TCP发送接收过程(二) -- 实验观察TCP性能和窗口、Buffer的关系(上)
通过实验观察TCP性能和窗口、Buffer的关系,并用Wireshark跟踪TCP Stream Graphs。
1. 引言
上一篇博客中介绍了Wireshark里的TCP Stream Graghs可视化功能并查看了几种典型的图形,本篇进行实验观察TCP性能和窗口、Buffer的关系,并分析一些参考文章中的案例。
一些相关文章:
- 参考本篇进行实验:TCP性能和发送接收窗口、Buffer的关系
- 实验来自 知识星球 – 实验动起来 BDP和buffer、RT的关系。
- 下面是其他星友做的实验,呈现方式挺好,可参考。
- Packet capture experiment 1
- Packet capture experiment 2
- TCP传输速度案例分析
- TCP 拥塞控制对数据延迟的影响
- TCP 长连接 CWND reset 的问题分析
202505更新:之前一直占坑没进行实验,最近定位问题碰到UDP接收缓冲区满导致丢包的情况,补充本实验增强体感。
另外近段时间重新过了下之前看过的几篇网络相关文章,对知识树查漏补缺挺有帮助:
- 云网络丢包故障定位全景指南
- 极客重生公众号作者,前面的博客中也有部分内容索引到作者的文章,干货挺多,后续梳理学习其他历史文章
- [译] RFC 1180:朴素 TCP/IP 教程(1991)
- 之前也简单画图梳理过:RFC1180学习笔记
说明:本博客作为个人学习实践笔记,可供参考但非系统教程,可能存在错误或遗漏,欢迎指正。若需系统学习,建议参考原链接。
2. 理论和技巧说明
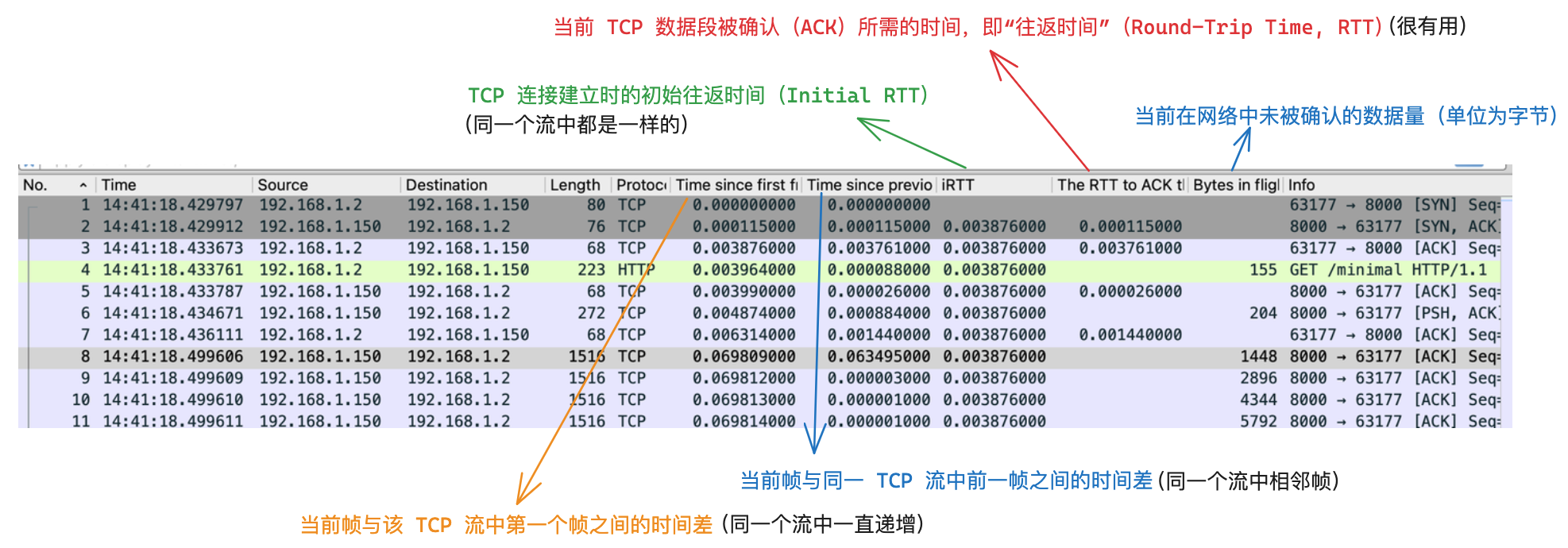
2.1. 计算在途字节数
在途字节数(Bytes in flight):发送方已发送出去,但是尚未接收到ACK确认的字节数(正在链路上传输的数据)。在途字节数如果超出网络的承载能力,会出现丢包重传。
如何计算在途字节数?
