TCP发送接收过程(三) -- 实验观察TCP性能和窗口、Buffer的关系(下)
通过tc模拟异常实验观察TCP性能和窗口、Buffer的关系。
1. 引言
上篇进行了基本的TCP发送接收窗口调整实验,实际情况中则可能会碰到网络丢包、网络延迟、乱序等各种情况,本篇借助tc进行异常情况模拟,观察TCP发送接收的表现。
2. tc说明
几篇不错的tc相关介绍和使用参考文章:
2.1. 基本介绍
TC(Traffic Control)是Linux内核中的流量控制子系统,而本文中使用的tc是与之对应的用户态工具,包含在iproute2包中。
tc包含如下作用:
- 流量整形(Shaping): 限制网络接口的传输速率,平滑突发流量,避免拥塞,只用于网络出方向(egress)。
- 流量调度(Scheduling):按优先级分配带宽(
reorder控制优先级),确保关键业务的传输优先级。只用于网络出方向(egress)。 - 流量策略(Policing): 根据到达速率决策接收还是丢弃数据包(如限制 DDoS 攻击),用于网络入方向(ingress)。
- 流量过滤(Dropping/Filtering): 根据规则(如 IP 地址、端口、协议)对流量分类,并施加不同的策略(如限速、丢弃),可以用于出入两个方向。
tc的操作依赖 3个核心组件:
qdisc(queueing discipline),队列规则,决定了数据包如何排队和发送- 支持多种规则,如
pfifo(pure First In, First Out queue)、pfifo_fast(默认规则)、htb(hierarchy token bucket,分层令牌桶)、tbf(token buffer filter,令牌桶过滤器)、fifo - qdisc是一个整流器/整形器(shaper),可以包含多个
class,不同class可以应用不同的策略。 - qdisc对外暴露两个回调接口
enqueue和dequeue,分别用于数据包入队和数据包出队,而具体的排队算法实现则在qdisc内部隐藏。- 不同的
qdisc实现在Linux内核中实现为不同的内核模块,在系统的内核模块目录里可以查看前缀为sch_的模块。 - 确认有哪些模块,可看:
ls -ltrh /usr/lib/modules/5.14.0-503.14.1.el9_5.x86_64/kernel/net/sched/sch_*。可另外安装kernel-modules-extra,其中会包含sch_netem模块。 - 各种qdisc类型说明,可查看man手册。
- 不同的
- 支持多种规则,如
class(类别),将流量分类,每类流量可分配不同的带宽或优先级- 与 htb 等
qdisc结合使用,实现带宽分级管理
- 与 htb 等
