CPU及内存调度(四) -- ptmalloc、tcmalloc、jemalloc、mimalloc内存分配器(上)
梳理 ptmalloc、tcmalloc、jemalloc 和 mimalloc 内存分配器,本篇先梳理ptmalloc。
梳理 ptmalloc、tcmalloc、jemalloc 和 mimalloc 内存分配器,本篇先梳理ptmalloc。
1. 背景
CPU及内存调度(二) – Linux内存管理 中梳理学习了Linux的虚拟内存结构,以及进程、线程创建时的大致区别。内存的布局和分配、释放机制,跟程序的性能息息相关,比如内存分配器在多线程场景下的锁竞争、brk/mmap不同场景下的使用、什么场景会延迟升高、内存碎片等。
程序调用malloc/free函数申请和释放内存,内存分配器则提供对内存的集中管理。理解所用内存分配器的内在逻辑,在程序设计以及出现内存相关性能瓶颈时,有助于问题理解和根因定位,并进行针对性的性能优化。本篇就来梳理下 ptmalloc、tcmalloc、jemalloc和mimalloc 几个业界常用的内存分配器,了解其内部实现的主要机制。
结合源码和几篇参考文章:
- ptmalloc
- tcmalloc
- jemalloc
- ptmalloc、tcmalloc与jemalloc对比分析
- 内存分配器ptmalloc,jemalloc,tcmalloc调研与对比
2. 总体说明
常见的内存分配器:ptmalloc、tcmalloc、jemalloc、mimalloc。
- ptmalloc 全称是
Posix Thread Malloc,是 GNU C库(glibc)的默认分配器- 多线程环境下的通用内存分配器
- 核心机制
- 使用
arena(分配区),每个线程优先使用独立 arena(数量有限,默认为核心数的 8 倍) - 小对象通过线程本地缓存分配,大对象直接从中央堆分配。
- 通过锁保护
arena,当线程数超过arena数时,竞争导致性能下降
- 使用
- 优点:成熟稳定,与 glibc 深度集成;支持多线程,对小对象分配有一定优化
- 缺点:高并发场景下锁竞争明显,内存碎片较多(尤其是长周期服务)
- 适用于通用场景,对性能要求不极端的中小型应用
- tcmalloc 全称是
Thread-Caching Malloc,由Google开发。- 设计目标:优化多线程性能,减少内存分配延迟
- 核心机制
- 线程本地缓存:每个线程独立缓存小对象(默认 ≤ 256KB),无需锁
- 中央堆管理大对象,采用自旋锁减少竞争
- 定期回收线程缓存中的空闲内存,平衡内存占用
- 优点:高并发下性能优异(尤其小对象频繁分配);内存碎片较少,提供内存分析工具(如 heap profiler)
- 缺点:线程缓存可能占用较多内存(需权衡缓存大小与性能)
- 适用场景:多线程服务、高频小对象分配(如 Web 服务器)
- jemalloc,命名以作者
Jason Evans的名称作缩写,由Facebook(现Meta)开发,后成为 FreeBSD 默认分配器- 设计目标:降低内存碎片,提升多线程和长期运行服务的稳定性
- 核心机制
- 多 arena 分配:每个线程绑定特定 arena,动态扩展 arena 数量减少竞争
- 精细化大小分类:将内存划分为多个 size class,减少内部碎片
- 主动合并空闲内存:延迟重用策略降低外部碎片
- 优点:内存碎片最少,长期运行服务内存利用率高;多线程性能接近 tcmalloc,扩展性强
- 缺点:配置较复杂,默认策略可能不如 tcmalloc 激进
- 适用场景:长期运行的高负载服务(如数据库、实时系统)
- Rust 早期默认 jemalloc,后切换为系统默认的分配器(如 Unix 的 ptmalloc)
- mimalloc,全称是
Microsoft MiMalloc,微软开源的内存分配器- 设计目标:提供高性能的内存分配器,减少内存碎片,并提升多线程环境下的扩展性
- 核心机制
- 分段式内存管理:mimalloc 将堆划分为多个独立的段(segment),每个段可以独立分配和释放,减少锁竞争。
- 局部缓存优化:每个线程维护自己的本地缓存,避免频繁访问全局堆。
- 延迟合并策略:通过延迟释放空闲内存块,减少外部碎片的同时提升分配效率。
- 隔离性与安全性:支持更安全的内存分配模式,防止某些类型的内存错误。
- 优点:高性能、内存利用率高、易于集成
- 缺点:生态系统支持不如 tcmalloc 和 jemalloc 成熟;性能优势在特定场景下可能不如其他分配器明显
- 适用场景:高并发、低延迟的现代服务(如云计算、实时处理系统)
3. ptmalloc
3.1. 历史迭代
历史迭代:glibc的内存分配器ptmalloc,起源于Doug Lea的malloc,或者叫dlmalloc。由Wolfram Gloger改进得到可以支持多线程。(说明:下面篇幅中分别称dlmalloc和ptmalloc,ptmalloc指代当前glibc的版本,也叫ptmalloc2;本篇中glibc代码基于2.28版本,和CentOS8一致)
两位大佬的介绍:
Doug Lea(道格.利)是计算机科学领域的著名专家,尤其在Java并发编程方面贡献卓越。- 他是《Java并发编程实战》(Java Concurrency in Practice)的作者之一,该书被视为并发编程领域的经典
- 他开发了早期的util.concurrent库,后被纳入JDK