- TCP传输过程中,由于客户端和服务端的网络包可能是不同的顺序,所以最好两端都进行抓包,并从 数据发送方(TODO待验证对比)抓到的包分析在途字节数。
- 计算方式:
在途字节数 = Seq + Len - Ack(Wireshark中提供的SEQ/ACK analysis功能会自动计算) - TCP协议中,由发送窗口动态控制,跟
cwnd拥塞窗口和rwnd接收窗口也有关系。
在Wireshark中可以直接查看其提供的Seq、Ack分析结果,方式可见 Wireshark中新增实用列中的示例:
2.2. 估算网络拥塞点
当发送方发送大量数据,在途字节数超出网络承载能力时,就会导致拥塞,这个数据量就是 拥塞点。
大致可以认为:发生拥塞时的在途字节数就是该时刻的网络拥塞点。
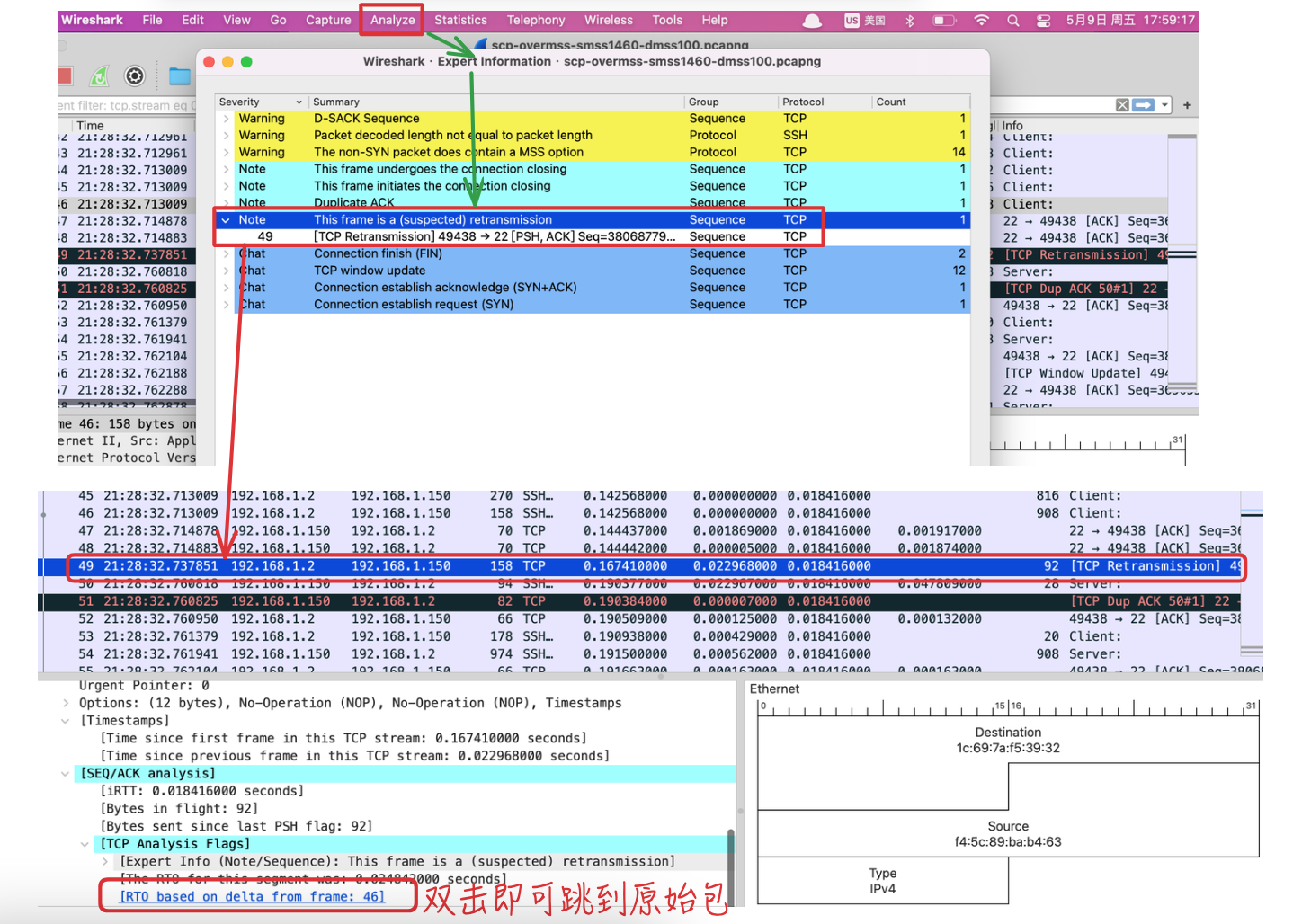
如何在Wireshark中找到拥塞点?