filter(过滤器),根据规则对流量进行分类filter也叫分类器(classifier),需要挂载/附着(attach)到class 或 qdisc上- 用于对网络设备上的流量进行分类,并将包分发(dispatch)到前面定义的不同 class
使用步骤:
- 1、为网络设备 创建一个qdisc
- qdisc需要附着/挂载(attach)到某个网络接口
- 2、创建流量类别(class),并附着(attach)到
qdisc - 3、创建filter,并attach到
qdisc - 4、另外 可以给filter添加action,比如将选中的包丢弃(drop)
- 大约15年时,
TC框架加入了Classifier-Action机制。 classifier即上面的filter,当数据包匹配到特定filter后可执行该filter所挂载的actions对数据包进行处理。
- 大约15年时,
class可以理解为qdisc的载体,它还可以包含子class与qdisc,最终形成的是一个以 root qdisc 为根的 树。当数据包流入最顶层qdisc时,会层层向下递归进行调用。
简要处理过程说明:
- 父对象(
qdisc或class)的enqueue回调被调用时,其上挂载的filter会依次调用,直到一个filter匹配成功(若filter上还添加了action则执行action); - 然后将数据包入队到
filter所指向的class,具体实现则是调用class所配置的qdisc的enqueue函数; - 没有成功匹配
filter的数据包则分类到默认的class中。
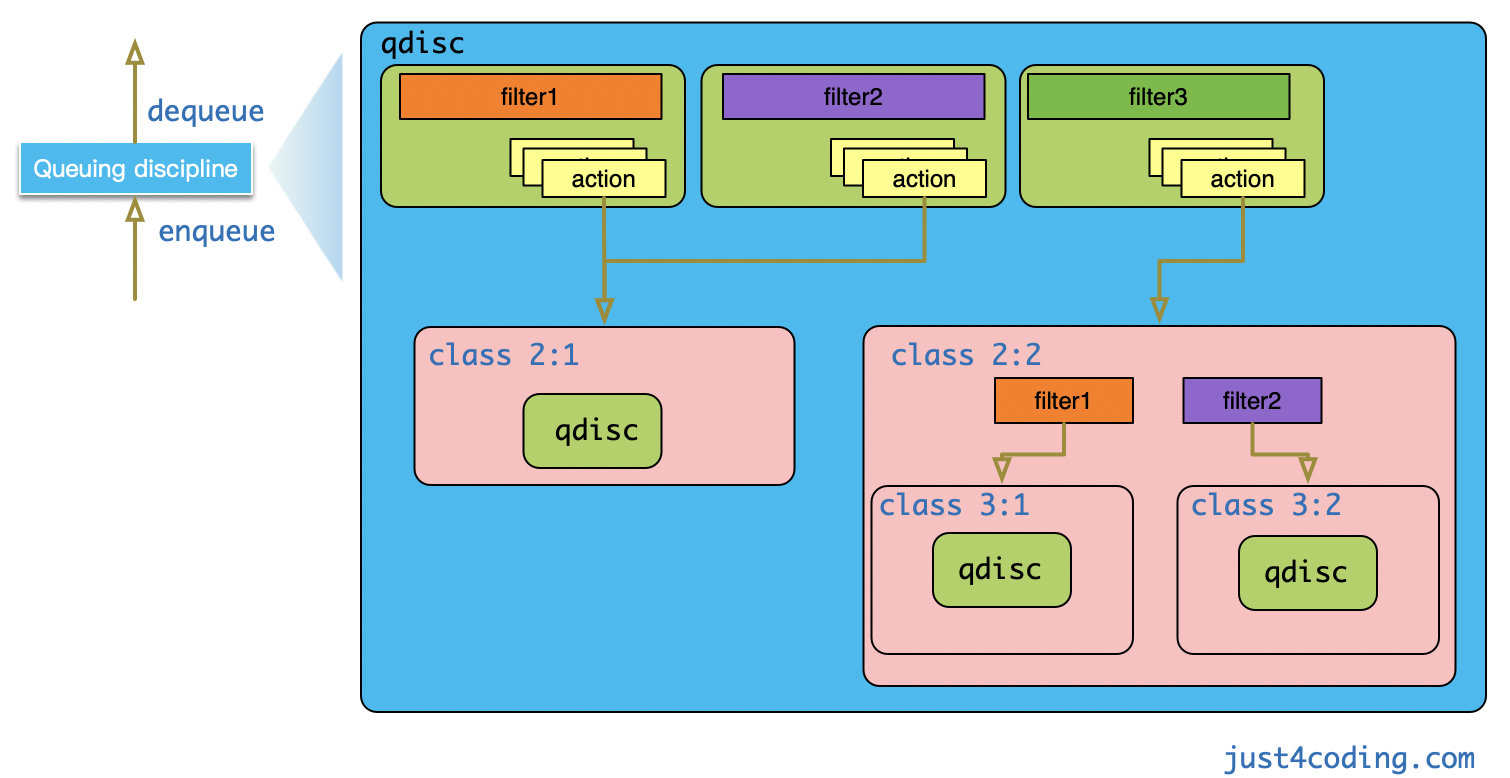
扩展阅读:Linux-Traffic-Control-Classifier-Action-Subsystem-Architecture.pdf,介绍了TC Classifier-Action子系统的架构。
- 可了解到其和
netfilter的位置关系:数据流入 ->ingress TC->netfilter->egress TC-> 数据流出。见下图示意。 - 关于
netfilter可见 TCP发送接收过程 – 学习netfilter和iptables 中的学习梳理。另外看了下当前自己Rocky Linux环境的firewalld防火墙后端,也默认nftables了(弃用了iptables):FirewallBackend=nftables。
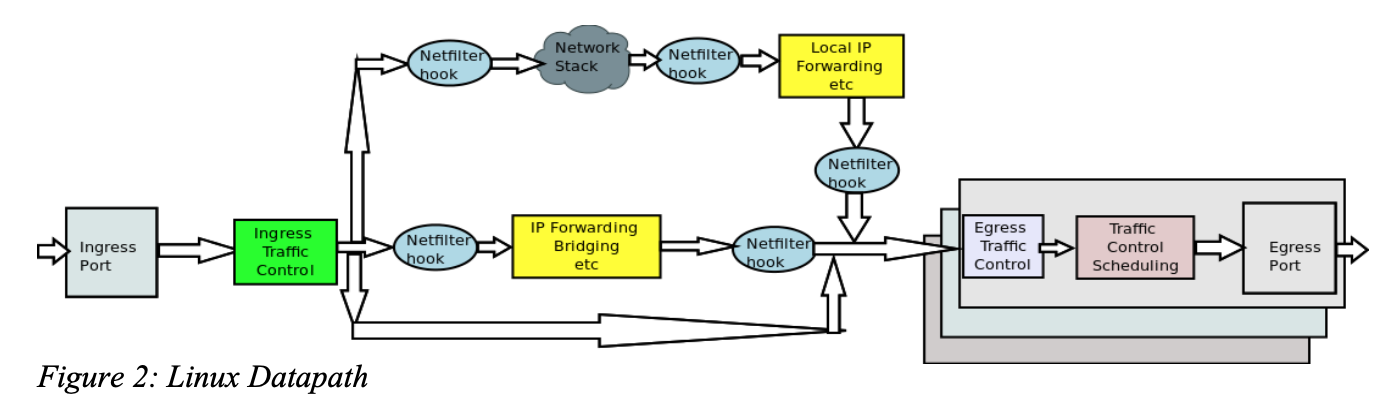
之前看netfilter时的数据流示意图也可以看到tc qdisc的位置:

出处 Wikipedia
{kind=link}
2.2. 使用示例
一个网络接口有两个默认的qdisc锚点(挂载点),入方向的锚点叫做ingress, 出方向叫做root。
- 入方向的