- JDK 1.2中的Collections概念部分源于他在1995年发布的早期集合库
- 他曾作为JCP(Java Community Process)个人成员参与Java标准制定
- Doug Lea 的 dlmalloc 是 C/C++ 内存管理领域的基石之一,尽管现在有更现代的内存分配器,但其设计思想仍被广泛借鉴
Wolfram Gloger是一位德国计算机科学家,以其在内存管理和动态内存分配器方面的贡献而闻名- 他对于 Doug Lea 的 dlmalloc 的改进版本:ptmalloc(Per-Thread Malloc),支持多线程环境下的高效内存分配,并被集成到 glibc(GNU C Library)中,成为 Linux 系统默认的 malloc 实现
dlmalloc介绍:A Memory Allocator,代码:malloc.c。自己也归档了一份用于对比学习:dlmalloc_src。
当前glibc(本地fork并切换了2.28版本)的代码注释中,也展示了上述迭代经过。并且说明了为什么用这个版本的malloc:
这并不是有史以来最快、最节省空间、最可移植或最可调优的 malloc 实现。然而,它在速度、空间节省、可移植性和可调优性之间达到了一致的平衡。正因如此,它成为了一个适用于 大量使用malloc程序 的优秀通用分配器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// glibc-2.28/malloc/malloc.c
/*
This is a version (aka ptmalloc2) of malloc/free/realloc written by
Doug Lea and adapted to multiple threads/arenas by Wolfram Gloger.
There have been substantial changes made after the integration into
glibc in all parts of the code. Do not look for much commonality
with the ptmalloc2 version.
* Version ptmalloc2-20011215
based on:
VERSION 2.7.0 Sun Mar 11 14:14:06 2001 Doug Lea (dl at gee)
...
* Why use this malloc?
This is not the fastest, most space-conserving, most portable, or
most tunable malloc ever written. However it is among the fastest
while also being among the most space-conserving, portable and tunable.
Consistent balance across these factors results in a good general-purpose
allocator for malloc-intensive programs.
...
*/
3.2. dlmalloc说明
先简单看一下基础版本的dlmalloc,有助于理解后续的ptmalloc版本的设计思路、解决了什么问题。
代码量也并不多,tokei 统计有 3649 行,calltree.pl 统计只有 2593 行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# tokei
[CentOS-root@xdlinux ➜ dlmalloc_src git:(main) ✗ ]$ tokei -f malloc.c
===============================================================================================
Language Files Lines Code Comments Blanks
===============================================================================================
C 1 6291 3649 2149 493
-----------------------------------------------------------------------------------------------
malloc.c 6291 3649 2149 493
===============================================================================================
Total 1 6291 3649 2149 493
===============================================================================================
# calltree.pl
[CentOS-root@xdlinux ➜ dlmalloc_src git:(main) ]$ calltree.pl main '' 1 1 1
preprocess_all_cpp_files
...
