Redis学习实践(三) -- 主从复制和集群
Redis支持的关键特性和机制:主从复制 和 集群。
本篇梳理Redis支持的关键特性和机制:主从复制 和 集群。
1. 背景
继续梳理Redis支持的关键特性和相关机制,主从复制、哨兵集群、切片集群。
Redis的知识点提纲:
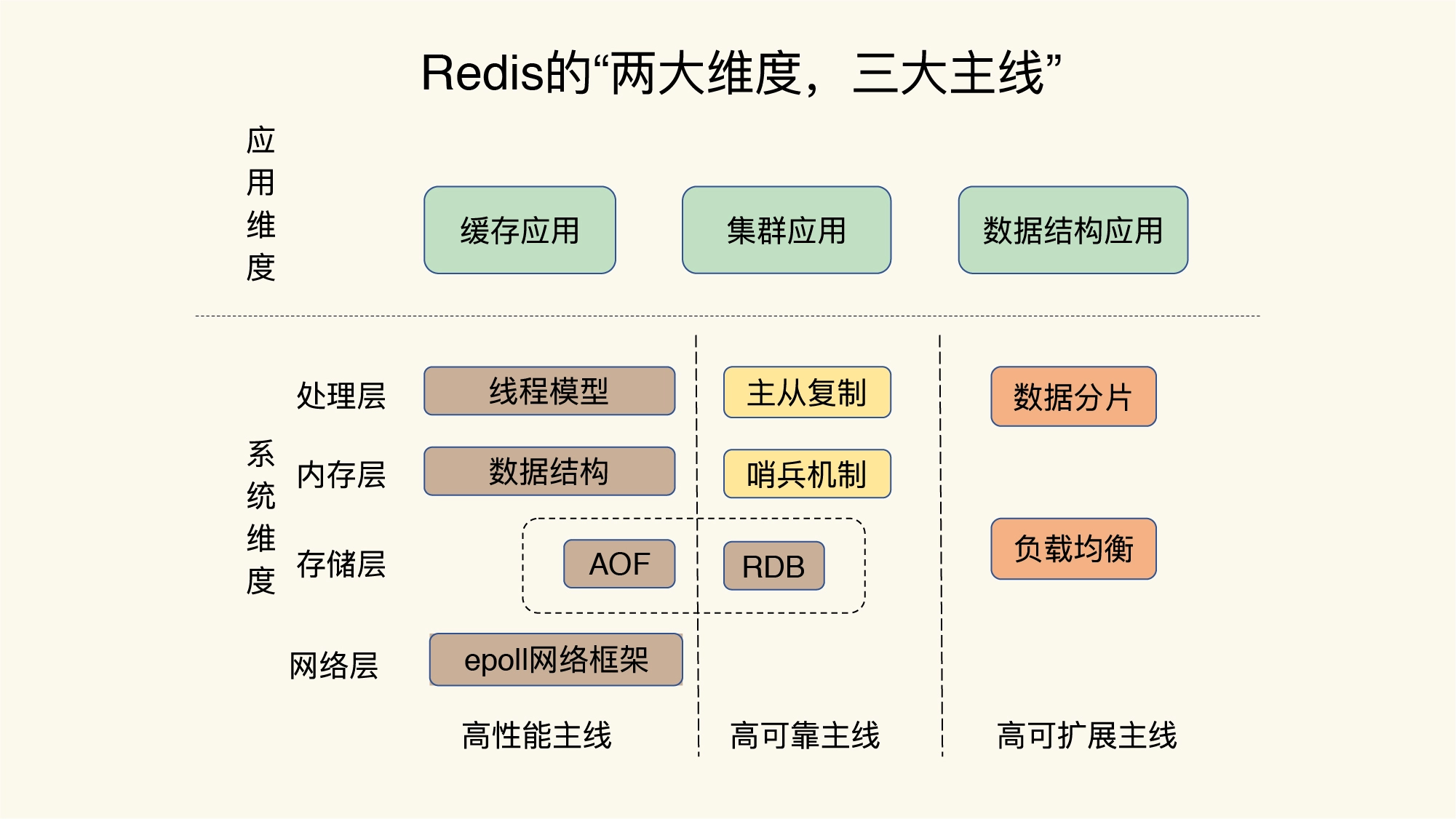
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 主从复制
Redis利用RDB和AOF能够提升单机系统上历史数据的可靠性,但单机异常时,新数据就无法写入了,也无法对外提供服务。该场景下,主从集群能够提升服务可用性。
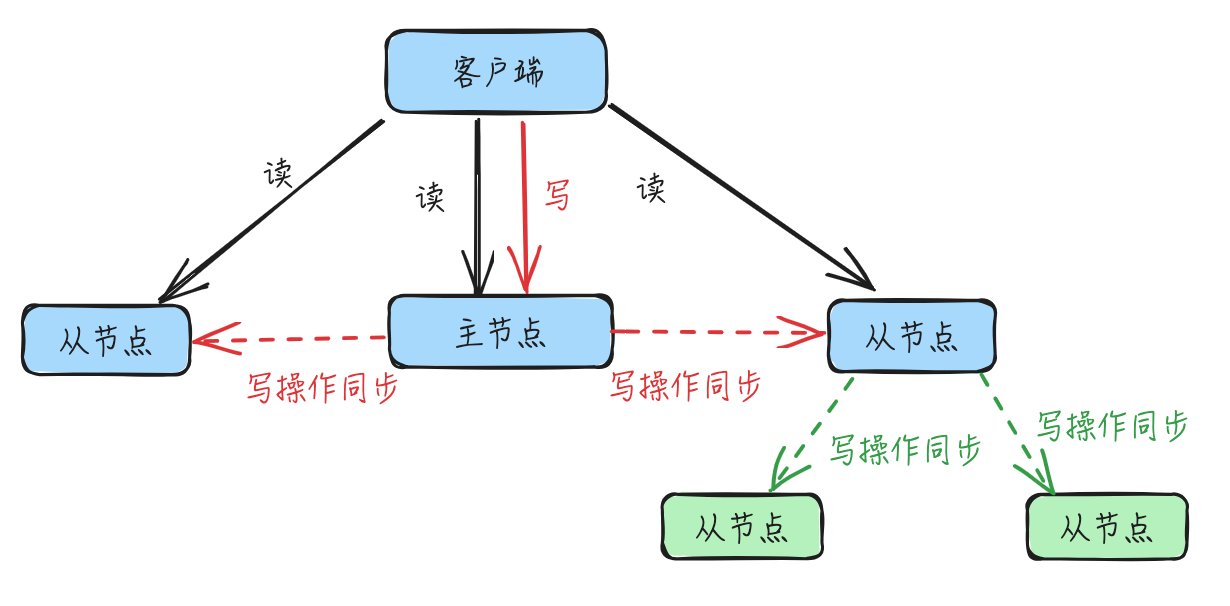
- 主从集群通过增加
副本冗余、使用主从库模式并进行读写分离:只有主节点(或者称主库)负责写操作,主节点和从节点(或者称从库)均可进行读操作; - 主节点和从节点间通过主从复制进行集群数据的同步,主机异常时其中一个从节点能成为新的主节点(哨兵机制)并提供读写服务;
主-从-从模式:从节点也可以有自己的从节点并建立主从级联关系,由该节点而不是主节点负责其从节点的写操作同步,来分担主节点上的全量复制压力- 主节点
fork子进程进行bgsave的RDB文件异步处理,但是数据量多的话fork操作会阻塞主线程 - 全量复制RDB文件,也会给主节点造成网络压力
- 主节点
示意图如下:
2.1. 主从复制流程说明
Redis的主从复制主要包括了:全量复制、增量复制和长连接同步三种情况。
- 全量复制传输 RDB 文件
- 增量复制传输主从断连期间的命令
- 长连接同步则是把主节点正常收到的请求传输给从节点。
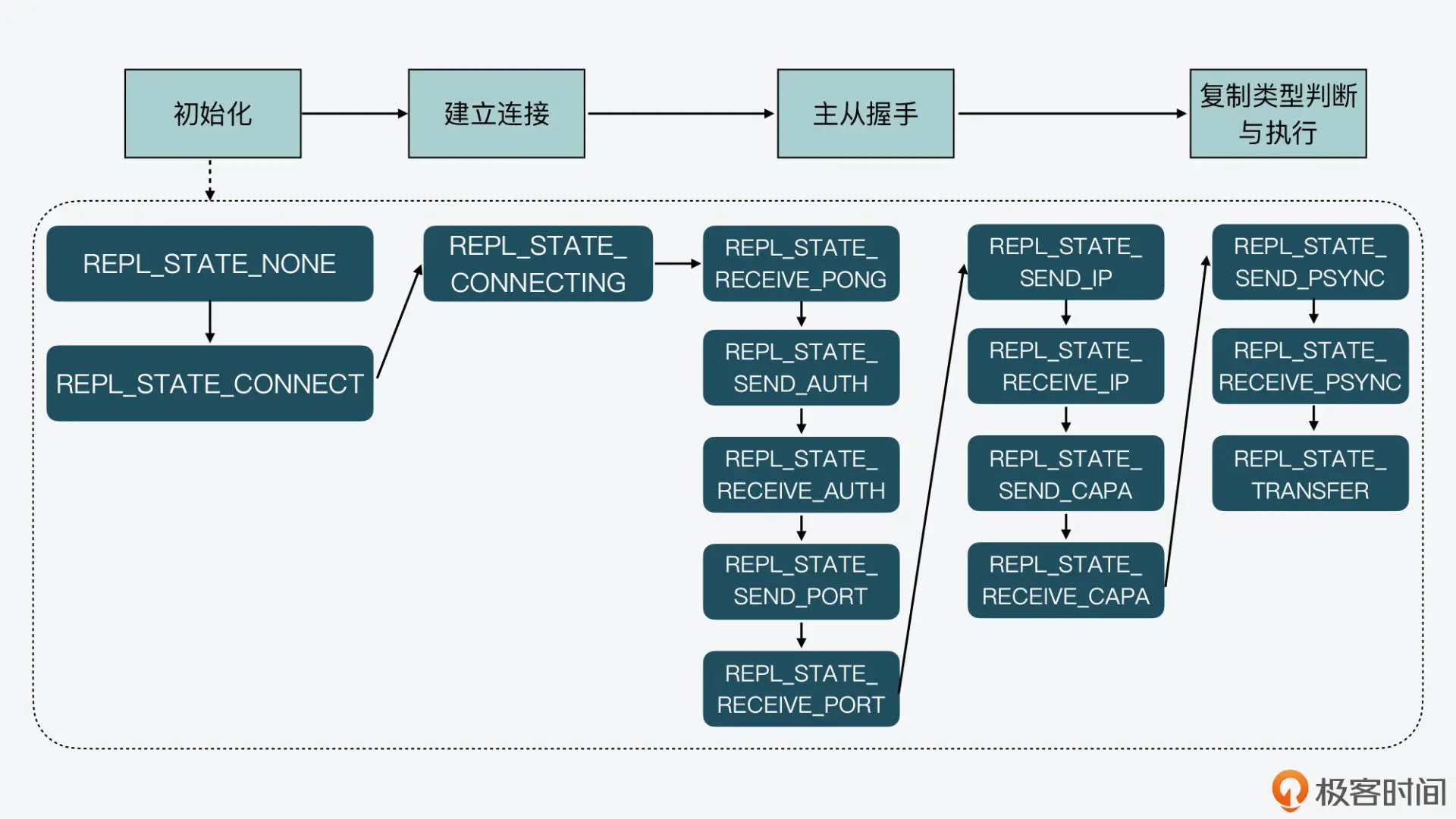
Redis基于状态机实现主从复制,包含四大阶段:
1、初始化阶段
- 当Redis实例 A 设置为另一个实例 B 的从库时,实例 A 会完成初始化操作,主要是获得了主库的 IP 和端口号
- 该阶段有3种方式设置:
- 1)在从节点上(此处即A)执行
replicaof 主库ip 主库port的主从复制命令 - 2)在从节点的redis.conf配置文件中设置
replicaof 主库ip 主库port - 3)从节点启动时,设置启动参数:
--replicaof [主库ip] [主库port]
- 1)在从节点上(此处即A)执行
2、建立连接阶段
