BLPOP、BRPOP、LLEN、LSET等
- 应用场景
- 消息队列:LPUSH+RPOP 或者 RPUSH+LPOP 实现先进先出。为了避免没有数据时的循环POP判断,Redis提供了
BRPOP方式;为避免重复消费,需自行实现全局ID,如LPUSH mq "111000102:stock:99";为避免消息消费后处理异常,Redis提供了BRPOPLPUSH,在消费的同时插入另一个List备份;不能多消费者以消费组形式消费
- 消息队列:LPUSH+RPOP 或者 RPUSH+LPOP 实现先进先出。为了避免没有数据时的循环POP判断,Redis提供了
3、Hash
- 键值对
- 底层数据结构
- 压缩列表 或 哈希表,当
(元素个数<512 && 所有值<64字节)时,会使用ziplist作底层数据结构,否则使用哈希表 - Redis7.0中,压缩列表数据结构已经废弃,交由
listpack数据结构实现
- 压缩列表 或 哈希表,当
- 常用命令:HSET、HGET、HMSET、HMGET、HDEL、HLEN、HGETALL、HINCRBY等
- 应用场景
- 缓存对象:上面String也可以存放对象,对于频繁变化的属性可以考虑抽出来用Hash存储
- 购物车:以用户id为 key,商品id 为 field,商品数量为 value(
HSET key field value)
4、Set
- 无序集合,最大个数:
2^32-1。除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集。 - 底层数据结构:哈希表 或 整数集合(intset),当
(元素都是整数 && 个数<512),使用整数集合作底层数据结构,否则使用哈希表 - 常用命令:SADD、SREM、SMEMBERS、SCARD、SISMEMBER、SPOP;SINTER、SUNION、SDIFF等
- 应用场景
- Set类型比较适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等
- 但要注意:Set的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。
- 点赞(一个用户只能点一个赞)、共同关注(交集运算)、抽奖活动(
SRANDMEMBER、SPOP随机取元素)
- Set类型比较适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等
5、Zset
- 有序集合,相比Set多了排序属性
score(分值) - 底层数据结构:
- 压缩列表 或 跳表,
(个数<128 && 每个元素值<64字节)时,会使用ziplist作底层数据结构,否则使用跳表 - Redis7.0中,压缩列表数据结构已经废弃,交由
listpack数据结构实现 - 另外使用 哈希表 查找插入的元素是否存在
- 压缩列表 或 跳表,
- 常用命令:ZADD、ZREM、ZSCORE、ZCARD、ZINCRBY、ZRANGE、ZRANGEBYSCORE、ZRANGEBYLEX;ZUNIONSTORE、ZINTERSTORE等
- 应用场景
- 排行榜,例如学生成绩的排名榜、游戏积分排行榜、视频播放排名、电商系统中商品的销量排名
- 电话、姓名排序,
ZRANGEBYLEX
其他4种数据类型:BitMap、HyperLogLog、GEO、Stream
6、BitMap(2.2版本新增)
- 位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素
- 底层数据结构:String类型作为底层数据结构实现的一种统计二值状态的数据类型
- 常用命令:SETBIT、GETBIT、BITCOUNT;BITOP、BITPOS
- 应用场景:非常适合二值状态统计的场景
- 签到统计
- 判断用户登陆态
- 连续签到用户总数
7、HyperLogLog(2.8版本新增)
- 统计基数,统计一个集合中不重复的元素个数。HyperLogLog是统计规则是基于概率完成的,存在误差。优点是在输入元素的数量或者体积非常非常大时,计算基数所需的内存空间总是固定的、并且是很小的
8、GEO(3.2版本新增)
- 存储地理位置信息,并对存储的信息进行操作
- 底层数据结构:本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 集合类型。使用 GeoHash 编码方法
- 应用场景:滴滴叫车
9、Stream(5.0版本新增)
- 支持消息的持久化、支持自动生成全局唯一ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
- 应用场景:消息队列
4. 数据结构实现说明
简要说明上述“数据类型”用到的“数据结构”对应的实现。
4.1. SDS
- 相对普通字符串,其实现中包含:长度
len和分配空间长度alloc,能灵活保存不同大小的字符串,从而有效节省内存空间- sdshdr8、sdshdr16、32、64,以及sdshdr5(不再使用),定义差别是
len和alloc使用uint16、uint32、64等支持不同长度 - 获取字符串长度;字符串追加、复制、比较的效率都比普通字符串高
- sdshdr8、sdshdr16、32、64,以及sdshdr5(不再使用),定义差别是
attribute ((packed)),告知编译器,在编译 sdshdr8 结构时,不要使用字节对齐的方式,而是采用紧凑型方式分配内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// redis/src/sds.h
struct __attribute__ ((__packed__)) sdshdr8 {
// 字符数组现有长度
uint8_t len; /* used */
// 字符数组的已分配空间,不包括结构体和\0结束字符
uint8_t alloc; /* excluding the header and null terminator */
// SDS类型,低3位表示类型,和b111进行位掩码取&
unsigned char flags; /* 3 lsb of type, 5 unused bits */
// 字符数组数据
char buf[];
};
// 对应的操作
sds sdsnewlen(const void *init, size_t initlen);
sds sdsnew(const char *init);
sds sdsempty(void);
sds sdsdup(const sds s);
void sdsfree(sds s);
...