extract lines: 2593
function definition after merge: 90
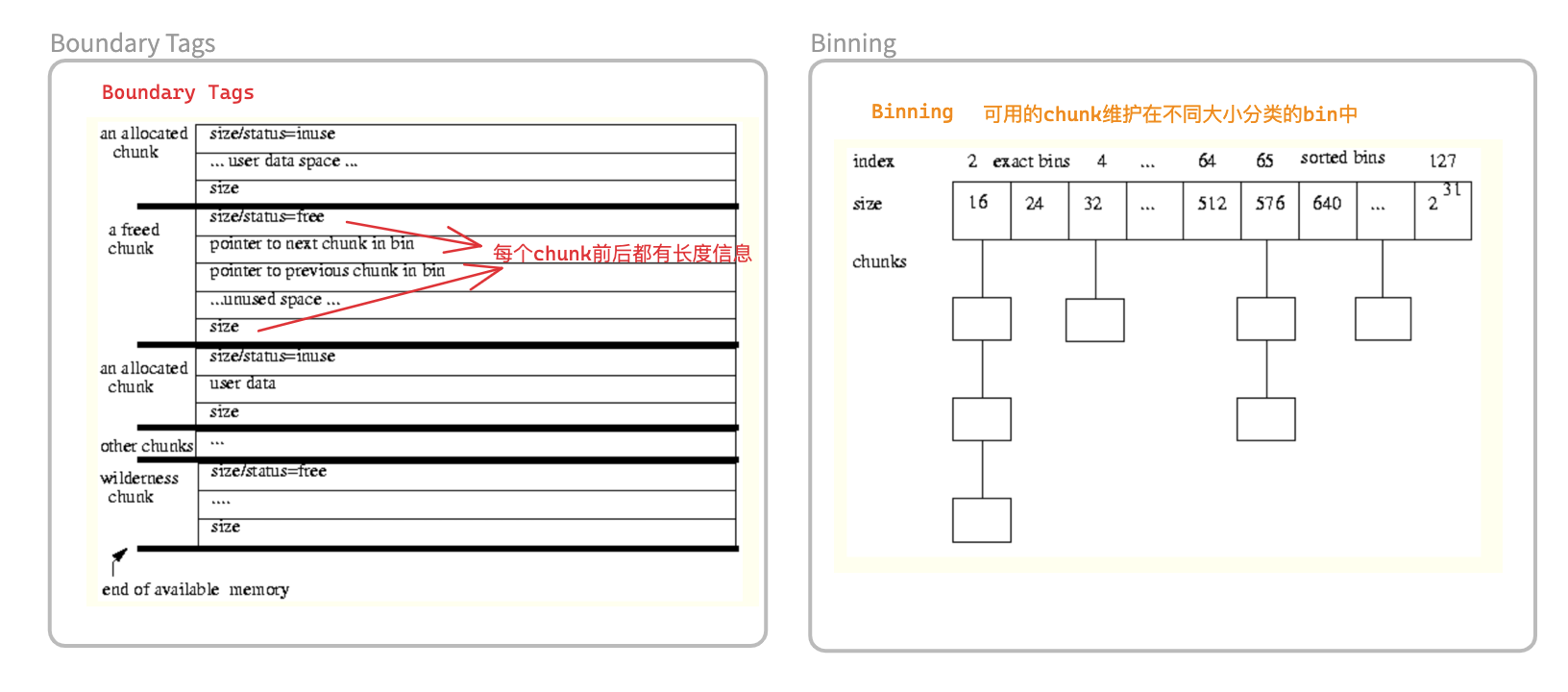
1、Boundary Tags 和 Binning 设计
Boundary Tags和Binning两个核心设计,从dlmalloc的早期版本就一直保留了下来- Boundary Tags:位于每个分配的内存块的头部和尾部,记录内存块的大小和状态(已分配或空闲),从而支持快速的内存合并操作、查找大小操作
- Binning:用于分类管理不同大小的空闲内存块,根据其大小被放入不同的“bin”(桶)中,便于快速查找适合的内存块
- 参考:A Memory Allocator
2、线程安全性:启用加锁,需要编译时指定USE_LOCKS为非0(默认为0-不启用),-DUSE_LOCKS=1
- 另外几个锁相关的宏:
USE_SPIN_LOCKS、USE_RECURSIVE_LOCKS
这里简要梳理下dlmalloc中锁的相关逻辑,其中的兼容性设计、自旋锁实现都值得学习。
锁相关的部分调整了一下缩进:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
// prog-playground/memory/dlmalloc_src/malloc.c
#if USE_LOCKS > 1
// 用户自定义锁
#elif USE_SPIN_LOCKS // 使用自旋锁
// gcc>=4.1版本,CAS锁,使用gcc提供的 __sync_lock_test_and_set,实现原子交换。常用于实现自旋锁(spinlock)或其他轻量级同步机制
#if defined(__GNUC__)&& (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 1))
#define CAS_LOCK(sl) __sync_lock_test_and_set(sl, 1)
#define CLEAR_LOCK(sl) __sync_lock_release(sl)
// 老版本的gcc,则其中自行实现了自旋锁函数
#elif (defined(__GNUC__) && (defined(__i386__) || defined(__x86_64__)))
static FORCEINLINE int x86_cas_lock(int *sl) {
int ret;
int val = 1;
int cmp = 0;
// GCC 的 __asm__ 语法编写的内联汇编代码,用于实现一个原子级的 比较并交换(Compare-And-Swap, CAS) 操作
// 通常用于实现低级别的同步原语,比如锁或原子变量
__asm__ __volatile__ ("lock; cmpxchgl %1, %2" // cmpxchgl:x86 架构中的指令,用于执行比较并交换操作
: "=a" (ret)
: "r" (val), "m" (*(sl)), "0"(cmp)
: "memory", "cc");
return ret;
}
// x86_clear_lock 解锁函数等的实现
...