- 一旦从库 获得了主库 IP 和端口号,该实例就会尝试和主库建立 TCP 网络连接,并且会在建立好的网络连接上,监听是否有主库发送的命令
3、主从握手阶段
- 当从库(此处的实例A) 和主库建立好连接之后,从库就开始和主库进行握手
- 握手过程就是主从库间相互发送
PING-PONG消息,同时从库根据配置信息向主库进行验证 - 最后,从库把自己的 IP、端口号,以及对
无盘复制和PSYNC 2协议的支持情况发给主库
4、复制类型判断与执行阶段
- 等到主从库之间的握手完成后,从库就会给主库发送
PSYNC命令,有2个参数:主库id(runID)和复制进度(offset)- 发送的命令是:
psync ? -1,第一次不知道主库id,设置为?,-1则表示第一次复制(逻辑在slaveTryPartialResynchronization中) psync(Partial Synchronization),表示部分同步
- 发送的命令是:
- 紧接着,主库会根据从库发送的命令参数作出相应的三种回复,分别是
执行全量复制、执行增量复制、发生错误- 主库收到
psync命令后,会用FULLRESYNC响应命令带上两个参数:主库runID 和主库目前的复制进度 offset,返回给从库FULLRESYNC响应表示第一次复制采用的全量复制
- 主库收到
- 从库在收到上述回复后,就会根据回复的复制类型,开始执行具体的复制操作
- 从库收到响应后,会记录下主库runID和offset
- 主库将所有数据同步给从库:主库执行
bgsave命令,生成RDB文件,接着将文件发给从库。从库接收到RDB文件后,会先清空当前数据库,然后加载RDB文件。
- 最后,主库会把主从同步执行过程中新收到的写命令,再发送给从库
- 对于主从同步过程中的实时请求数据,为了保证主从库的数据一致性,主库会在内存中用专门的
replication buffer,记录RDB文件生成后收到的所有写操作 - 具体操作:当主库完成RDB文件发送后,就会把此时
replication buffer中的修改操作发给从库,从库再重新执行这些操作
- 对于主从同步过程中的实时请求数据,为了保证主从库的数据一致性,主库会在内存中用专门的
上述流程示意图:

2.2. 主从复制实现
上述 主从复制状态机 对应redisServer实例中的 repl_state 变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// redis/src/server.h
struct redisServer {
/* Replication (slave) */
...