4.2. 双向链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// redis/src/adlist.h
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
// 对应的操作
list *listCreate(void);
void listRelease(list *list);
void listEmpty(list *list);
list *listAddNodeHead(list *list, void *value);
list *listAddNodeTail(list *list, void *value);
list *listInsertNode(list *list, listNode *old_node, void *value, int after);
...
4.3. 压缩列表(ziplist)
在 ziplist.h 文件中其实根本看不到压缩列表的结构体定义,因为压缩列表本身就是一块连续的内存空间,它通过使用不同的编码来保存数据。
1
2
3
4
5
6
7
// redis/src/ziplist.h
unsigned char *ziplistNew(void);
unsigned char *ziplistMerge(unsigned char **first, unsigned char **second);
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where);
unsigned char *ziplistIndex(unsigned char *zl, int index);
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p);
...
ziplist结构如下:
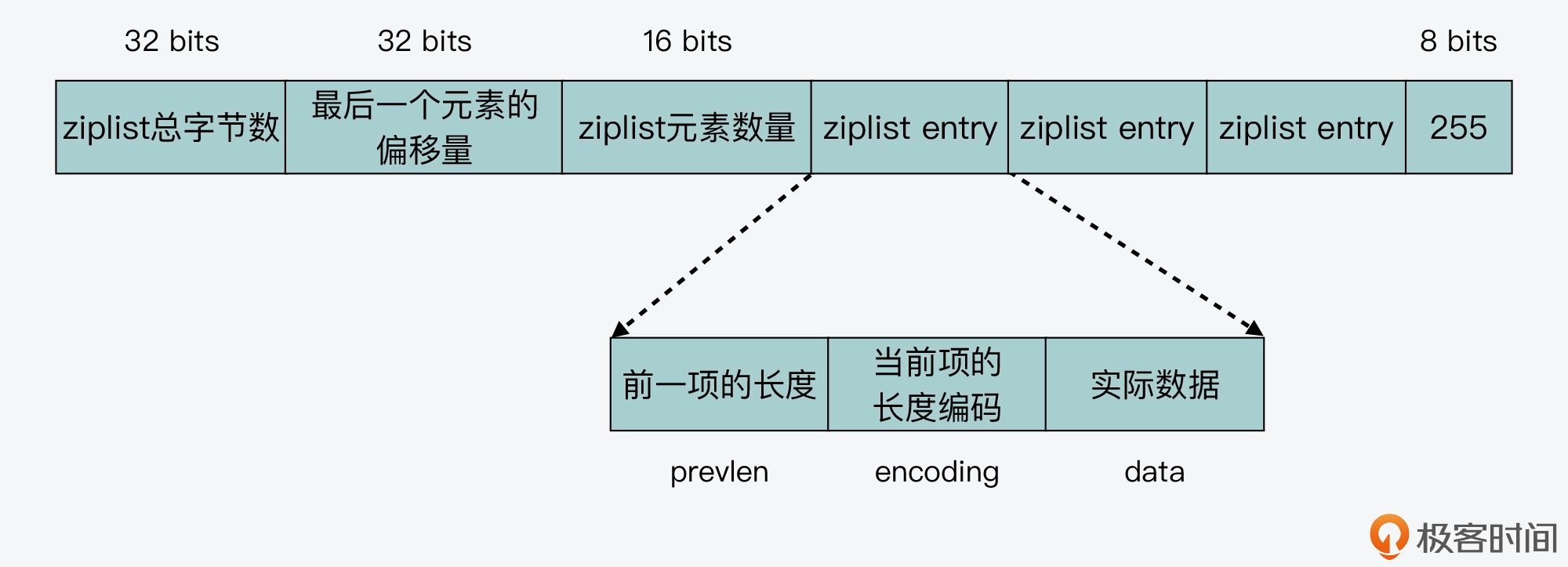
通过ziplist的创建来理解其结构:
- 创建一块连续的内存空间,大小为 ZIPLIST_HEADER_SIZE 和 ZIPLIST_END_SIZE 的总和,然后再把该连续空间的最后一个字节赋值为 ZIP_END,表示列表结束。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// redis/src/ziplist.c
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
#define ZIP_END 255 /* Special "end of ziplist" entry. */
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE + ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
插入操作(插入列表项):
- 往 ziplist 中插入数据时,ziplist 就会根据数据是字符串还是整数,以及它们的大小进行不同的编码。
- 这种根据数据大小进行相应编码的设计思想,正是 Redis 为了节省内存而采用的。
- 在 ziplist 中,编码技术主要应用在列表项中的
prevlen和encoding这两个元数据上。而当前项的实际数据 data,则正常用整数或是字符串来表示。- 根据前一个列表项大小判断,
prevlen使用1字节还是5字节存储 - 针对插入数据为
整数还是字符串,就分别使用了不同字节长度(encoding)的编码结果
- 根据前一个列表项大小判断,
- ziplist 在新插入元素时,会计算其所需的新增空间,并进行重新分配。而当新插入的元素较大时,就会引起插入位置的元素
prevlensize增加,进而就会导致插入位置的元素所占空间也增加- 如此一来,这种空间新增就会引起连锁更新的问题。
- 虽然 ziplist 紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,ziplist 就会面临性能问题
- 避免连锁更新设计:
quicklist和listpack
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
// redis/src/ziplist.c
unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
return __ziplistInsert(zl,p,s,slen);
}