- 从Wireshark中找到一连串重传包中的第一个,再根据重传包的
Seq找到 原始包,最后查看原始包发送时刻的在途字节数。SEQ/Ack analysis结果里的This frame is a (suspected) retransmission,
- 具体步骤:
- 在 Export Info中查看重传统计表
- 找到第一个重传包,根据其
Seq找原始包- 根据过滤条件查找,如:
tcp.seq == 3684862270,可以在TCP详情中对Sequence Number右键 ->Apply As Filter->Selected自动设置过滤条件。 - 也可以直接在
SEQ/ACK analysis中跳转到原始包。
- 根据过滤条件查找,如:
- 如下图所示,对应的原始包是
No为46的包,其在途字节数为908,即此时的网络拥塞点。
- 该方法不一定很精确,但很有参考意义。
拥塞点估算示例:
2.3. Expert重传包说明
Wireshark的Expert Infomation信息中分析统计了各个包类型的分类。对于重传类型:This frame is a (suspected) retransmission,有时统计的信息中,Seq和原始包并不相同,但是也统计为了重传,此处做下解释说明。
如下图所示:

说明:
- 1、
18895~18911号包都显示是18888号包的重传包,是由于Wireshark发现18888号包的Seq+Len对应的载荷范围,和上述那些包中Seq+Len对应的 载荷范围有重叠,所以标记为了本包的重传。- 发送方只收到部分分段的Ack时,也会触发未确认部分的超时重传(RTO)
- 2、由于
18888号包的载荷65160远远超过MTU(一般1500),所以TCP层一般会自动分段传输,拆成多个segment。- 但因为
TSO(TCP Segment Offload)机制的存在,会将拆包的工作offload到网卡来负责,所以从内核侧看就是发了大包到网卡,会超过MTU。可进一步参考了解:有关 MTU 和 MSS 的一切。
- 但因为
2.4. 带宽时延积(BDP)
带宽时延积BDP(Bandwidth-Delay Product):带宽 (bps) 和 往返时延 (RTT, 秒)的乘积,衡量在特定带宽和往返时延(RTT)下,网络链路上可同时传输的最大数据量。
- 公式:
BDP (bits)=带宽 (bps) * 往返时延 (RTT, 秒)- 如:带宽1Gbps(即万兆)、RTT为50ms,则
BDP = 10^9 * 0.05 = 5*10^7 bits = 6.25MB
- 如:带宽1Gbps(即万兆)、RTT为50ms,则
- 和在途字节数的关系:
BDP是链路的理论容量,在途字节数是实时传输中的数据量。- 若
在途字节数 == BDP,说明链路被完全填满,可达到最大吞吐量 - 若
在途字节数 < BDP,链路未充分利用 - 若
在途字节数 > BDP,可能引发拥塞或丢包
- 若
3. 实验说明
3.1. 环境和步骤
自己本地只有一个Mac笔记本和Rocky Linux系统的PC,对MacOS的内核网络控制不熟悉,还是尽量模拟生产环境中的Linux间通信,起ECS进行实验。
起2个阿里云ECS(2核2G):
- 系统:Rocky Linux release 9.5 (Blue Onyx)
- 内核:5.14.0-503.35.1.el9_5.x86_64
网速基准:TCP 2.1Gbps左右(此处是突发流量,起的ECS类型ecs.e-c1m1.large对应弹性网卡,基础带宽0.2Gbps/最高2Gbps,阿里云规格说明)
1
2
3
4
5
6
7
8
9
# TCP
[root@iZbp169scc1yz2vwe6mp31Z ~]# iperf3 -c 172.16.58.147
Connecting to host 172.16.58.147, port 5201
[ 5] local 172.16.58.146 port 56178 connected to 172.16.58.147 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
...