// 主库主机名
char *masterhost; /* Hostname of master */
// 主库端口号
int masterport; /* Port of master */
// 超时时间
int repl_timeout; /* Timeout after N seconds of master idle */
// 从库上用来和主库连接的客户端
client *master; /* Client that is master for this slave */
// 从库上缓存的主库信息
client *cached_master; /* Cached master to be reused for PSYNC. */
...
// 从库的复制状态机
int repl_state; /* Replication status if the instance is a slave */
...
};
从库状态机变化,对照上述4个阶段:
1、初始化阶段
- 1)
initServerConfig中,初始化为 REPL_STATE_NONE状态:server.repl_state = REPL_STATE_NONE; - 2)从库执行
replicaof ip port命令后,执行replicaofCommand处理函数 ->replicationSetMaster,其中设置为 REPL_STATE_CONNECT状态
2、建立连接阶段
- 建立连接是在 周期性任务
serverCron中进行的, ->run_with_period(1000) replicationCron();,1s执行一次,用于重连主库 - 上面从库初始化后状态机已经是
REPL_STATE_CONNECT状态了,还未连接,在replicationCron()中会进入connectWithMaster对应语句块,进行主库连接,连接成功后设置状态机为 REPL_STATE_CONNECTING状态,建立连接的阶段就完成了connectWithMaster函数会设置连接成功后的回调函数:syncWithMaster
3、主从握手阶段
- 连接成功时
syncWithMaster回调函数被调用,其中判断状态机为REPL_STATE_CONNECTING的话,会设置状态为 REPL_STATE_RECEIVE_PONG,并通过sendSynchronousCommand函数发送PING消息 - 后面的状态机流转处理,也都在
syncWithMaster函数中,依次会经过 REPL_STATE_SEND_AUTH -> REPL_STATE_SEND_PORT -> REPL_STATE_RECEIVE_PORT -> REPL_STATE_SEND_IP -> REPL_STATE_SEND_CAPA -> REPL_STATE_RECEIVE_CAPA
4、复制类型判断与执行阶段
- 从库和主库完成握手后,从库会读取主库返回的 CAPA 消息响应,状态机为:
REPL_STATE_RECEIVE_CAPA - 紧接着,从库的状态变为 REPL_STATE_SEND_PSYNC,表明要开始向主库发送
PSYNC命令,开始实际的数据同步了。此处的处理还是在syncWithMaster函数中。- 接着通过
slaveTryPartialResynchronization函数向主库发送psync,并将状态机设置为:REPL_STATE_RECEIVE_PSYNC - 接下来还是一个
slaveTryPartialResynchronization处理,里面逻辑也很长,负责根据主库的回复消息分别处理(里面也会接收应答),分别对应了全量复制、增量复制,或是不支持PSYNC
- 接着通过
- 最后是将状态机设置为:REPL_STATE_TRANSFER
跟了下代码,流程还是挺长的,上述状态机变化示意图如下:
上述 psync和replicaof命令:
1
2
3
4
5
6
7
8
9
10
11
12
// redis/src/server.c
struct redisCommand redisCommandTable[] = {
...
{"psync",syncCommand,3,
"admin no-script",
0,NULL,0,0,0,0,0,0},
...
{"replicaof",replicaofCommand,3,
"admin no-script ok-stale",
0,NULL,0,0,0,0,0,0},
...
};
看下syncCommand的调用栈,最后调用到startBgsaveForReplication进行bgsave操作:
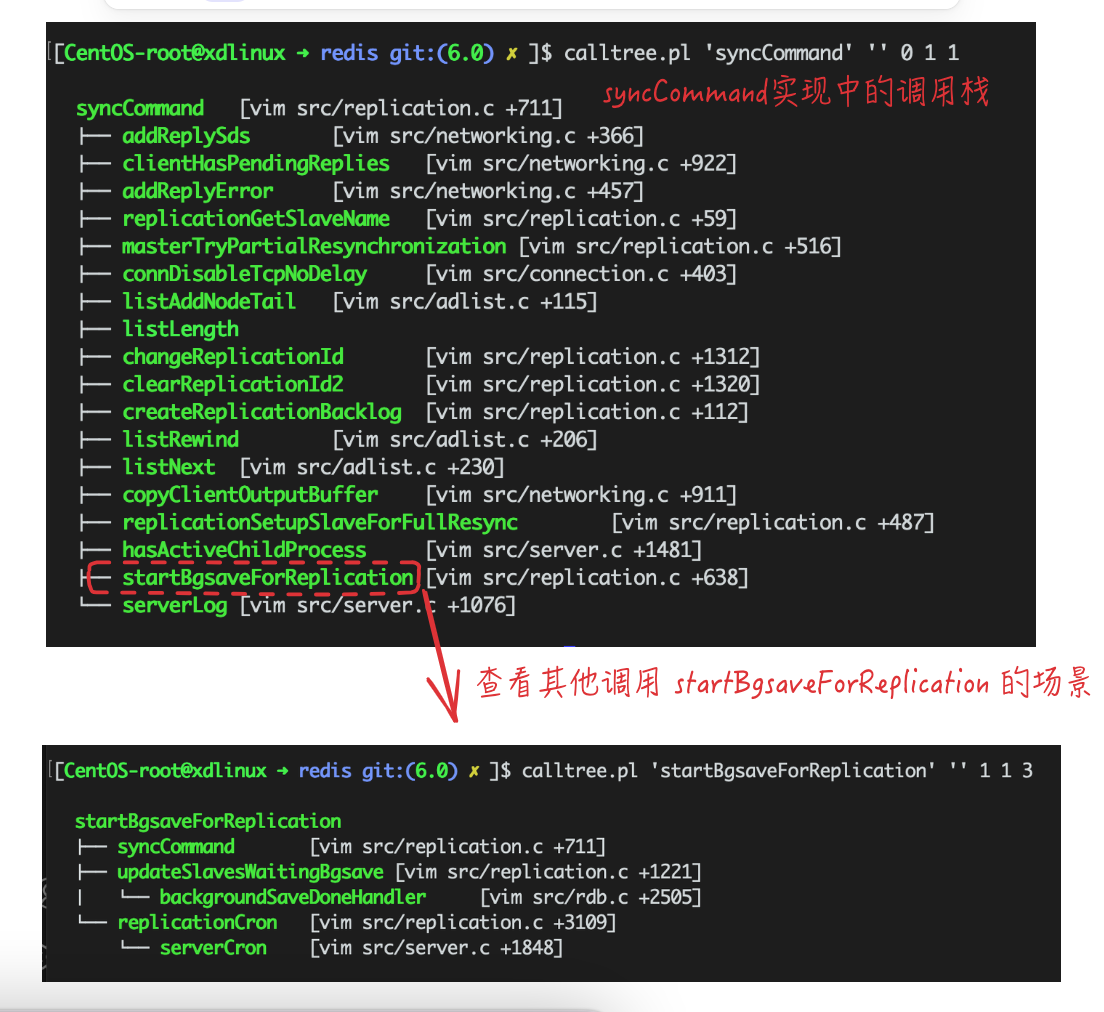
也可看到其他调用到startBgsaveForReplication的场景,比如serverCron定期处理中就会进行bgsave的判断操作。
这里推荐下 calltree.pl 工具,作者在该文章中做了介绍。
试了下很好用,有点像用户态的bpftrace+funcgraph,可以通过mode:0还是1控制查看的调用栈方向。自己也归档了一下并贴了使用结果:cpp-calltree。
上述slaveTryPartialResynchronization函数中,从库发送psync命令并根据应答判断处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// redis/src/replication.c
int slaveTryPartialResynchronization(connection *conn, int read_reply) {
...