#define CAS_LOCK(sl) x86_cas_lock(sl)
#define CLEAR_LOCK(sl) x86_clear_lock(sl)
...
// Windows平台的锁(用的是临界区,critical sections)
#else /* Win32 MSC */
...
#endif /* ... gcc spins locks ... */
/* How to yield for a spin lock */
// 定义不同平台使用的 yield 函数(出让时间片)
// 这里只看下非solaris的linux平台,用的是 sched_yield()
#define SPIN_LOCK_YIELD sched_yield();
// 递归锁
// 不使用递归锁的情况
#if !defined(USE_RECURSIVE_LOCKS) || USE_RECURSIVE_LOCKS == 0
...
// 使用递归锁的情况
#else /* USE_RECURSIVE_LOCKS */
// 里面也做了Linux和Windows平台的兼容,还用上述的 自旋锁 来实现递归锁
...
#endif /* USE_RECURSIVE_LOCKS */
// Windows临界区
#elif defined(WIN32) /* Win32 critical sections */
...
// pthread锁
#else /* pthreads-based locks */
// 这里就是常规 pthread_mutex 相关定义和操作了
#define MLOCK_T pthread_mutex_t
#define ACQUIRE_LOCK(lk) pthread_mutex_lock(lk)
#define RELEASE_LOCK(lk) pthread_mutex_unlock(lk)
...
#endif /* ... lock types ... */
接口定义:
1
2
3
4
5
6
7
8
9
10
11
// prog-playground/memory/dlmalloc_src/malloc.c
...
#define dlfree free
#define dlmalloc malloc
#define dlmemalign memalign
#define dlposix_memalign posix_memalign
#define dlrealloc realloc
...
DLMALLOC_EXPORT void* dlmalloc(size_t);
DLMALLOC_EXPORT void dlfree(void*);
...
dlmalloc逻辑,可以看到锁范围还是很大的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void* dlmalloc(size_t bytes) {
#if USE_LOCKS
// 里面会初始化锁
ensure_initialization(); /* initialize in sys_alloc if not using locks */
#endif
// 若启用锁则其中会先加锁
if (!PREACTION(gm)) {
// 具体malloc算法逻辑,此处略
...
postaction:
// 若启用锁,则其中会解锁
POSTACTION(gm);
return mem;
}
}
3.3. ptmalloc说明
一些设计可见:MallocInternals