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 2.56 GBytes 2.20 Gbits/sec 87452 sender
[ 5] 0.00-10.22 sec 2.56 GBytes 2.15 Gbits/sec receiver
步骤说明:
- 服务端:
python -m http.server起http服务,监听8000端口dd一个2GB文件用于测试:dd if=/dev/zero of=test.dat bs=1G count=2
- 客户端:
curl请求下载文件curl "http://xxx:8000/test.dat" --output test.dat
- 抓包:
tcpdump -i any port 8000 -s 100 -w normal_client.cap -v- 先两端都抓包对比下,服务端抓包:
tcpdump -i any port 8000 -s 100 -w normal_server.cap -v
自己PC的Rocky Linux发送接收窗口相关参数默认值(可通过man tcp查看各选项含义和功能):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# ECS里则把下面两项:TCP和UDP的内存配置降低了,其他一样
# net.ipv4.tcp_mem = 18951 25271 37902
# net.ipv4.udp_mem = 37905 50542 75810
# 本地PC
[root@xdlinux ➜ tmpdir ]$ sysctl -a|grep mem
# 每个socket接缓冲区的默认值,字节
net.core.rmem_default = 212992
# 每个socket接收缓冲区的最大允许值,字节
net.core.rmem_max = 212992
# 每个socket发送缓冲区的默认值,字节
net.core.wmem_default = 212992
# 每个socket发送缓冲区的最大允许值,字节
net.core.wmem_max = 212992
# TCP协议整体使用的内存阈值,注意:单位是page(page size一般4KB,可`getconf PAGESIZE`查看)
# [low, pressure, high]数组。
# low:TCP内存充足,无需限制;pressure:内核开始限制TCP内存分配;high:内核拒绝新连接
# (低水位 压力模式 上限)
# (1.43GB 1.92GB 2.88GB)
net.ipv4.tcp_mem = 371808 495745 743616
# TCP单个连接的接收缓冲区窗口,单位:字节。在TCP中会覆盖上面的全局socket缓冲区配置
# TCP根据网络状况动态调整缓冲区大小,范围在[min, max]之间
# [min, default, max]
# 4KB 128KB 6MB
net.ipv4.tcp_rmem = 4096 131072 6291456
# TCP单个连接的发送缓冲区大小
# 4KB 16KB 4MB
net.ipv4.tcp_wmem = 4096 16384 4194304
# UDP整体使用的内存阈值,单位:page
# (低水位 压力模式 上限)
# (2.88GB 3.84GB 5.76GB)
net.ipv4.udp_mem = 743616 991490 1487232
# UDP单个连接接收缓冲区的最小值,4KB
net.ipv4.udp_rmem_min = 4096
# UDP单个连接发送缓冲区的最小值,4KB
net.ipv4.udp_wmem_min = 4096
另外还有:
- 接收缓冲区buffer自动调节开关:
tcp_moderate_rcvbuf(发送则没有开关,默认开启) tcp_adv_win_scale,用于手动指定了SO_RCVBUF时,内核分配buffer大小实际是2倍,并从中分出1 / (2^tcp_adv_win_scale)来作为乱序报文缓存以及metadata。具体见上述“TCP性能和发送接收窗口、Buffer的关系”参考链接。
1
2
3
[root@xdlinux ➜ bdp_case ]$ sysctl -a|grep -E "adv_win|moderate"
net.ipv4.tcp_adv_win_scale = 1
net.ipv4.tcp_moderate_rcvbuf = 1
3.2. 实验用例
- 1、保持默认参数正常curl下载文件,抓包用作基准对比
- 2、修改服务端的发送窗口为最小值:4096,即一个page size;客户端不变
- 服务端:
sysctl -w net.ipv4.tcp_wmem="4096 4096 4096"
- 服务端:
- 3、服务端不变;修改客户端的接收窗口为4096
- 客户端:
sysctl -w net.ipv4.tcp_rmem="4096 4096 4096"
- 客户端:
3.3. 结果及分析
在不同环境实验过,对于硬件配置、负载不同的客户端和服务端,两端抓包可能相差会比较大,比如:接收端处理不过来,发送端多次重传。所以此处把两端的包还是都对比下。
下述抓包文件做了归档,可见:ecs_bdp_case。
总体统计信息如下,也可见:google sheets。

总体分析:
- 可见:
- 限制服务端发送窗口对下载影响不大;
- 限制客户端接收窗口则影响很大。
- 说明:上述
RTT是按分布最多区间大概估算的值,仅做对比参考(计算BDP应该动态取指定时间点的RTT)。 - 前面
iperf看突发流量基准是到了2Gbps左右,此处包括后续实验的带宽按2Gbps作为基准。- 所以若RTT为
2ms时,BDP为2Gbps * 0.002 / 8 = 0.5MB。
- 所以若RTT为
- BDP需要根据RTT动态计算,RTT波动大时BDP也相应变化。
- 并可以和Window Scaling图中的
Byte in flight(已发出未确认)对比。 - 当
Byte in flight把BDP占满,再调大发送窗口或接收窗口也没意义了。
- 并可以和Window Scaling图中的
3.3.1. 用例1:默认参数
下载速度,121MB/s:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 客户端curl下载
[root@iZbp169scc1yz2vwe6mp31Z ~]# curl 172.16.58.147:8000/test.dat --output rcv.dat
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2048M 100 2048M 0 0 121M 0 0:00:16 0:00:16 --:--:-- 106M
# 客户端查看(截取一次,缩进略有调整)
[root@iZbp169scc1yz2vwe6mp31Z ~]# ss -ianp -om|grep -A1 8000
tcp ESTAB 2688024 0 172.16.58.146:59178 172.16.58.147:8000 users:(("curl",pid=39404,fd=5)) timer:(keepalive,56sec,0)
skmem:(r3126272,rb3214380,t0,tb87040,f3072,w0,o0,bl0,d75) ts sack