// 写部分
if (!read_reply) {
server.master_initial_offset = -1;
if (server.cached_master) {
psync_replid = server.cached_master->replid;
snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1);
serverLog(LL_NOTICE,"Trying a partial resynchronization (request %s:%s).", psync_replid, psync_offset);
} else {
serverLog(LL_NOTICE,"Partial resynchronization not possible (no cached master)");
// 第一次发送psync,命令为:`psync ? -1`
psync_replid = "?";
memcpy(psync_offset,"-1",3);
}
reply = sendSynchronousCommand(SYNC_CMD_WRITE,conn,"PSYNC",psync_replid,psync_offset,NULL);
...
return PSYNC_WAIT_REPLY;
}
// 读部分
// 接收应答
reply = sendSynchronousCommand(SYNC_CMD_READ,conn,NULL);
...
// 对应答进行判断处理
// FULLRESYNC 表示主库响应类型为 全量复制
if (!strncmp(reply,"+FULLRESYNC",11)) {
...
}
if (!strncmp(reply,"+CONTINUE",9)) {
...
}
...
}
2.3. 主库应答处理
来看下主库(主节点)应答FULLRESYNC(告知从库类型为全量复制)的处理逻辑,可以搜索看到处理函数为replicationSetupSlaveForFullResync
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// redis/src/replication.c
int replicationSetupSlaveForFullResync(client *slave, long long offset) {
char buf[128];
int buflen;
slave->psync_initial_offset = offset;
slave->replstate = SLAVE_STATE_WAIT_BGSAVE_END;
server.slaveseldb = -1;
if (!(slave->flags & CLIENT_PRE_PSYNC)) {
buflen = snprintf(buf,sizeof(buf),"+FULLRESYNC %s %lld\r\n",
server.replid,offset);
if (connWrite(slave->conn,buf,buflen) != buflen) {
freeClientAsync(slave);
return C_ERR;
}
}
return C_OK;
}
调用链如下,展开看一下比较直观,后续再跟踪流程:
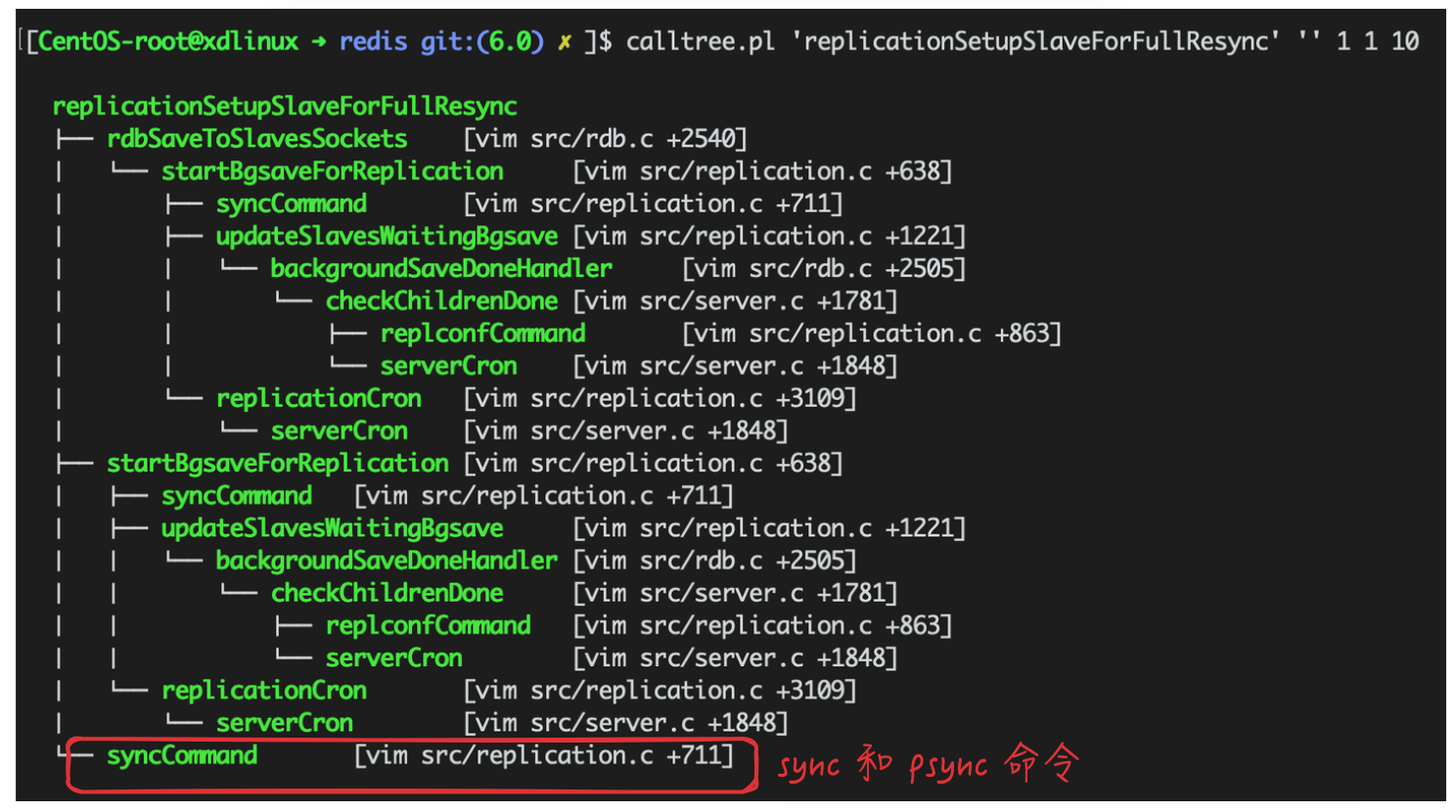
文本也贴一下,便于检索:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
[CentOS-root@xdlinux ➜ redis git:(6.0) ✗ ]$ calltree.pl 'replicationSetupSlaveForFullResync' '' 1 1 10
replicationSetupSlaveForFullResync
├── rdbSaveToSlavesSockets [vim src/rdb.c +2540]
│ └── startBgsaveForReplication [vim src/replication.c +638]
│ ├── syncCommand [vim src/replication.c +711]
│ ├── updateSlavesWaitingBgsave [vim src/replication.c +1221]
│ │ └── backgroundSaveDoneHandler [vim src/rdb.c +2505]
│ │ └── checkChildrenDone [vim src/server.c +1781]
│ │ ├── replconfCommand [vim src/replication.c +863]
│ │ └── serverCron [vim src/server.c +1848]
│ └── replicationCron [vim src/replication.c +3109]
│ └── serverCron [vim src/server.c +1848]
├── startBgsaveForReplication [vim src/replication.c +638]
│ ├── syncCommand [vim src/replication.c +711]
│ ├── updateSlavesWaitingBgsave [vim src/replication.c +1221]
│ │ └── backgroundSaveDoneHandler [vim src/rdb.c +2505]
│ │ └── checkChildrenDone [vim src/server.c +1781]
│ │ ├── replconfCommand [vim src/replication.c +863]
│ │ └── serverCron [vim src/server.c +1848]
│ └── replicationCron [vim src/replication.c +3109]
│ └── serverCron [vim src/server.c +1848]
└── syncCommand [vim src/replication.c +711]
主库上最新的写操作位置:master_repl_offset
1
2
3
4
5
6
7
8
9
10
11
// redis/src/server.h
struct redisServer {
...