其中的几个关键概念:
Arena(内存分配区):用于管理内存分配的数据结构,每个线程被分配到特定的Arena,从该Arena的空闲列表中分配内存,从而减少线程间的内存分配冲突Heap(堆):Heap是一块连续的内存区域,被划分为多个大小不同的块(Chunk)供程序分配使用。- 每个堆都归属于一个特定的 Arena,是内存分配的实际载体。
- 程序运行时,通过Arena对堆进行管理,分配和释放堆中的 Chunk,实现动态内存管理
Chunk(内存块):是 malloc 库中内存管理的基本单位,是对分配给应用程序的内存块的一种封装。Memory(内存):应用程序地址空间的一部分,通常由 RAM 或 swap(磁盘交换空间)作为支持。Thread Local Cache (tcache)(线程本地缓存):每个线程都有一个线程本地缓存 tcache,用于存储少量可直接访问的chunk,无需加锁
3.3.1. malloc_state
ptmalloc中使用 分配区(arena) 管理从操作系统批量申请来的内存,对应的结构为 malloc_state,每个arena分配区中的基本内存分配单位是malloc_chunk(简称chunk)(结构定义见下小节)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
// glibc-2.28/malloc/malloc.c
struct malloc_state
{
/* Serialize access. */
// libc的锁,用于保护当前分配区(arena)
// 多个分配区只是能降低锁竞争的发生,但不能完全杜绝,需要一个锁来应对多线程申请内存时的竞争问题
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
// 下面的 mfastbinptr、mchunkptr,都是 malloc_chunk* 的别名,表示内存块
/* Fastbins */
// fastbins 用于管理小尺寸的空闲内存块,其中包含多个链表
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
// top chunk:独立于 fastbins、smallbins、largebins 和 unsortedbins 之外的一个特殊的 chunk
// 如果没有空闲的 chunk 可用的时候,或者需要分配的 chunk 足够大,当各种 bins 都不满足需求,会从top chunk 中尝试分配。
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
// bins 是用来管理空闲内存块的主要链表数组,
// NBINS 大小是128,即bins数组长度最大 254(254个空闲链表)
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
// bins的使用位图
unsigned int binmap[BINMAPSIZE];
/* Linked list */
// 链表,通过这个指针,ptmalloc 把所有的分配区都以一个链表组织起来
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
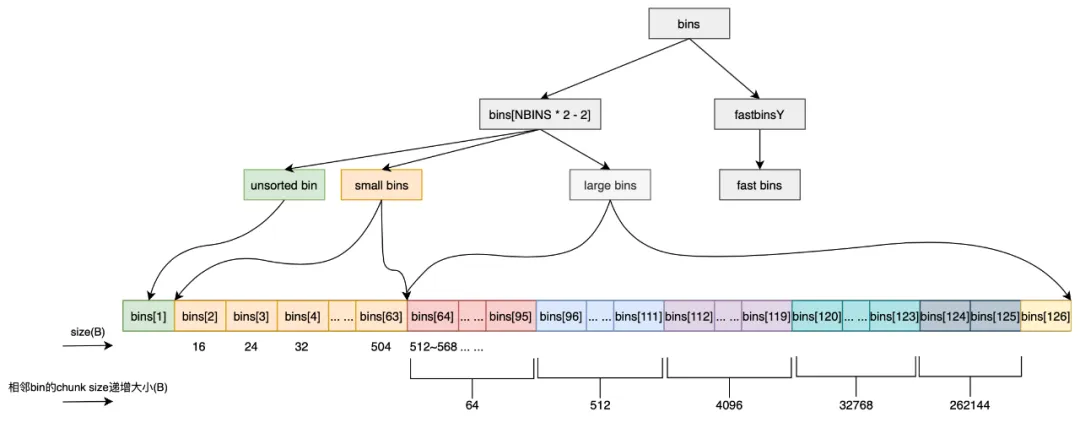
1、mfastbinptr fastbinsY[NFASTBINS]:用于管理小尺寸的空闲内存块,其中包含多个链表