cubic wscale:7,7 rto:201 rtt:0.291/0.149 ato:40 mss:1448 pmtu:1500 rcvmss:1448 advmss:1448 cwnd:10 bytes_sent:90 bytes_acked:91 bytes_received:711673808 segs_out:6357 segs_in:492761 data_segs_out:1 data_segs_in:492759 send 398075601bps lastsnd:3021 lastrcv:5 lastack:5 pacing_rate 796151200bps delivery_rate 67348832bps delivered:2 app_limited rcv_rtt:0.918 rcv_space:977400 rcv_ssthresh:2417445 minrtt:0.172 snd_wnd:31872
# 服务端查看(截取一次)
[root@iZbp169scc1yz2vwe6mp30Z ~]# ss -ianp -om|grep -A1 8000
tcp ESTAB 0 4170240 172.16.58.147:8000 172.16.58.146:59178 users:(("python",pid=37559,fd=4)) timer:(on,003ms,0)
skmem:(r0,rb131072,t0,tb4194304,f1024,w4254720,o0,bl0,d0) ts sack
cubic wscale:7,7 rto:202 rtt:1.307/0.769 ato:40 mss:1448 pmtu:1500 rcvmss:536 advmss:1448 cwnd:1018 ssthresh:192 bytes_sent:1052453816 bytes_retrans:271224 bytes_acked:1051874168 bytes_received:90 segs_out:728851 segs_in:9206 data_segs_out:728850 data_segs_in:1 send 9022579954bps lastsnd:2 lastrcv:5803 lastack:3 pacing_rate 10822955560bps delivery_rate 2855697808bps delivered:728637 busy:5789ms rwnd_limited:5372ms(92.8%) unacked:214 retrans:0/240 dsack_dups:240 rcv_space:14600 rcv_ssthresh:31820 notsent:3861816 minrtt:0.17 snd_wnd:308992
客户端抓包:

服务端抓包:

分析:
- 两种
Time/Sequence图中,由于发生了Seq回绕,导致Seq出现断层。- 在Windows上的Wireshark中,右键切换
Relative/Absolute Sequence Number可以展示成正常递增的图形。但是Mac上试了下好像没生效,可能Wireshark兼容没做好,暂不纠结。手动触发更新还是一样。(0511更新:Wireshark又提示更新了一次,操作后切换后正常了)
- 在Windows上的Wireshark中,右键切换
- 从RTT图可以看到,
10~12.5s之间有几次很明显的突刺,都超过150ms,需要关注下。- 10.49到10.75之间都没有发包,且10.49s之前的一批包的RTT都在210ms以上
- 对应到
Time/Sequence中则是几个平顶,未传输数据。这段时间客户端没有进行ACK。吞吐量也收到了影响。
- 上面统计表格中,客户端抓包的RTT是按最多分布估计的
0.5ms,BDP则为2Gbps * 0.5/1000 / 8 = 0.125MB,而Window Scaling中出现了3MB左右的UnAck(即Byte in flight),所以 RTT估计并不准确。- 由于发送接收窗口是在
[min, max]间自动调整的,相应RTT也是变化的,计算BDP时需要按当时时间点的RTT进行动态计算并和其他TCP图作对比。 - 找出现
3MB(3000000,2.86MB)左右Unacked的时间点,当时RTT为7.5ms左右,则BDP为2Gbps * 7.5/1000 / 8 = 1.9MB,还是有差距在(TODO分析)。 - 其他信息:
- 该时间点持续
8ms左右客户端没做应答,不过服务端发送还未触发发送窗口满,客户端来一次性ACK了; - 但是接下来客户端持续了一段
30ms的未应答,服务端发送的Byte in flight累积到2982352,而后客户端一次性ACK了全部; - 客户端接收窗口从
2239104更新到4579200,还在net.ipv4.tcp_rmem的范围:4096 131072 6291456(4KB 128KB 6MB)
- 该时间点持续
- 由于发送接收窗口是在
3.3.2. 定位用例1中RTT尖刺
针对上述RTT的尖刺问题,来看下10.49s这次的RTT尖刺:服务端一直发包,直到Window Full,等到客户端应答了,应答了个ZeroWindow。

推断是客户端没给应答或者应答慢,可能是客户端下载的数据需要落硬盘操作(page cache刷写),影响了应答处理。
重新实验进行确认:使用strace或者perf trace追踪系统调用,确认是否有文件系统、硬盘相关耗时操作。
- 但是注意
strace会拖慢程序处理,可能影响实验结果。 perf trace在ECS里试了下没抓到客户端curl的统计信息(TODO待确认)
1、开始搞错了,追踪了服务端http服务的系统调用。但也能看到是发送给客户端耗时久,从服务端看不到具体细节,需要追踪客户端确认原因。

服务端perf trace跟踪http服务没看到什么有效信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[root@iZbp169scc1yz2vwe6mp30Z ~]# perf trace -p 39428 -s
^C
Summary of events:
python (39428), 154 events, 99.4%
syscall calls errors total min avg max stddev
(msec) (msec) (msec) (msec) (%)
--------------- -------- ------ -------- --------- --------- --------- ------
poll 63 0 30950.178 0.000 491.273 500.626 1.63%
futex 9 0 0.313 0.002 0.035 0.171 53.41%
clone3 1 0 0.170 0.170 0.170 0.170 0.00%
accept4 1 0 0.060 0.060 0.060 0.060 0.00%
rt_sigprocmask 2 0 0.011 0.003 0.006 0.009 55.04%
getsockname 1 0 0.004 0.004 0.004 0.004 0.00%
2、追踪客户端,重新实验
1
2
3
4
5
6
7
8
# strace追踪,可看到慢了挺多
[root@iZbp169scc1yz2vwe6mp31Z ~]# strace -o shot-rtt-sharp2-strace_client.log -Ttt -yy curl 172.16.58.147:8000/test.dat --output rcv.dat
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2048M 100 2048M 0 0 50.8M 0 0:00:40 0:00:40 --:--:-- 51.0M
# 并抓包
[root@iZbp169scc1yz2vwe6mp31Z ~]# tcpdump -i any port 8000 -s 100 -w shot-rtt-sharp2-normal_clientside_2.cap -v