/* Replication (master) */
char replid[CONFIG_RUN_ID_SIZE+1]; /* My current replication ID. */
char replid2[CONFIG_RUN_ID_SIZE+1]; /* replid inherited from master*/
// 记录当前的最新写操作在 repl_backlog_buffer 中的位置
long long master_repl_offset; /* My current replication offset */
long long second_replid_offset; /* Accept offsets up to this for replid2. */
...
};
3. 哨兵机制和Raft选举
在Redis主从集群中,哨兵机制是实现主从库自动切换的关键机制,它有效地解决了主从复制模式下故障转移的问题。
哨兵其实就是一个运行在特殊模式下的 Redis 进程,主从库实例运行的同时,它也在运行,不提供读写业务。
哨兵主要负责的就是三个任务:监控、选主(选择主库)和通知。
监控:是指哨兵进程在运行时,周期性地给所有的主从库发送 PING 命令,检测它们是否仍然在线运行- 如果主库没有在规定时间内响应哨兵的 PING 命令,哨兵就会判定主库下线,然后开始自动切换主库的流程
- 哨兵对主库的下线判断有 “主观下线”(Subjectively Down) 和 “客观下线”(Objectively Down) 两种
- 哨兵发现主库或从库对 PING 命令的响应超时了,那么,哨兵就会先把它标记为
主观下线 客观下线:半数以上(N/2+1)哨兵判断主库为主观下线,避免误判
- 哨兵发现主库或从库对 PING 命令的响应超时了,那么,哨兵就会先把它标记为
选主:主库挂了以后,哨兵就需要从很多个从库里,按照一定的规则选择一个从库实例,把它作为新的主库- 选主时,需要对从库进行
筛选过滤和打分,除了要检查从库的当前在线状态,还要判断它之前的网络连接状态 - 打分规则:从库优先级、从库复制进度 以及 从库ID号
- 可以通过
replica-priority(slave-priority是它的别名,“政治正确”原因,slave相关配置都改了),给不同的从库设置不同优先级,优先级高的得分高 - 跟主库同步程度数据最接近的从库得分高
- 若前两者都相同,则ID号最小的从库得分最高
- 可以通过
- 选主时,需要对从库进行
通知:在执行通知任务时,哨兵会把新主库的连接信息发给其他从库,让它们执行replicaof命令,和新主库建立连接,并进行数据复制。同时,哨兵会把新主库的连接信息通知给客户端,让它们把请求操作发到新主库上。
3.1. 哨兵启动
先来看下哨兵的启动,跟普通的主从库实例有什么不同。main()函数启动时,就会检查是否是哨兵模式:
- 方式1:
./redis-sentinel sentinel.conf方式启动 - 方式2:
./redis-server sentinel.conf --sentinel方式启动
逻辑如下,可看到哨兵模式时会修改支持的命令列表(initSentinel当中),并且不会去加载RDB和AOF文件的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
// redis/src/server.c
int main(int argc, char **argv) {
...
// 检查是否是哨兵模式启动
server.sentinel_mode = checkForSentinelMode(argc,argv);
// 初始化服务配置,里面会把 redisCommandTable 中定义的命令添加到 server.commands 中
initServerConfig();
...
if (server.sentinel_mode) {
// 初始化配置项,默认启动端口是 26379
// #define REDIS_SENTINEL_PORT 26379
initSentinelConfig();
// 哨兵服务初始化
// 其中会清空所有上述新增的redis命令,并设置 sentinelcmds 里的命令到commands
initSentinel();
}
...
// 非哨兵模式
if (!server.sentinel_mode) {
serverLog(LL_WARNING,"Server initialized");
...
moduleLoadFromQueue();
ACLLoadUsersAtStartup();
// 线程初始化
InitServerLast();
// 加载 RDB or AOF 数据到内存
loadDataFromDisk();
...
} else {
InitServerLast();
// 哨兵服务启动
sentinelIsRunning();
if (server.supervised_mode == SUPERVISED_SYSTEMD) {
redisCommunicateSystemd("STATUS=Ready to accept connections\n");
redisCommunicateSystemd("READY=1\n");
}
}
...
redisSetCpuAffinity(server.server_cpulist);
// 调整oom_score_adj,不让系统OOM
setOOMScoreAdj(-1);
// 事件循环
aeMain(server.el);
aeDeleteEventLoop(server.el);
return 0;
}
// 检查是否是以哨兵模式启动
int checkForSentinelMode(int argc, char **argv) {
int j;
// 方式1:./redis-sentinel 方式启动
if (strstr(argv[0],"redis-sentinel") != NULL) return 1;
for (j = 1; j < argc; j++)
// 方式2:./redis-server --sentinel 方式启动
if (!strcmp(argv[j],"--sentinel")) return 1;
return 0;
}
initSentinel()里会清空原来所有命令并添加哨兵相关命令:
- 注意:对于部分和常规Redis服务同名的命令,其对应的处理函数是不同的
- 比如
publish,此处对应sentinelPublishCommand,而普通Redis主从服务的命令处理函数则是publishCommand - 还有
info,此处sentinelInfoCommand,而主从服务是infoCommand - 通过
./redis-cli -p 26379连接哨兵实例时,执行info就能体现不同的结果了(相对于不用-p指定端口,默认用6379连接)
- 比如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// redis/src/sentinel.c
struct redisCommand sentinelcmds[] = {
{"ping",pingCommand,1,"",0,NULL,0,0,0,0,0},
{"sentinel",sentinelCommand,-2,"",0,NULL,0,0,0,0,0},
{"subscribe",subscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"unsubscribe",unsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"psubscribe",psubscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"punsubscribe",punsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"publish",sentinelPublishCommand,3,"",0,NULL,0,0,0,0,0},
{"info",sentinelInfoCommand,-1,"",0,NULL,0,0,0,0,0},
{"role",sentinelRoleCommand,1,"ok-loading",0,NULL,0,0,0,0,0},
{"client",clientCommand,-2,"read-only no-script",0,NULL,0,0,0,0,0},
{"shutdown",shutdownCommand,-1,"",0,NULL,0,0,0,0,0},
{"auth",authCommand,2,"no-auth no-script ok-loading ok-stale fast",0,NULL,0,0,0,0,0},
{"hello",helloCommand,-2,"no-auth no-script fast",0,NULL,0,0,0,0,0}
};
void initSentinel(void) {
unsigned int j;
/* Remove usual Redis commands from the command table, then just add
* the SENTINEL command. */
// 清空所有的常规redis命令
dictEmpty(server.commands,NULL);
for (j = 0; j < sizeof(sentinelcmds)/sizeof(sentinelcmds[0]); j++) {
int retval;
struct redisCommand *cmd = sentinelcmds+j;
// 添加 sentinelcmds 里的命令到commands
retval = dictAdd(server.commands, sdsnew(cmd->name), cmd);
...
}
/* Initialize various data structures. */
sentinel.current_epoch = 0;
sentinel.masters = dictCreate(&instancesDictType,NULL);
...
}
sentinelIsRunning中则会向每个被监听的主节点发送事件信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// redis/src/sentinel.c
void sentinelIsRunning(void) {
...
