Ceph学习笔记(一) -- 总体架构和流程
Ceph梳理实践,介绍总体架构和流程。
1. 引言
开始梳理Ceph,结合分布式存储的工作经验,加深并补充技能树。Ceph用RocksDB作为存储引擎,趁此机会也看下RocksDB在工业级项目中的实践和调优效果。
Ceph提供了很全面的分布式存储功能,包括对象、文件、块,并支持很多特性,可以作为一个很好的入口,由点及面扩展梳理各类存储功能、RocksDB、纠删码、SPDK/DPDK、Prometheus、OpenTelemetry分布式链路跟踪、K8S等等的实际应用。
说明:基于版本 17.2.8(Quincy),fork一份 ceph-v17.2.8 的代码用于标注学习。
基于当前最新的发布版本 19.2.2(Squid),看tag里已经有v20.0.0了。基于tag v19.2.2建个分支:ceph-v19.2.2。
参考链接:
- Ceph Document – Quincy
- Intro to Ceph
- Architecture
- 说明:本文中的内容参考基于
Quincy版本的文档(原理一样的),后续使用Squid版本。
- ceph-v19.2.2源码
- 各版本时间线说明:ceph-releases-index
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 总体介绍
Ceph始于 Sage Weil 的博士论文(目前Weil在Red Hat工作,是Ceph项目的首席架构师),代码编写则开始于2004年。2010年3月,Linus Torvalds将Ceph Client合入Linux内核2.6.34版本。
具体可见:Ceph History。
2.1. 版本说明
版本格式:x.y.z
x.0.z开发版(早期测试)x.1.z候选版(测试集群适用)x.2.z稳定版(用户生成环境推荐)
稳定发布版本(stable release)的维护生命周期,近似24个月,具体见ceph-releases-index给出的时间线。
LLM提供的各个版本代号和部分关键特性,下面也贴一下作了解(也可了解wikipedia:Release_history)。
代号命名:按字母顺序命名(单词中的 首字母)
- 更早期版本
Argonaut(0.48版本, LTS),2012年6月发布,是长期支持版本(LTS)。Bobtail(0.56版本, LTS),2013年5月发布,同样是LTS版本,带来了显著的性能改进和新的功能。Cuttlefish(0.61版本),2013年1月发布,引入了新功能并提升了系统的稳定性。Dumpling(0.67版本, LTS),2013年8月发布,专注于提高稳定性和修复bug。Emperor,0.72.2, 2013-11-01Firefly0.80.11, 2014-05-01Giant0.87.2, 2014-10-01Hammer0.94.10, 2015-04-01Infernalis9.2.1, 2015-11-01
Jewel(10.2.z),J- 发布时间:2016年4月
- 首个支持CRUSH Tunables优化算法的版本。
- 引入RGW(对象存储网关)的S3多对象复制API。
- 默认使用AsyncMessenger提升网络性能。
Kraken(11.2.z),K- 发布时间:2017年10月
- 改进OSD故障检测机制,优化心跳超时。
- 支持RGW元数据离线重塑。
Luminous(12.2.z),L,第12个大版本- 2017年10月
- BlueStore:默认的OSD后端存储,直接管理裸盘,支持数据校验与压缩(zlib/snappy/LZ4)。
- ceph-mgr:新增管理守护进程,提供REST API、Prometheus/Zabbix监控插件。
- 支持10,000 OSD的大规模集群,优化CRUSH规则自动化。
Mimic(13.2.z),M- 2018年5月(LTS)
- 增强BlueStore的稳定性和性能。