跟踪抓包和strace(完整文件可见这里),可看到第一个最大耗时的还是创建文件,消耗了116ms,此时网络尖刺有40+ms(但无法得出就是因为文件操作才导致了尖刺的结论)。
write久主要是写文件进入page cache,达到一定条件后刷脏页,增加IO延迟进而影响上层IO卡顿。(这也是libaio或io_uring的一个优势,分离I/O操作与主线程,可减小对上层应用的影响)

过滤下strace结果中的recvfrom(从服务端收包),间隔一般在2ms左右,偶尔会有10ms左右的尖刺,和RTT图是一致的。
1
2
3
4
5
6
7
8
9
[MacOS-xd@qxd ➜ ecs_case ]$ grep recvfrom shot-rtt-sharp2-strace_client.log
...
21:16:06.206901 recvfrom(5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 102400 , 0, NULL, NULL) = 102400 <0.000104>
21:16:06.208835 recvfrom(5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 102400 , 0, NULL, NULL) = 102400 <0.000108>
# 和上一个网络包间隔11ms
21:16:06.219204 recvfrom(5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 102400 , 0, NULL, NULL) = 102400 <0.000238>
21:16:06.221358 recvfrom(5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 102400 , 0, NULL, NULL) = 102400 <0.000089>
21:16:06.223302 recvfrom(5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 102400 , 0, NULL, NULL) = 102400 <0.000089>
...
找几个间隔久的情况。在RTT图上表现为一个10ms的尖刺,对应的前后时间如下,中间以及上下附近 都没有write比较久的记录,其他系统调用也没有延时高的情况。光从strace信息里看不出来什么原因导致的突刺。(TODO 后续再尝试定位)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
21:16:06.206901 recvfrom(5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 102400, 0, NULL, NULL) = 102400 <0.000104>
# 中间也没有write耗时较久的情况,基本在0.03ms左右,长的也只有0.1ms
21:16:06.207069 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096 <0.000038>
21:16:06.207155 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 12288) = 12288 <0.000033>
...
21:16:06.208667 poll([{fd=5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, events=POLLIN|POLLPRI|POLLRDNORM|POLLRDBAND}], 1, 0) = 1 ([{fd=5, revents=POLLIN|POLLRDNORM}]) <0.000029>
# 接收数据
21:16:06.208835 recvfrom(5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 102400, 0, NULL, NULL) = 102400 <0.000108>
# 写文件,但没有耗时较久的情况,长一些的也只有0.1ms
21:16:06.209008 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096 <0.000040>
21:16:06.209101 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 12288) = 12288 <0.000035>
21:16:06.209182 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096 <0.000138>
21:16:06.209366 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 12288) = 12288 <0.000040>
21:16:06.209456 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096 <0.000140>
21:16:06.209665 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 12288) = 12288 <0.000044>
21:16:06.209854 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096 <0.000032>
21:16:06.209934 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 12288) = 12288 <0.000034>
21:16:06.210015 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096 <0.000031>
21:16:06.210095 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 12288) = 12288 <0.000038>
21:16:06.210180 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096 <0.000032>
21:16:06.210258 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 12288) = 12288 <0.000035>
21:16:06.210338 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096 <0.000035>
# 这里看起来是curl在终端打印统计信息,基本都在0.02ms左右,耗时都很短
21:16:06.210436 write(2</dev/pts/3<char 136:3>>, "\r", 1) = 1 <0.000031>
21:16:06.210509 write(2</dev/pts/3<char 136:3>>, " ", 1) = 1 <0.000034>
21:16:06.210616 write(2</dev/pts/3<char 136:3>>, "1", 1) = 1 <0.000012>
21:16:06.210675 write(2</dev/pts/3<char 136:3>>, "5", 1) = 1 <0.000036>
...