// 向每个被监听的主节点发送事件信息
sentinelGenerateInitialMonitorEvents();
}
void sentinelGenerateInitialMonitorEvents(void) {
dictIterator *di;
dictEntry *de;
di = dictGetIterator(sentinel.masters);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
// 发送事件,通过下面的日志,可看到发送的事件信息:+monitor master mymaster 127.0.0.1 6380 quorum 2
sentinelEvent(LL_WARNING,"+monitor",ri,"%@ quorum %d",ri->quorum);
}
dictReleaseIterator(di);
}
启动示例如下,可同时指定日志等级,下面配置文件中redis的端口都改成了6380:
- 其中
+reboot master mymaster 127.0.0.1 6380是重启了redis-server后,哨兵感知到之后发送的事件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 通过 ./redis-sentinel ../sentinel.conf 方式启动也和下面一样
[CentOS-root@xdlinux ➜ src git:(6.0) ✗ ]$ ./redis-sentinel ../sentinel.conf --loglevel verbose
11292:X 01 Apr 2025 18:05:57.251 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
11292:X 01 Apr 2025 18:05:57.251 # Redis version=6.0.20, bits=64, commit=de0d9632, modified=0, pid=11292, just started
11292:X 01 Apr 2025 18:05:57.251 # Configuration loaded
11292:X 01 Apr 2025 18:05:57.252 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 6.0.20 (de0d9632/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 11292
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
11292:X 01 Apr 2025 18:05:57.252 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
11292:X 01 Apr 2025 18:05:57.252 # Sentinel ID is bc3daf508b4407953522a5455aa470a80e056cd5
11292:X 01 Apr 2025 18:05:57.252 # +monitor master mymaster 127.0.0.1 6380 quorum 2
11292:X 01 Apr 2025 18:06:17.365 * +reboot master mymaster 127.0.0.1 6380
3.2. pub/sub机制的哨兵集群和客户端通知
1、哨兵之间通过 发布/订阅(pub/sub)机制 进行相互发现,哨兵向主库的__sentinel__:hello频道进行publish和subscribe命令操作,发布自己的ip和端口。
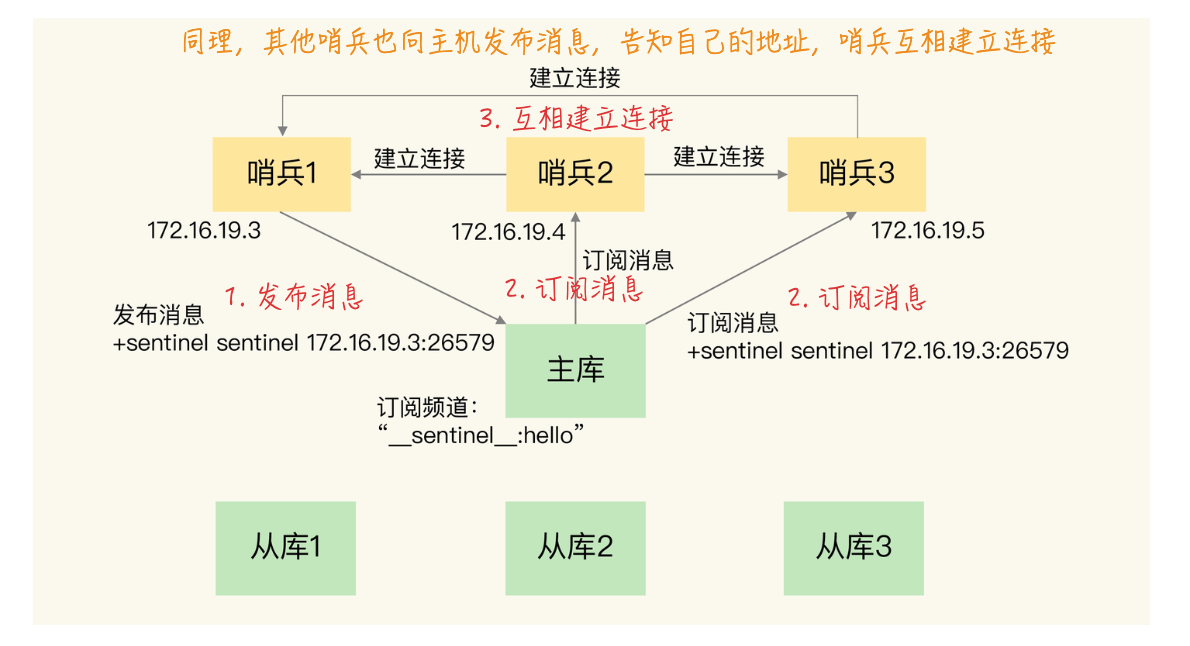
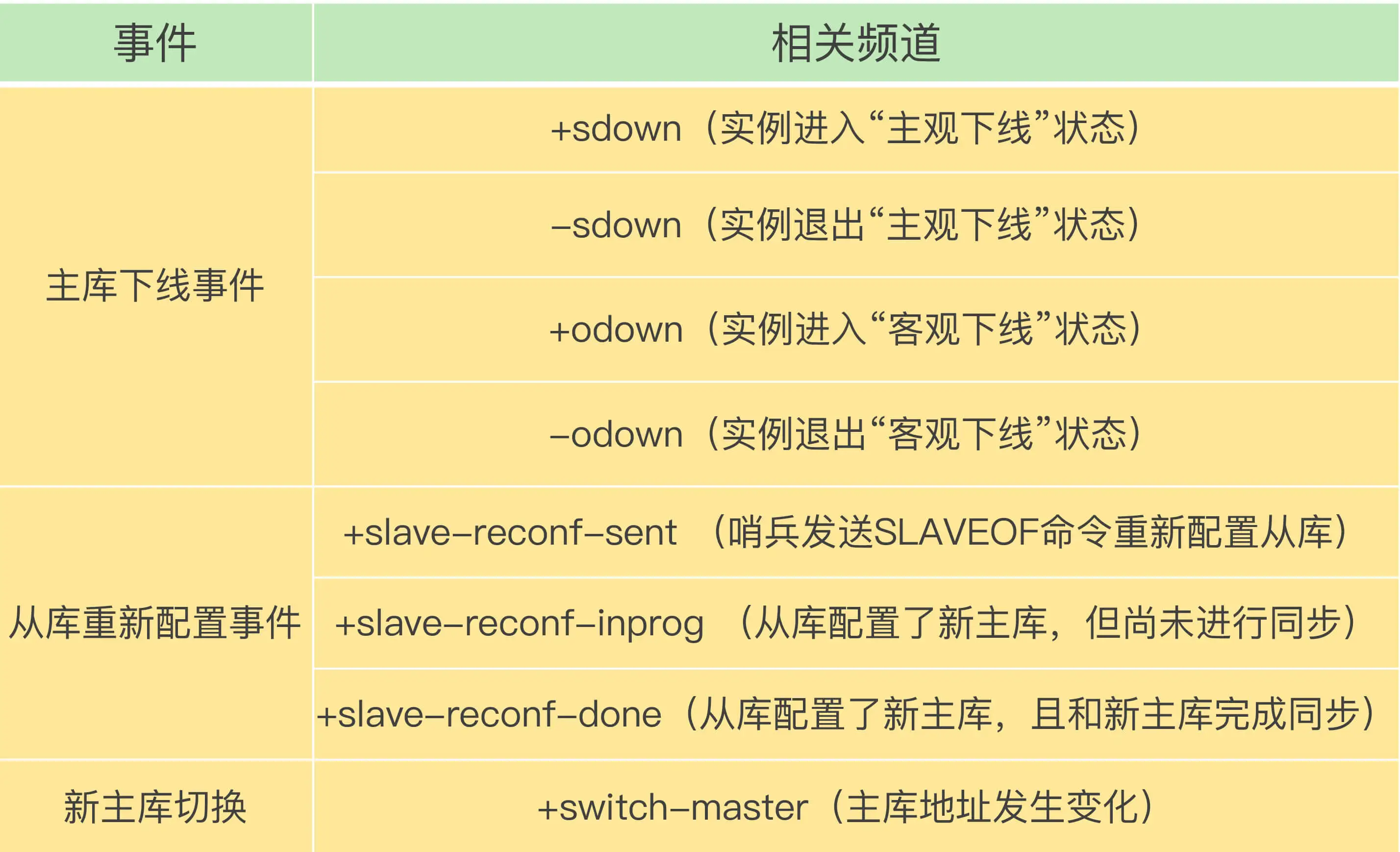
2、每个哨兵实例也提供pub/sub机制,客户端可以从哨兵订阅消息。哨兵提供的消息订阅频道有很多,不同频道包含了主从库切换过程中的不同关键事件,比如实例进入主观下线、实例退出主观下线、主库地址发生变化等。
- 示例:订阅“所有实例进入客观下线状态的事件”:
SUBSCRIBE +odown、订阅所有的事件:PSUBSCRIBE *
几个重要频道:
出处
向__sentinel__:hello频道发布订阅相关代码在 sentinel.c 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// redis/src/sentinel.c
#define SENTINEL_HELLO_CHANNEL "__sentinel__:hello"
// 向 __sentinel__:hello 频道发布本哨兵的信息
int sentinelSendHello(sentinelRedisInstance *ri) {
...