- fastbin 中有多个链表(且都是单链表),每个 bin 链表管理的都是固定大小的 chunk 内存块。
- 在 64 位系统下,每个链表管理的 chunk 元素大小分别是 32 字节、48 字节、…、128 字节 等不同的大小。
fastbin_index函数可以快速地根据要申请的内存大小找到 fastbins 下对应的数组下标
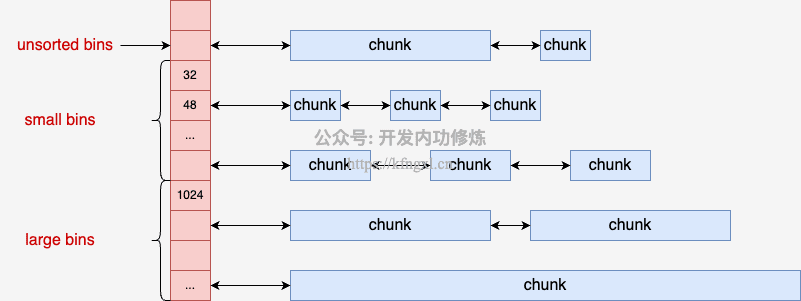
2、mchunkptr bins[NBINS * 2 - 2]:用来管理空闲内存块的主要链表数组(且都是双向链表)
NBINS大小是128,即bins数组长度最大 254(254个空闲链表),只用到126个成员(bin[0] 和 bin[127] 没有被使用)。
根据管理的内存块的大小,有以下3类:
- 1)
unsorted bin(1个,bin[1])- 管理的内存块不是和 smallbins 或 largebins 中那样是相同或者相近大小的,而是不固定,是被当做缓存区来用的
- 当用户释放一个堆块之后,会先进入 unsortedbin,便于快速复用。再次分配堆块时,ptmalloc 会优先检查这个链表中是否存在合适的堆块
- 如果找到了,就直接返回给用户(这个过程可能会对 unsortedbin 中的堆块进行切割)
- 若没有找到合适的,系统也会顺带清空这个链表上的元素,把它放到合适的 smallbin 或者 largebin 中
- 2)
small bins(62 个,bin[2]~bin[63])- 每个small bin链表里面,有64(
NSMALLBINS)个链表指针。 - 同一个small bin中的 chunk 具有相同的大小,在64位系统上,两个相邻的 small bin 中的 chunk 大小相差16字节(
SMALLBIN_WIDTH) - small bin 管理的内存块大小是从 32 字节、48 字节、…、1008 字节
smallbin_index函数 可以根据申请的字节大小快速算出其在 smallbin 中的下标
- 每个small bin链表里面,有64(
- 3)
large bins(63 个,bin[64]~bin[126])- 和 smallbins 的区别是它管理的内存块比较大,其管理的内存是 1024 起的
- 相邻的 largebin 之间管理的内存块大小不再是固定的等差数列
malloc_state结构示意图如下:
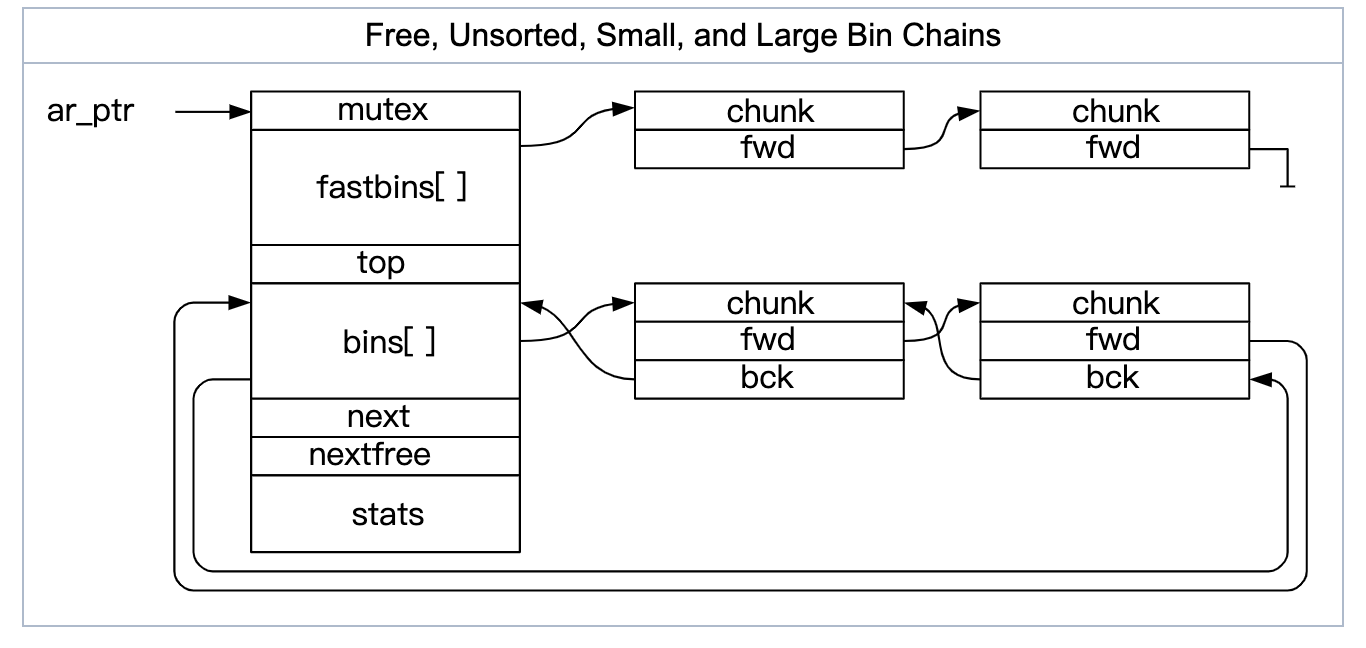
结合不同bins大小的示意图:
bins和fastbins示意,下图则更为直观:
3、mchunkptr top:
- top chunk 是独立于 fastbins、smallbins、largebins 和 unsortedbins 之外的一个特殊的 chunk
- 如果没有空闲的 chunk 可用的时候,或者需要分配的 chunk 足够大,当各种 bins 都不满足需求,会从top chunk 中尝试分配。
3.3.2. malloc_chunk
malloc_chunk 内存管理结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// glibc-2.28/malloc/malloc.c
struct malloc_chunk {
// 前一个空闲chunk的大小
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
// 当前chunk的大小