21:16:06.218121 write(2</dev/pts/3<char 136:3>>, "4", 1) = 1 <0.000029>
21:16:06.218247 write(2</dev/pts/3<char 136:3>>, "8", 1) = 1 <0.000022>
21:16:06.218305 write(2</dev/pts/3<char 136:3>>, ".", 1) = 1 <0.000024>
21:16:06.218396 write(2</dev/pts/3<char 136:3>>, "6", 1) = 1 <0.000023>
21:16:06.218464 write(2</dev/pts/3<char 136:3>>, "M", 1) = 1 <0.000012>
21:16:06.218544 rt_sigaction(SIGPIPE, {sa_handler=SIG_IGN, sa_mask=[PIPE], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7f908423e730}, NULL, 8) = 0 <0.000031>
21:16:06.218655 poll([{fd=5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, events=POLLIN}, {fd=3<UNIX-STREAM:[185295->185296]>, events=POLLIN}], 2, 1000) = 1 ([{fd=5, revents=POLLIN}]) <0.000045>
21:16:06.218807 rt_sigaction(SIGPIPE, NULL, {sa_handler=SIG_IGN, sa_mask=[PIPE], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7f908423e730}, 8) = 0 <0.000021>
21:16:06.218997 rt_sigaction(SIGPIPE, {sa_handler=SIG_IGN, sa_mask=[PIPE], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7f908423e730}, NULL, 8) = 0 <0.000033>
21:16:06.219098 poll([{fd=5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, events=POLLIN|POLLPRI|POLLRDNORM|POLLRDBAND}], 1, 0) = 1 ([{fd=5, revents=POLLIN|POLLRDNORM}]) <0.000040>
# 下一次接收
21:16:06.219204 recvfrom(5<TCP:[172.16.58.146:56690->172.16.58.147:8000]>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 102400, 0, NULL, NULL) = 102400 <0.000238>
21:16:06.219518 write(6</root/rcv.dat>, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096 <0.000045>
strace追踪后,虽然知道会拖慢curl下载,但之前忘记看Window Scaling图了,接收窗口已经满了!。

此次strace没加-f追踪子进程,strace自身的的-o输出也要写文件,是否是write影响,本小节暂没有明确结论,本篇篇幅已经比较长了,后续再尝试定位。(TODO)
- 收获教训:后续定位问题时需要记得先结合各个图综合看下。
3.3.3. 用例2:服务端的发送窗口4096字节
下载速度稍慢,111MB/s,影响较小:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 客户端curl下载
[root@iZbp169scc1yz2vwe6mp31Z ~]# curl 172.16.58.147:8000/test.dat --output rcv.dat
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2048M 100 2048M 0 0 111M 0 0:00:18 0:00:18 --:--:-- 114M
# 客户端查看(截取一次)
[root@iZbp169scc1yz2vwe6mp31Z ~]# ss -ianp -om|grep -A1 8000
tcp ESTAB 1448 0 172.16.58.146:43830 172.16.58.147:8000 users:(("curl",pid=39336,fd=5)) timer:(keepalive,46sec,0)
skmem:(r2816,rb5633575,t0,tb87040,f1280,w0,o0,bl0,d11) ts sack
cubic wscale:7,7 rto:201 rtt:0.328/0.162 ato:40 mss:1448 pmtu:1500 rcvmss:1448 advmss:1448 cwnd:10 bytes_sent:90 bytes_acked:91 bytes_received:1733822072 segs_out:68289 segs_in:1216988 data_segs_out:1 data_segs_in:1216986 send 353170732bps lastsnd:13499 pacing_rate 705534824bps delivery_rate 54641504bps delivered:2 app_limited rcv_rtt:6.014 rcv_space:1751720 rcv_ssthresh:4812120 minrtt:0.212 snd_wnd:31872
# 服务端查看(截取一次)
[root@iZbp169scc1yz2vwe6mp30Z ~]# ss -ianp -om|grep -A1 8000
tcp ESTAB 0 65160 172.16.58.147:8000 172.16.58.146:43830 users:(("python",pid=37559,fd=4)) timer:(on,003ms,0)
skmem:(r0,rb131072,t0,tb4096,f3192,w66440,o0,bl0,d0) ts sack