- 支持RBD镜像延迟删除(Trash功能)。
Nautilus(14.2.z),N- 2019年2月
- 引入Cephadm工具,简化集群部署与管理。
- 支持纠删码存储池(Erasure Code)优化存储效率。
Octopus(15.2.z),O- 2020年4月
- 增强容器化部署(如Kubernetes集成)。
- 改进RGW多站点同步的稳定性。
Pacific(16.2.z),P- 2021年3月
- 引入RGW的服务器端加密(SSE-KMS支持)。
- 优化CephFS元数据分片性能。
Quincy(17.2.z),Q- 2022年4月
- 增强安全性,支持TLS 1.3。
- 改进OSD的自动故障恢复机制。
Reef(18.2.z),R- v18.2.6(截至2025年4月)
- 支持Zstandard(zstd)压缩算法优化性能。
- 引入AI驱动的负载均衡策略。
Squid(19.2.2)- v19.2.2(截至2025年4月)
2.2. Ceph集群构成
具体见:Intro to Ceph。
一个Ceph存储集群中需要:
- 1、至少一个
Ceph Monitor daemon(Monitor)ceph-mondaemon服务,维护集群拓扑状态的map信息(即 Cluster Map),包括monitor map、manager map、OSD map、MDS map和CRUSH map,这些map状态是守护进程/后台服务(daemon)间相互通信的关键信息。Monitor还负责管理daemon和客户端之间的身份验证。- 若需要保持冗余和高可用,一般至少需要 3个
ceph-mon- Ceph中使用 Paxos算法来维护Monitor之间的一致性。
- 也可以只有一个
ceph-mon,不过此时存在单点故障,若该Monitor异常,则无法对Ceph集群进行数据读写。 - Monitor相关配置,可了解:mon-config-ref
- 2、至少一个
Ceph Manager daemon(Manager)ceph-mgrdaemon服务,负责跟踪运行时指标(metrics)和集群的当前状态,包括存储利用率、性能指标和系统负载。- Manager服务还提供了基于python的模块,包括一个
web面板(Ceph Dashboard)和REST API - 若需要保持高可用,一般至少需要 2个
ceph-mgr- 最佳实践:对于每个
Monitor,都运行一个Manager,但这不是必须的
- 最佳实践:对于每个
- 3、大于等于副本个数的
OSD(Ceph Object Storage Daemon / Object Storage Device)ceph-osddaemon服务,负责数据存储,处理数据复制、恢复和重新负载,并提供一些监控信息给Monitor和Manager- OSD除了会检查自己的状态,还会通过心跳检查其他OSD的状态,并上报给Monitor。
- 一般至少需要 3个
ceph-osd来保持冗余和高可用 - 单独使用
OSD可能指代物理或者逻辑存储单元,不过Ceph社区一般用作指代Object Storage Daemon,可了解:term-Ceph-OSD 和 term-OSD。
- 4、另外,如果要使用
文件存储(Ceph File System),则还需要MDS(Ceph Metadata Server)ceph-mdsdaemon服务,存储文件系统需要的元数据信息,MDS服务允许CephFS用户运行基本命令,如ls、find等等。
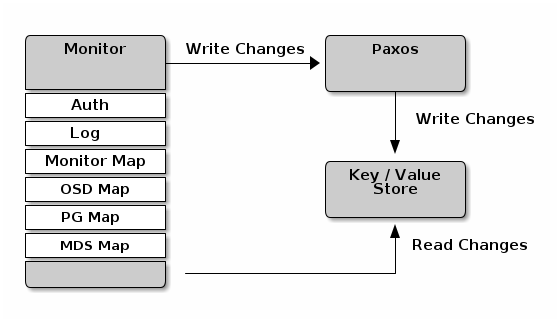
Ceph Monitor读写map信息的示意图如下:
- Monitor除了维护
Cluster Map外,还提供身份校验和日志服务。 Write操作都写入到单一的Paxos实例中,Paxos提供强一致性,并将这些变更操作写入到 RocksDB 的key-value存储中。- Monitor里还维护了这些map的一个历史版本,每个版本(version)称作