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
// fd:前驱指针,在chunk块空闲时才使用,用于将空闲chunk块加入到空闲chunk块链表中统一管理
struct malloc_chunk* fd; /* double links -- used only if free. */
// 后继指针
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
// fd_nextsize:chunk块空闲时才使用
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
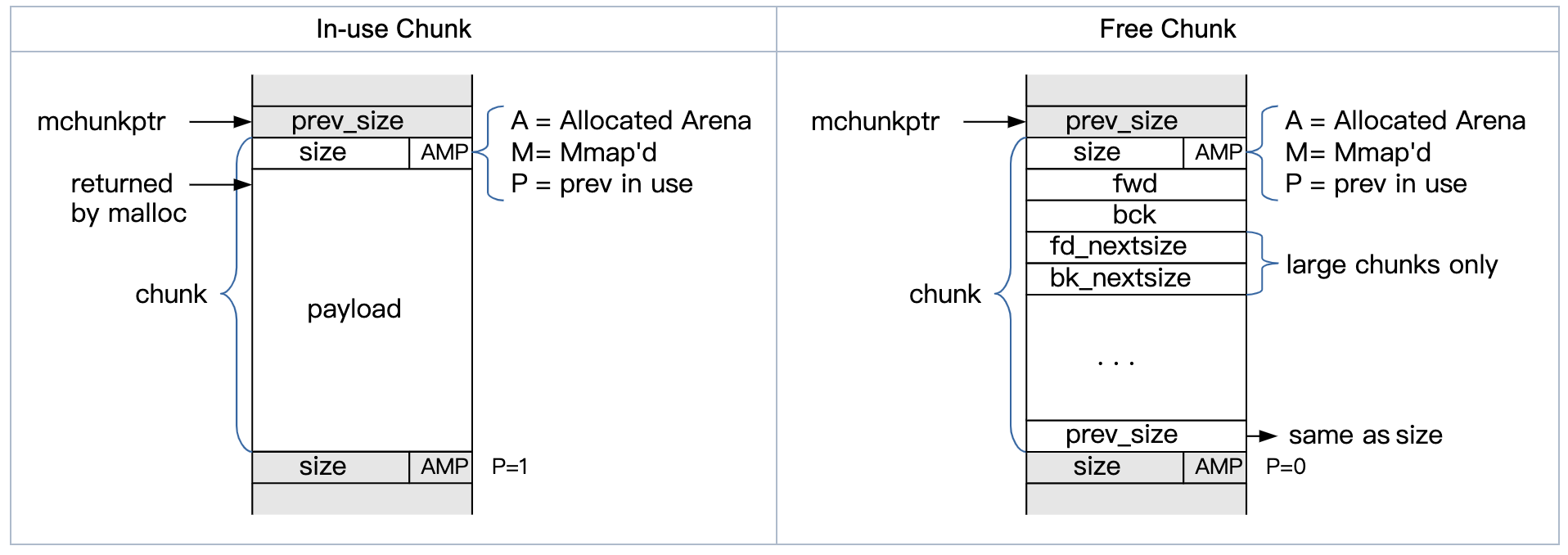
1)一个已分配chunk的结构示意结构如下:
mchunk_size中,还包含了3位属性标志位:|A|M|P|A(NON_MAIN_ARENA) :当前chunk块是否属于非主分配区M(IS_MMAPPED):当前chunk是否是通过mmap分配的P(PREV_INUSE):表示前一个chunk是否在使用中,P==1表示在使用中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
2)空闲的chunk存储在双向循环链表(circular doubly-linked list)中,示意图如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |A|0|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|0|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
使用中和空闲的chunk示意图如下。其中fd和fd_nextsize用于空闲指针的双链表结构。
3.3.3. thread cache
glibc 2.26(2017-08-02)版本中,malloc引入了thread cache(tcache),访问这部分cache不需要加锁。
1
2
3
4
5
6
7
8
9
10
11
12
# glibc-2.28/NEWS
Version 2.26
Major new features:
* A per-thread cache has been added to malloc. Access to the cache requires
no locks and therefore significantly accelerates the fast path to allocate
and free small amounts of memory. Refilling an empty cache requires locking
the underlying arena. Performance measurements show significant gains in a
wide variety of user workloads. Workloads were captured using a special
instrumented malloc and analyzed with a malloc simulator. Contributed by
DJ Delorie with the help of Florian Weimer, and Carlos O'Donell.