ingress功能比较有限,不能挂载其他的class,只是做为Classifier-Action机制的挂载点。
qdisc和class的 标识符叫做handle(下面示例会用到), 它是一个32位的整数,分为major和minor两部分,各占16位,表达方式为:m:n,m或n省略时,表示0。
m:0一般表示qdisc- 对于
class:minor一般从1开始,major则用它所挂载qdisc的major号 root qdisc的handle一般使用1:0表示,ingress一般使用ffff:0表示。
下面
tc用到的netem需要先安装加载sch_netem内核模块(yum install kernel-modules-extra,需确认内核小版本也是一致的、modprobe sch_netem)。
之前 实验bcc网络工具时就踩过坑了,所以本次安装Rocky Linux时/boot分区分的空间足够大。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 增加规则
# dev enp4s0,附着到enp4s0网口
# root,网卡的根级规则
# netem(Network Emulator),内核的网络模拟模块
# delay 2ms,延时2ms
tc qdisc add dev enp4s0 root netem delay 2ms
# 修改
tc qdisc change dev enp4s0 root netem delay 3ms
# 查看
tc qdisc show dev enp4s0
# 删除
tc qdisc del dev enp4s0 root
# 一些查看命令
tc qdisc ls
tc class ls
tc filter ls
# 查看统计信息
tc -s qdisc show dev enp4s0
tc -s class show dev enp4s0
这里说明下netem,它是一个classless类型的qdisc,表示不能包含class,只能attach到root根节点上。用于控制 出向包,可以增加delay、loss、dup等。
1
2
3
4
5
[root@iZbp1dkjrwztxfyf6vufrvZ ~]# man tc
...
CLASSLESS QDISCS
netem
Network Emulator is an enhancement of the Linux traffic control facilities that allow one to add delay, packet loss, duplication and more other characteristics to packets outgoing from a selected network interface.