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
// 获取当前ziplist长度curlen;
// 声明reqlen变量,用来记录新插入元素所需的长度
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
...
// 当前要插入的位置是否是列表末尾,如果不是末尾,那么就需要获取位于当前插入位置的元素的 prevlen 和 prevlensize
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
// 计算实际插入元素的长度
if (zipTryEncoding(s,slen,&value,&encoding)) {
reqlen = zipIntSize(encoding);
} else {
reqlen = slen;
}
// 将插入位置元素的 prevlen 也计算到所需空间中
reqlen += zipStorePrevEntryLength(NULL,prevlen);
// 根据字符串的长度,计算相应 encoding 的大小
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
...
// 判断插入位置元素的 prevlen 和实际所需的 prevlen,这两者间的大小差别
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
...
// 其中会调用 zrealloc 函数,来完成空间的重新分配
// 如果往 ziplist 频繁插入过多数据的话,就可能引起多次内存分配,从而会对 Redis 性能造成影响
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
...
// 而当新插入的元素较大时,就会引起插入位置的元素 prevlensize 增加,进而就会导致插入位置的元素所占空间也增加。
// 如此一来,这种空间新增就会引起连锁更新的问题
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
...
}
4.4. hash table
Redis中的哈希实现为 dict,使用链表法解决哈希冲突,其中包含2个哈希表(dictht),用于实现渐进式rehash
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// redis/src/dict.h
// 字典
typedef struct dict {
dictType *type;
void *privdata;
// 2个哈希表,用于实现渐进式rehash
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
// 哈希表
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
// 哈希项
typedef struct dictEntry {
void *key;
// 使用联合体节省内存
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
// 操作API
dict *dictCreate(dictType *type, void *privDataPtr);
int dictExpand(dict *d, unsigned long size);
int dictAdd(dict *d, void *key, void *val);
...
4.5. 整数集合(intset)
和 SDS、ziplist 类似,整数集合也是一块连续的内存空间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// redis/src/intset.h
typedef struct intset {
uint32_t encoding;
uint32_t length;
// 记录数据的部分
int8_t contents[];
} intset;
// 操作API
intset *intsetNew(void);
intset *intsetAdd(intset *is, int64_t value, uint8_t *success);
intset *intsetRemove(intset *is, int64_t value, int *success);
uint8_t intsetFind(intset *is, int64_t value);
...