// announce_ip、announce_port:当前哨兵ip和端口
// master_addr->ip、master_addr->port:主库ip和端口
snprintf(payload,sizeof(payload),
"%s,%d,%s,%llu," /* Info about this sentinel. */
"%s,%s,%d,%llu", /* Info about current master. */
announce_ip, announce_port, sentinel.myid,
(unsigned long long) sentinel.current_epoch,
/* --- */
master->name,master_addr->ip,master_addr->port,
(unsigned long long) master->config_epoch);
// 异步 PUBLISH 命令,发布信息
retval = redisAsyncCommand(ri->link->cc,
sentinelPublishReplyCallback, ri, "%s %s %s",
sentinelInstanceMapCommand(ri,"PUBLISH"),
SENTINEL_HELLO_CHANNEL,payload);
if (retval != C_OK) return C_ERR;
ri->link->pending_commands++;
return C_OK;
}
// 订阅 __sentinel__:hello 频道
void sentinelReconnectInstance(sentinelRedisInstance *ri) {
...
retval = redisAsyncCommand(link->pc,
sentinelReceiveHelloMessages, ri, "%s %s",
sentinelInstanceMapCommand(ri,"SUBSCRIBE"),
SENTINEL_HELLO_CHANNEL);
...
}
__sentinel__:hello频道的发布事件逻辑在sentinelSendHello中,对应的发布消息的调用时机,是在serverCron定时器回调函数当中:
1
2
3
4
5
6
7
8
[CentOS-root@xdlinux ➜ redis git:(6.0) ✗ ]$ calltree.pl 'sentinelSendHello' '' 1 1 10
sentinelSendHello
└── sentinelSendPeriodicCommands [vim src/sentinel.c +2720]
└── sentinelHandleRedisInstance [vim src/sentinel.c +4480]
└── sentinelHandleDictOfRedisInstances [vim src/sentinel.c +4516]
└── sentinelTimer [vim src/sentinel.c +4571]
└── serverCron [vim src/server.c +1848]
sentinelReconnectInstance订阅__sentinel__:hello频道的调用时机,也在serverCron定时器回调函数中:
1
2
3
4
5
6
7
[CentOS-root@xdlinux ➜ redis git:(6.0) ✗ ]$ calltree.pl 'sentinelReconnectInstance' '' 1 1 10
sentinelReconnectInstance
└── sentinelHandleRedisInstance [vim src/sentinel.c +4480]
└── sentinelHandleDictOfRedisInstances [vim src/sentinel.c +4516]
└── sentinelTimer [vim src/sentinel.c +4571]
└── serverCron [vim src/server.c +1848]
3.3. 哨兵Leader选举
当有多个哨兵判断出主节点故障后:
- 1、哨兵集群会判断主库是否客观下线,若是则哨兵按照上述
选主打分规则,从多个从库中选举出一个新主库 - 2、哨兵集群间也会选举出一个哨兵Leader,负责主库的切换
quorum参数表示能判断主库客观下线的最小哨兵实例数量;选主及切换主库,则需要满足总节点半数以上(N/2+1)。比如,有5个哨兵实例的Redis集群,quorum设置为2,若3个哨兵实例故障,则主库宕机异常时,可以正常判断主库客观下线,但是不满足半数(3)节点,所以无法选出新主库。
哨兵Leader选举并没有完全按照 Raft 协议来实现。Raft选举相关论文学习,之前在 MIT6.824学习笔记(四) – Raft 中也学习过了,下面简单回顾并对比。
- Raft中:有
领导人(Leader)、跟随者(Follower)和候选人(Candidate)3种角色,通过定期心跳机制来 维持Leader的权威 和 触发Leader选举。在Leader异常时,Follower增加自己的任期号并切换为Candidate,并行地发起投票请求,当收到本任期号中半数以上选票则选举成功,成为新Leader,其他节点则承认新Leader并回到Follower状态。 - Redis中:主节点正常运行过程中,哨兵之间的角色是对等的,只有哨兵发现主节点故障了,哨兵才按照
Raft协议执行选举Leader的过程。
哨兵的选举过程是在 sentinelTimer 中实现的(包含在上述__sentinel__:hello频道的发布订阅调用栈中)。
主要调用逻辑是 sentinelTimer -> sentinelHandleDictOfRedisInstances(sentinel.masters)(传入的哈希表表示哨兵监听的主从节点) -> 遍历每个监听的节点并处理:sentinelHandleRedisInstance(ri)。里面会判断主观、客观下线,触发故障切换等,下面是函数流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// redis/src/sentinel.c
void sentinelHandleRedisInstance(sentinelRedisInstance *ri) {
// 1、尝试和断连的实例重新建立连接
sentinelReconnectInstance(ri);
// 2、向实例发送 PING、INFO、PUBLISH 等命令
sentinelSendPeriodicCommands(ri);
...