cubic wscale:7,7 rto:201 rtt:0.271/0.033 ato:40 mss:1448 pmtu:1500 rcvmss:536 advmss:1448 cwnd:113 ssthresh:106 bytes_sent:1445870120 bytes_retrans:15056 bytes_acked:1445789904 bytes_received:90 segs_out:1014861 segs_in:56878 data_segs_out:1014860 data_segs_in:1 send 4830228782bps lastrcv:10919 pacing_rate 5793602208bps delivery_rate 48468616bps delivered:1014816 busy:9156ms rwnd_limited:72ms(0.8%) sndbuf_limited:1ms(0.0%) unacked:45 retrans:0/11 dsack_dups:11 rcv_space:14600 rcv_ssthresh:31820 minrtt:0.136 snd_wnd:4812160
客户端抓包:

服务端抓包:

分析:
1、查看窗口规模图,客户端接收窗口是比较大的,而服务端受限于发送窗口,发送数据量一直在376和65160之间交替。
- 但是客户端下载还是比较快的,可以正常下载完成。
- 服务端发送时,只要收到客户端ACK,就可以向发送缓冲区填充数据(内存级别操作的间隔)进行发送;而用例3限制客户端接收缓冲区,客户端处理完数据后还需要一个
RTT的时间,才能等服务端发数据过来。
2、跟踪一个包结合各个图,展开查看详情,时间序列和RTT:
- 间隔一段时间就会有一段时间的平顶,10ms左右。

3、跟踪一个包展开查看详情,窗口规模:

3.3.4. 用例3:客户端的接收窗口4096字节
下载很慢,5.21MB/s。且抓包太大,手动打断了下载。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 客户端curl下载,时间预估需要6min31s
[root@iZbp169scc1yz2vwe6mp31Z ~]# curl 172.16.58.147:8000/test.dat --output rcv.dat
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
23 2048M 23 475M 0 0 5350k 0 0:06:31 0:01:31 0:05:00 5457k
# 客户端查看(截取一次)
[root@iZbp169scc1yz2vwe6mp31Z ~]# ss -ianp -om|grep -A1 8000
tcp ESTAB 0 0 172.16.58.146:41276 172.16.58.147:8000 users:(("curl",pid=39411,fd=5)) timer:(keepalive,49sec,0)
skmem:(r0,rb4096,t0,tb87040,f0,w0,o0,bl0,d1) ts sack
cubic wscale:7,2 rto:201 rtt:0.317/0.134 ato:40 mss:1448 pmtu:1500 rcvmss:520 advmss:1448 cwnd:10 bytes_sent:90 bytes_acked:91 bytes_received:60902608 segs_out:96347 segs_in:117124 data_segs_out:1 data_segs_in:117122 send 365425868bps lastsnd:10675 pacing_rate 730275800bps delivery_rate 30324600bps delivered:2 app_limited busy:1ms rcv_rtt:0.192 rcv_space:2600 rcv_ssthresh:1040 minrtt:0.308 snd_wnd:31872
# 服务端查看(截取一次)
[root@iZbp169scc1yz2vwe6mp30Z ~]# ss -ianp -om|grep -A1 8000
tcp ESTAB 0 17160 172.16.58.147:8000 172.16.58.146:41276 users:(("python",pid=37559,fd=4)) timer:(on,003ms,0)
skmem:(r0,rb131072,t0,tb87040,f2040,w59400,o0,bl0,d0) ts sack
cubic wscale:2,7 rto:201 rtt:0.221/0.044 ato:40 mss:520 pmtu:1500 rcvmss:520 advmss:1448 cwnd:10 bytes_sent:39834288 bytes_retrans:520 bytes_acked:39832728 bytes_received:90 segs_out:76606 segs_in:63558 data_segs_out:76605 data_segs_in:1 send 188235294bps lastrcv:7011 pacing_rate 374985912bps delivery_rate 42448976bps delivered:76604 busy:7011ms rwnd_limited:7011ms(100.0%) unacked:2 retrans:0/1 dsack_dups:1 rcv_space:14600 rcv_ssthresh:31820 notsent:16120 minrtt:0.13 snd_wnd:1040
客户端抓包:

服务端抓包:

分析:
- 下载特别慢。
RTT图中,RTT基本都在0.17ms及以上(和用例2中RTT差别不大),客户端接收窗口限制在500~1050字节。- 相对而言,用例2中客户端接收窗口在
2.5~3.5MB,能够让服务端一个RTT内发送更多数据,从而下载速度更快
- 相对而言,用例2中客户端接收窗口在
- 从
Window Scaling图可看到数据发送受限于客户端接收窗口(发包打满了绿线)
4. 小结
实验验证对比了默认参数、限制服务端发送窗口、限制客户端接收窗口三种情况的数据传输。
另外很多细节暂未深入,后续可结合perf、eBPF跟踪一些事件。比如内存不足的情况,如tracepoint:sock_exceed_buf_limit,几个参考链接值得多回顾学习。
下一步结合tc模拟不同网络情况,进行实验对比。