创建时初始化连续内存:
1
2
3
4
5
6
7
// redis/src/intset.c
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
}
4.6. Zset和跳表(skiplist)
Zset有序集合(Sorted Set) 的实现代码在t_zset.c文件中,结构则定义在server.h中,包括两个成员:哈希表和跳表。
关于跳表,之前在LevelDB的memtable实现梳理中有做过说明:LevelDB学习笔记(四) – memtable结构实现。
1
2
3
4
5
6
7
8
9
10
11
12
// redis/src/server.h
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
// 操作
zskiplist *zslCreate(void);
void zslFree(zskiplist *zsl);
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele);
unsigned char *zzlInsert(unsigned char *zl, sds ele, double score);
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node);
跳表 zskiplist 结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// redis/src/server.h
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
插入数据时,会判断 Sorted Set 采用的是 ziplist 还是 skiplist 的编码方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {
...
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
...
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
...
}
...
}
if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
...
de = dictFind(zs->dict,ele);
...
}
...
}
4.7. quicklist
ziplist通过紧凑的内存布局来保存数据,节省了空间。但存在如下限制:
- 查找复杂度高:若要查找中间元素,需要从列表头或者尾部开始遍历
- 一般会限制元素个数,比如hash和zset使用压缩列表做底层数据结构时,就通过配置项限制:
hash-max-ziplist-entries(默认512) 和zset-max-ziplist-entries(默认128)
- 插入元素时,若内存空间不足则需重新分配一块新的连续内存空间,还可能引发连锁更新问题
为了解决上述问题,Redis中设计了quicklist和listpack数据结构,本小节说明quicklist。
quicklist结合了链表和ziplist各自的优势,定义如下,可看到quicklist本身是一个链表,每个链表节点又是一个ziplist(或者说包含一个ziplist)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
// redis/src/quicklist.h
// quicklist定义
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
// 所有ziplist中的总元素个数
unsigned long count; /* total count of all entries in all ziplists */
// quicklistNodes的个数
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
// quicklist中的节点定义
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
// quicklistNode指向的ziplist
unsigned char *zl;
// ziplist的字节大小
unsigned int sz; /* ziplist size in bytes */
// ziplist中的元素个数
unsigned int count : 16; /* count of items in ziplist */
// 编码格式,原生字节数组或压缩存储
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
// 操作
quicklist *quicklistCreate(void);
quicklist *quicklistNew(int fill, int compress);
...
int quicklistPushHead(quicklist *quicklist, void *value, const size_t sz);
int quicklistPushTail(quicklist *quicklist, void *value, const size_t sz);
void quicklistPush(quicklist *quicklist, void *value, const size_t sz, int where);
...
当插入一个新的元素时,quicklist首先会检查插入位置的 ziplist 是否能容纳该元素,通过控制每个quicklistNode中ziplist的大小或是元素个数,有效减少了在 ziplist 中新增或修改元素后发生连锁更新的情况,从而提供了更好的访问性能。
4.8. listpack
Redis除了设计quicklist结构来应对ziplist的问题以外,还在 5.0 版本中新增了 listpack 数据结构,用来彻底避免连锁更新。
listpack 也叫紧凑列表,它的特点就是用一块连续的内存空间来紧凑地保存数据,同时为了节省内存空间,listpack列表项(entry)使用了多种编码方式,来表示不同长度的数据,这些数据包括整数和字符串。
listpack没有专门的新数据结构定义,通过创建函数lpNew了解下其组织结构:
1
2
3
4
5
6
7
8
9
10
11
// redis/src/listpack.c
unsigned char *lpNew(void) {
// 分配LP_HRD_SIZE+1
unsigned char *lp = lp_malloc(LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
// 设置listpack的大小
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
操作:
1
2
3
4
5
6
7
8
9
// redis/src/listpack.h
unsigned char *lpNew(void);
void lpFree(unsigned char *lp);
unsigned char *lpInsert(unsigned char *lp, unsigned char *ele, uint32_t size, unsigned char *p, int where, unsigned char **newp);
unsigned char *lpAppend(unsigned char *lp, unsigned char *ele, uint32_t size);
unsigned char *lpDelete(unsigned char *lp, unsigned char *p, unsigned char **newp);
uint32_t lpLength(unsigned char *lp);
unsigned char *lpGet(unsigned char *p, int64_t *count, unsigned char *intbuf);
...
5. 小结
梳理说明了Redis支持的数据类型,以及对应的底层数据结构。限于篇幅,相关特性和机制下一篇中进行梳理。