// 3、检查监听的实例是否主观下线
sentinelCheckSubjectivelyDown(ri);
/* Masters and slaves */
if (ri->flags & (SRI_MASTER|SRI_SLAVE)) {
/* Nothing so far. */
}
/* Only masters */
// 4、针对监听的主节点,进行客观下线检查判断及故障切换等操作
if (ri->flags & SRI_MASTER) {
// 4.1、针对监听的主节点,检查其是否客观下线
sentinelCheckObjectivelyDown(ri);
// 4.2、判断是否要启动故障切换
if (sentinelStartFailoverIfNeeded(ri))
// 若需要切换,则获取其他哨兵实例对主节点状态的判断,并向其他哨兵发送 is-master-down-by-addr 命令,发起 Leader 选举
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED);
// 4.3、执行故障切换
sentinelFailoverStateMachine(ri);
// 4.4、再次获取其他哨兵实例对主节点状态的判断
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS);
}
}
向其他哨兵实例获取主节点状态判断的完整命令,形式如:sentinel is-master-down-by-addr 主节点IP 主节点端口 当前epoch 实例ID,所有sentinel开头的命令,都是在 sentinelCommand 函数中处理的。
哨兵会使用sentinelRedisInstance结构体来记录主节点的信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// redis/src/sentinel.c
typedef struct sentinelRedisInstance {
// 记录哨兵对主节点主观下线的判断结果
int flags; /* See SRI_... defines */
char *name; /* Master name from the point of view of this sentinel. */
char *runid; /* Run ID of this instance, or unique ID if is a Sentinel.*/
...
// 记录了哨兵和主节点间的两个连接,分别对应用来发送命令的连接 cc 和用来发送 Pub/Sub 消息的连接 pc
instanceLink *link; /* Link to the instance, may be shared for Sentinels. */
...
// 保存了监听同一主节点的其他哨兵实例
dict *sentinels; /* Other sentinels monitoring the same master. */
// 判断主节点为客观下线需要的哨兵数量
unsigned int quorum;/* Number of sentinels that need to agree on failure. */
...
// 哨兵对Leader投票的结果,leaderID
char *leader;
// 哨兵对Leader投票的结果,leader纪元
uint64_t leader_epoch; /* Epoch of the 'leader' field. */
// 记录故障切换的状态
int failover_state; /* See SENTINEL_FAILOVER_STATE_* defines. */
...
} sentinelRedisInstance;
获取其他哨兵的主节点状态判断和选举投票结果后,哨兵Leader选举的条件判断:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// redis/src/sentinel.c
char *sentinelGetLeader(sentinelRedisInstance *master, uint64_t epoch) {
...
// voters 是所有哨兵的个数,max_votes 是获得的票数
// 赞成票的数量必须是超过半数以上的哨兵个数
voters_quorum = voters/2+1;
// 如果赞成票数不到半数的哨兵个数或者少于quorum阈值,那么Leader就为NULL
if (winner && (max_votes < voters_quorum || max_votes < master->quorum))
winner = NULL;
// 确定最终的Leader
winner = winner ? sdsnew(winner) : NULL;
...
return winner;
}
对应的调用流程:
1
2
3
4
5
6
7
[CentOS-root@xdlinux ➜ redis git:(6.0) ✗ ]$ calltree.pl 'sentinelGetLeader' '' 1 1 6
sentinelGetLeader
└── sentinelFailoverWaitStart [vim src/sentinel.c +4205]
└── sentinelFailoverStateMachine [vim src/sentinel.c +4432]
└── sentinelHandleRedisInstance [vim src/sentinel.c +4480]
└── sentinelHandleDictOfRedisInstances [vim src/sentinel.c +4516]
└── sentinelTimer [vim src/sentinel.c +4571]
上述具体内部流程暂不做展开,后续按需深入。先跟着参考文章走读代码流程并注释:redis 6.0。
4. 切片集群
当需要Redis保存大量数据时,一种方式是纵向扩展:增加服务器规格配置,比如增加内存容量、增加磁盘容量、使用更高配置的CPU。但是RDB进行持久化时,Redis会fork子进程来完成,在执行时会阻塞主线程,数据量越大,fork操作造成的主线程阻塞的时间越长。
另一种方式是横向扩展:切片集群。切片集群也叫分片集群,是指启动多个Redis实例组成一个集群,然后按照一定的规则,把收到的数据划分成多份,每一份用一个实例来保存。
切片集群是一种保存大量数据的通用机制,这个机制可以有不同的实现方案。根据路由规则所在位置的不同,可以分为 客户端分片 和 服务端分片。
- 客户端分片指的是,key的路由规则放在客户端中
- 缺点是客户端需要维护这个路由规则,耦合在业务代码中
Redis Cluster把这个路由规则封装成了一个模块,当需要使用时集成这个模块即可。Redis Cluster内置了哨兵逻辑,无需再部署哨兵
- 服务端分片指:路由规则不放在客户端,而是在客户端和服务端之间增加一个
中间代理层,即Proxy,数据的路由规则就放在这个Proxy层来维护- Proxy会把客户端请求根据路由规则,转发到对应的Redis节点,Redis集群还可横向扩容,这对于客户端来说都是透明无感知的
Twemproxy、Codis就是采用的这种方案
这里简单介绍下 Redis Cluster 方案:
- 采用
哈希槽(Hash Slot)来处理数据和实例之间的映射关系。 - 在 Redis Cluster 方案中,一个切片集群共有
16384个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。- 哈希方式:
CRC16(key) % 16384
- 哈希方式:
- 一致性协议采用:
gossip协议 - 简单测试
- 启动Redis实例:
redis-server启动6个不同的端口Redis实例,启用cluster-enabled yes - 创建集群:
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
- 启动Redis实例:
相关定义:
1
2
3
4
5
6
7
8
9
10
11
// redis/src/server.h
struct redisServer {
...
/* Cluster */
int cluster_enabled; /* Is cluster enabled? */
mstime_t cluster_node_timeout; /* Cluster node timeout. */
char *cluster_configfile; /* Cluster auto-generated config file name. */
// 集群
struct clusterState *cluster; /* State of the cluster */
...
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// redis/src/cluster.h
#define CLUSTER_SLOTS 16384
// 每个集群节点对应一个 clusterNode
typedef struct clusterNode {
...
// 位图(bitmap),标记该节点负责哪些slots
unsigned char slots[CLUSTER_SLOTS/8]; /* slots handled by this node */
...
} clusterNode;
// 整个集群结构
typedef struct clusterState {
...
int size; /* Num of master nodes with at least one slot */
dict *nodes; /* Hash table of name -> clusterNode structures */
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
// 当前节点负责的 slot 正在迁往哪个节点
clusterNode *migrating_slots_to[CLUSTER_SLOTS];
// 当前节点正在从哪个节点迁入某个 slot
clusterNode *importing_slots_from[CLUSTER_SLOTS];
// 16384 个 slot 分别是由哪个节点负责的
clusterNode *slots[CLUSTER_SLOTS];
// 每个slot存储的key数量
uint64_t slots_keys_count[CLUSTER_SLOTS];
// rax字典树,记录 slot 和 key 的对应关系,可以通过它快速找到 slot 上有哪些 keys
rax *slots_to_keys;
...
} clusterState;
相关接口:
1
2
3
4
5
6
7
// redis/src/cluster.c
clusterNode *createClusterNode(char *nodename, int flags);
int clusterAddNode(clusterNode *node);
void clusterAcceptHandler(aeEventLoop *el, int fd, void *privdata, int mask);
void clusterReadHandler(connection *conn);
void clusterSendPing(clusterLink *link, int type);
...
此外还可了解:PikiwiDB(Pika),是360基础架构开源的键值数据库,基于SSD来实现大容量的Redis实例(兼容Redis),2023年更名为PikiwiDB。整体架构中包括了五部分,分别是网络框架、Pika 线程模块、Nemo 存储模块、RocksDB 和 binlog机制。
5. 小结
梳理Redis的主从复制 和 哨兵集群、切片集群相关流程。