epoch。
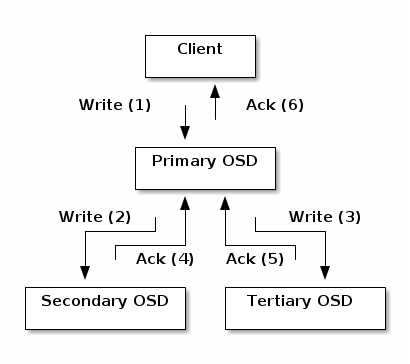
客户端数据写入和复制的过程示意图如下:
客户端通过CRUSH算法来确定object要写到哪个存储位置,而后object会映射到一个pool和placement group;然后客户端查询CRUSH map,查看这个placement group(PG)对应的主OSD(primary OSD)。- 而后
客户端向primary OSD写object数据;primary OSD则查询CRUSH map来确定数据副本要写的第二个和第三个OSD(secondary and tertiary OSDS),并向其写object数据。 - 当
PG对应的OSD都写入成功后,primary OSD返回结果给客户端。
3. Ceph架构
具体见:Architecture
3.1. 架构示意图
Ceph可以在一个单一系统中同时提供对象、块 和 文件存储。
架构示意图如下:
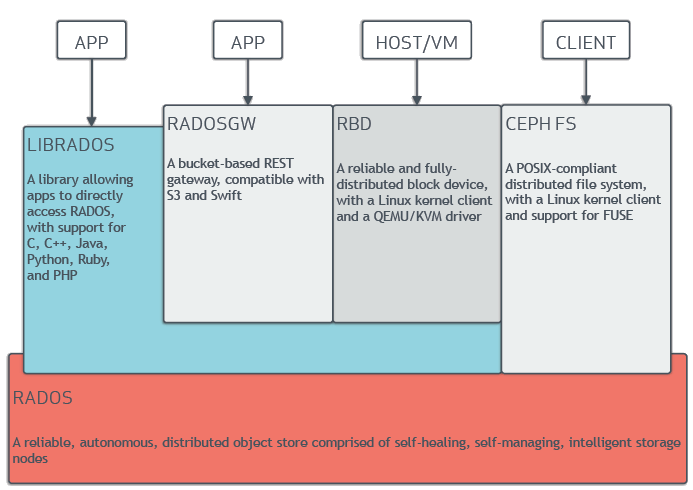
1、Ceph客户端(Ceph Client):任何可以访问Ceph存储集群(Ceph Storage Cluster)的Ceph组件。包括RADOSGW对象存储(Ceph Object Gateway)、RBD块存储(Ceph Block Device / RADOS Block Device)、CephFS文件存储(Ceph File System),以及相应的库;也包括内核模块 和 FUSE(Filesystems in USERspace);也可以是基于librados的自定义实现(RADOSGW和RBD也基于librados访问Ceph集群)。
2、Ceph存储集群从Ceph客户端接收数据,并存储成RADOS objects,每个object对象都存储在一个Object Storage Device(也简称OSD,跟上面Daemon按场景转换理解)上面。默认的 BlueStore 存储后端以单一的、类似数据库的方式(monolithic, database-like fashion)存储对象。
3、Ceph的扩展性和高可用通过 客户端 和 OSDs 直接交互来避免单点故障,其中使用CRUSH算法,下面小节单独说明。
上述Ceph客户端和Ceph存储集群(Ceph Storage Cluster)的架构示意图:
- 对象存储
RADOSGW:提供RESTFul HTTP API来存储object和元数据。(Ceph中的object和S3、Swift中的object不是一样的) - 块存储RBD:上层是块设备组织形式,底层还是RADOS的object形式组织。对于虚拟系统的支持,包含
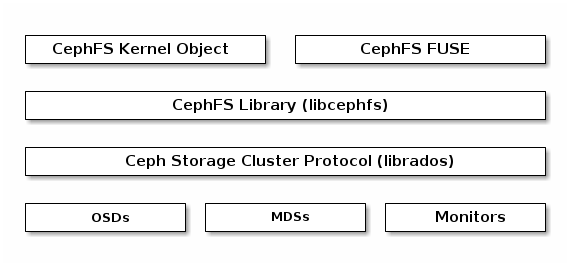
ko内核模块 和 QEMU管理程序直接使用librbd(可避免内核态额外开销) 2种方式。 - 文件存储CephFS:提供POSIX兼容的文件系统,支持
mount或fuse方式使用
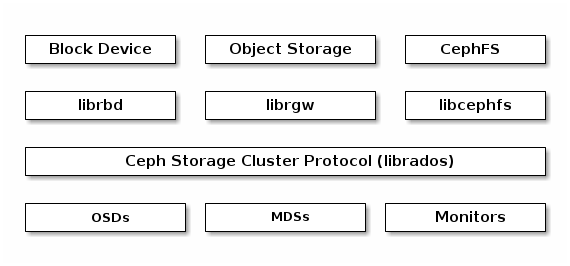
CephFS文件存储的架构示意:
3.2. RADOS 存储引擎
底层存储引擎称为RADOS(Relaible Autonomic Distributed Object Store)(意译:可靠的自管理分布式对象存储),负责数据存储、复制和故障恢复。Ceph基于RADOS提供可无限扩展(infinitely scalable)的存储集群。
Ceph的上层特性则基于librados来访问Ceph存储集群。
RADOS进一步了解可见:
1、作者Sage Weil对RADOS简要介绍的博客:The RADOS distributed object store。
- RADOS提供的底层存储抽象相对比较简单:
- 1)数据的存储单元是
对象(object),每个object有一个名称,和少量有名属性(named attributes),以及可变长度的数据负载。 - 2)