3.3.4. malloc分配过程
先来看下分配算法(具体见 MallocInternals):

即malloc分配时,依次判断是否有合适的空间(基于request2size规范化后的长度判断,即申请大小+长度字段+对齐),一达到满足条件则返回:
tcache->- 超出一定大小(阈值是动态的,除非指定mmap_threshold)或没有可用的
arenas分配区(第一次启动?),则直接mmap()从系统申请内存 -> - 申请小于等于fastbin管理的内存块最大大小(64位系统中:
160字节),fastbins(可能填充tcache) -> - 小于
1024字节(下图中的512B是32位系统?),smallbins(可能填充tcache) -> - 若还未满足,则把
fastbins里的相邻chunk合并,并移动(此处的移动只是链表指针操作,或者叫链接)到unsorted bin-> - 将
unsorted bin中的chunk,切割分配并放入到smallbins或者largebins,过程中也涉及合并,发现有满足的chunk内存块则返回 -> - 申请大小足够大则尝试 从
largebins申请 -> fastbins中还有chunk则重复前面步骤(即移动fastbins里内容到unsorted bin中…)- 上述都不满足,则从
top中分离一部分,可能会事先扩展top bin
具体一点的流程先贴一下(此处是还未支持tcache的版本),供参考,暂不深入梳理代码:

malloc对应的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
// glibc-2.28/malloc/malloc.c
// malloc 和 __malloc 是 __libc_malloc 的别名
strong_alias (__libc_malloc, __malloc) strong_alias (__libc_malloc, malloc)
// __libc_malloc 实现
void * __libc_malloc (size_t bytes)
{
...
// 使用tcache(默认启用)
#if USE_TCACHE
...
if (tc_idx < mp_.tcache_bins
&& tcache
&& tcache->entries[tc_idx] != NULL)
{
// 满足条件
return tcache_get (tc_idx);
}
#endif
..
if (SINGLE_THREAD_P)
{
// 单线程则使用 全局的主分配区
victim = _int_malloc (&main_arena, bytes);
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
&main_arena == arena_for_chunk (mem2chunk (victim)));
return victim;
}
// 获取arena,并加锁。其中的arena用于多线程场景,定义为:`static __thread mstate thread_arena attribute_tls_model_ie;`
arena_get (ar_ptr, bytes);
// 申请操作
victim = _int_malloc (ar_ptr, bytes);
...
if (ar_ptr != NULL)
__libc_lock_unlock (ar_ptr->mutex); // 其中解锁
return victim;
}
// _int_malloc简要逻辑
static void * _int_malloc (mstate av, size_t bytes)
{
INTERNAL_SIZE_T nb; /* normalized request size */
...
// 要申请的内存大小之外,还要附加长度字段并进行对齐(称作 长度规范化)
checked_request2size (bytes, nb);
if (__glibc_unlikely (av == NULL))
{
// 其中会使用mmap
void *p = sysmalloc (nb, av);
...
return p;
}
// 长度规范化后,判断长度在fastbin中是否覆盖
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
{
idx = fastbin_index (nb);
mfastbinptr *fb = &fastbin (av, idx);
...
// 还涉及tcache操作
tcache_put (tc_victim, tc_idx);
...
}
// small bins 操作处理
if (in_smallbin_range (nb))
{
idx = smallbin_index (nb);
bin = bin_at (av, idx);
...
}
else
{
// large bins 操作处理
idx = largebin_index (nb);
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate (av);
}
...
// unsorted bins 操作处理
for (;; )
{
int iters = 0;
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
{
...
}
...
use_top:
victim = av->top;
size = chunksize (victim);
...
}
...
}
上述全局的主分配区,静态变量,用于单线程:
1
2
3
4
5
6
7
8
// glibc-2.28/malloc/malloc.c
// 全局的主分配区
static struct malloc_state main_arena =
{
.mutex = _LIBC_LOCK_INITIALIZER,
.next = &main_arena,
.attached_threads = 1
};
3.3.5. 释放算法
free算法(具体见 MallocInternals):

具体一点的流程先贴一下(此处是还未支持tcache的版本),供参考,暂不深入梳理代码:

对应的代码入口如下,本篇中暂不展开。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// glibc-2.28/malloc/malloc.c
strong_alias (__libc_free, __free) strong_alias (__libc_free, free)
void __libc_free (void *mem)
{
...
ar_ptr = arena_for_chunk (p);
_int_free (ar_ptr, p, 0);
}
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
...
}
3.3.6. 优缺点
梳理了设计以及代码流程,再来看下述优缺点会更有体感:

4. 小结
总体梳理对比了ptmalloc、tcmalloc、jemalloc 和 mimalloc 几个内存分配器的特性,并看了下dlmalloc。
限于篇幅,本篇先覆盖了ptmalloc的代码跟踪,对其设计思路和实现进行印证。很多逻辑未深入,作为一个引子为进一步深入打下基础。