objects存储在对象池(object pools)中,每个pool都有一个名称,并且形成不同的对象命名空间(object namespace)。此外还有少量参数:副本级别(比如2副本、3副本等)、描述副本存储分布情况的映射规则(比如副本在哪个机架)。 - 3)存储集群包含一些数量的
存储服务,或OSD(object storage daemons/devices),且组合集群可存储任意数量的pools(对象池)。
- 1)数据的存储单元是
- RADOS的一个关键设计是,在故障恢复或者集群扩展需要迁移数据时,OSD能够以相对自主(relative autonomy)的方式进行。
2、详尽说明则可见 RADOS论文:RADOS: A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters。
3.3. CRUSH算法:扩展性和高可用
Ceph以 对象(object)的形式将数据存储在逻辑存储池(logical storage pools)中。
存储集群的 客户端 和 OSD 通过 CRUSH(Controlled Replication Under Scalable Hashing) 算法(意译:可扩展哈希控制下的数据分布算法),计算数据的位置信息:object应该归属于哪个PG(placement group,放置组),哪个OSD应该用于存储该PG。CRUSH算法使Ceph存储集群能够动态扩展、重新平衡和动态恢复。
- Ceph中的
客户端和OSDs都通过CRUSH计算位置信息,消除了传统架构中向中心化组件查表的单点瓶颈。 - CRUSH论文:CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data
Cluster Map:集群当前的拓扑结构信息。其中实际包含5个map:monitor map、manager map、OSD map、MDS map 和 CRUSH map,即前面介绍ceph-mon时包含的信息。各个map包含的信息,可见:cluster-map。
- Ceph
客户端需要先和Monitor通信,获取当前集群的Cluster Map副本,用于数据读取和写入。 CRUSH需要依赖Cluster Map信息进行RADOS的object位置计算。
3.4. 论文说明
参考:Ceph论文简介
Ceph是Sega本人的博士论文作品,想了解Ceph的架构设计最好的方式是阅读Sega的论文,其博士论文我们称之为长论文,后来整理成三篇较短的论文。
上面已经提到了CRUSH和RADOS,这里把几篇论文统一罗列下:
- 1、长论文:Ceph: Reliable, Scalable, and High-Performance Distributed Storage
- 包含了
CRUSH、RADOS等所有内容的介绍,篇幅很长(239页。。)
- 包含了
- 2、
CRUSH论文:CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data- 介绍了CRUSH的设计与实现细节(12页)
- 3、
RADOS论文:RADOS: A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters- 介绍了RADOS的设计与实现细节(10页)
- 4、
CephFS论文:Ceph: A Scalable, High-Performance Distributed File System- 介绍了Ceph的基本架构和Ceph的设计与实现细节(14页)
另外,官网上也列出了 Ceph相关的论文和出版书籍:Publications About Ceph,上述论文链接都可以在此处找到。
4. 小结
本篇介绍了Ceph项目的背景,并梳理学习了基本的Ceph架构,集群组成、核心概念等。后续进行实际操作和相关代码流程走读分析。