下面是netem网络模拟模块的简单示例,其他模块和层级规则使用,可见:Linux tc qdisc的使用案例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 创建qdisc和filter规则,并分配句柄用于其他规则引用
# root,表示将此队列规则(qdisc)添加到接口的根节点(即所有流量的默认路径)
# `handle 1:` 为该 qdisc 分配句柄 1:,后续的子规则可通过此句柄引用(例如 parent 1:)
# netem,使用 netem(网络模拟器)工具,用于模拟网络延迟、丢包、重排序等特性
# reorder 25% 50%:25% 的数据包会被随机重排序(即数据包的顺序被打乱),50% 表示重排序的最大延迟
tc qdisc add dev bond0 root handle 1: netem delay 10ms reorder 25% 50% loss 0.2%
# 引用上面创建的qdisc规则,并进一步增加控制
# `parent 1:` 表示此 qdisc 是之前 netem qdisc(句柄 1:)的子节点。
# netem 会先处理流量,再传递给 tbf
# `handle 2:` 为该 qdisc 分配句柄 2:,用于后续管理或调试。
# tbf,使用 tbf(token buffer filter,令牌桶过滤器)算法,用于 限制带宽 和 控制突发流量。
# rate 1mbit,将带宽限制为 1 Mbps
# burst 32kbit,允许突发流量的最大值为 32 Kbit(即短时间内的瞬时流量可超过 1 Mbps,但总和不能超过 rate × latency + burst)。
# 突发流量的计算公式:burst = rate × (latency + burst_time)
# latency 10ms,设置 最大延迟为 10ms,即数据包在队列中等待的时间不能超过 10ms
# 该参数与 tbf 的令牌桶机制结合,用于控制流量整形的精度
tc qdisc add dev bond0 parent 1: handle 2: tbf rate 1mbit burst 32kbit latency 10ms
3. 实验说明
3.1. 环境和步骤
环境和步骤和上篇一样。起2个阿里云ECS(2核2G)
- 系统:Rocky Linux release 9.5 (Blue Onyx)
- 内核:5.14.0-503.35.1.el9_5.x86_64
- 注意需要
yum install kernel-modules-extra、modprobe sch_netem以使用netem- ECS里安装的内核小版本不一样,需要
dnf update升级下内核到5.14.0-503.40.1.el9_5,并重启
- ECS里安装的内核小版本不一样,需要
步骤说明:
- 服务端:
python -m http.server起http服务,监听8000端口dd一个2GB文件用于测试:dd if=/dev/zero of=test.dat bs=1G count=2
- 客户端:
curl请求下载文件curl "http://xxx:8000/test.dat" --output test.dat
- 抓包:
tcpdump -i any port 8000 -s 100 -w normal_client.cap -v- 先两端都抓包对比下,服务端抓包:
tcpdump -i any port 8000 -s 100 -w normal_server.cap -v
3.2. 用例
用例:参考下述博文,里面的场景已经比较充分了,其中的20%比例降到10%,生产环境5%丢包已经算比较严重了。
具体用例:
- 0、基准用例。直接复用上篇默认参数的场景结果即可,不用重复实验
- 1、tc叠加客户端延时:
2mstc qdisc add dev enp4s0 root netem delay 2ms
- 2、tc叠加客户端延时:
100mstc qdisc change dev enp4s0 root netem delay 100ms(之前已有规则,修改参数即可)
- 3、tc模拟服务端丢包:
1%tc qdisc add dev enp4s0 root netem loss 1%(需要先清理之前的规则再添加新规则)
- 4、tc模拟服务端丢包:
10%tc qdisc change dev enp4s0 root netem loss 10%
- 5、tc模拟服务端包重复:
1%tc qdisc add dev enp4s0 root netem duplicate 1%
- 6、tc模拟服务端包重复:
10%tc qdisc change dev enp4s0 root netem duplicate 10%
- 7、tc模拟服务端包损坏:
1%tc qdisc add dev enp4s0 root netem corrupt 1%
- 8、tc模拟服务端包损坏:
10%tc qdisc change dev enp4s0 root netem corrupt 10%
- 9、tc模拟服务端包乱序:
1%的包比例乱序、delay 100ms、相关性 10%tc qdisc add dev enp4s0 root netem delay 100ms reorder 99% 10%
- 10、tc模拟服务端包乱序:
20%的包比例乱序、delay 100ms、相关性 10%tc qdisc change dev enp4s0 root netem delay 100ms reorder 80% 10%
- 11、tc限制服务端带宽:
50MBps(即400Mbps)tc qdisc add dev enX0 root tbf rate 400mbit burst 10mbit latency 10ms- 可以
ll /lib/modules/5.14.0-503.40.1.el9_5.x86_64/kernel/net/sched/sch_*看到有sch_tbf.ko.xz模块
- 12、tc限制服务端带宽:
1MBps(即8Mbps)tc qdisc add dev enX0 root tbf rate 8mbit burst 200kbit latency 10ms
3.2.1. tc reorder用法说明
这里先解释说明上述的reorder用法:tc qdisc add dev enp4s0 root netem delay 100ms reorder 99% 10%。
直接看下man tc-netem:
- 用法:
REORDERING := reorder PERCENT [ CORRELATION ] [ gap DISTANCE ]- 且使用reorder时必须指定
delay选项
- 且使用reorder时必须指定
- gap参数说明
- 示例1:
reorder 25% 50% gap 5(假设指定delay 10ms)- 前4个(
gap-1)包延迟10ms发送,剩下的一个包有25%的概率立即发送;每gap个包重复该过程。(相关性参数见下面的说明) - 或者说剩下的那个包有
75%的概率延迟发送
- 前4个(
- 示例2:
reorder 25% 50%25%的包立即发送,剩下的包延迟10ms发送gap默认1,套用上面的逻辑,gap-1即0个包延迟发送,(每个包)25%的概率立即发送,75%的概率延迟发送。- (和上面用例中给的99%说法情况一致,1%的包乱序)。
- 示例1:
CORRELATION相关系数说明:前一个事件(此处为乱序)和下一个事件的相关性,会影响下一个事件出现相同表现的概率- 若前一个包乱序,下一个包的乱序概率会变为
1% + (100% - 1%) * 10% = 10.9% - 若前一个包未乱序,下一个包的乱序概率会变为
1% * (1 - 10%) = 0.9% - delay、loss、reorder、corrupt等都支持相关性设置
0%表示完全独立(默认);100%则跟上一个状态完全相同:概率1% + (100% - 1%)*100% = 100%(一般不会设置100%)
- 若前一个包乱序,下一个包的乱序概率会变为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# man tc-netem
SYNOPSIS
tc qdisc ... dev DEVICE ] add netem OPTIONS
OPTIONS := [ LIMIT ] [ DELAY ] [ LOSS ] [ CORRUPT ] [ DUPLICATION ] [ REORDERING ] [ RATE ] [ SLOT ]
REORDERING := reorder PERCENT [ CORRELATION ] [ gap DISTANCE ]
...
netem OPTIONS
reorder
to use reordering, a delay option must be specified. There are two ways to use this option (assuming 'delay 10ms' in the options list).
reorder 25% 50% gap 5
in this first example, the first 4 (gap - 1) packets are delayed by 10ms and subsequent packets are sent immediately with a probability of 0.25
(with correlation of 50% ) or delayed with a probability of 0.75. After a packet is reordered, the process restarts i.e. the next 4 packets are
delayed and subsequent packets are sent immediately or delayed based on reordering probability. To cause a repeatable pattern where every 5th
packet is reordered reliably, a reorder probability of 100% can be used.
reorder 25% 50%
in this second example 25% of packets are sent immediately (with correlation of 50%) while the others are delayed by 10 ms.
查看参考资料,reorder和delay的组合有2种写法:
tc qdisc add dev eth0 root netem reorder 80% delay 50mstc qdisc add dev eth0 root netem delay 50ms reorder 80%
疑问:delay的位置不同会有不同效果吗?
找一些参考文章,并让DeepSeek、通义给结果,得到的结论有冲突。下面进行实验。
3.2.2. tc reorder和delay先后顺序
实验方式:在服务端增加reorder对应的qdisc,并在客户端ping进行观察延时情况。
这里只贴下实验结论:
| 用例 | tc结果 | ping表现 |
|---|---|---|
| 1、reorder 80% delay 50ms | delay 50ms reorder 80% gap 1 | 接近20%概率延迟(10次出现2次) |
| 2、delay 50ms reorder 80% | delay 50ms reorder 80% gap 1 | 表现同上 |
| 3、reorder 80% gap 5 delay 50ms | delay 50ms reorder 80% gap 5 | 5次出现4次延迟,1次不延迟 |
| 4、delay 50ms reorder 80% gap 5 | delay 50ms reorder 80% gap 5 | 同上 |
| 5、reorder 80% gap 8 delay 50ms | delay 50ms reorder 80% gap 8 | 8次出现7次延迟,1次不延迟 |
说明:
- 上述表格,用例列中省略了共同的
tc qdisc add dev eth0 root netem;结果列中则省略了前面的qdisc netem 800d: root refcnt 2 limit 1000 - 可看到不管
reorder和delay的顺序如何,表现相同 (gap 5顺序也可以调整) 。并不会出现LLM说的 “基础延迟再叠加乱序包延迟的情况(乱序包出现2倍延迟)”。 gap非默认值1时,近似会出现固定的gap-1次延迟,剩余一次则根据设置的比例作为立即发送的概率。
步骤和完整结果信息可见:tc_reorder_ping_test.md。
3.3. 测试脚本和使用说明
tc命令和抓包都按脚本选项的形式输入,便于分情况测试。
使用说明:
- 将下述测试脚本在客户端、服务都放一份。
- 手动选择对应的选项、以及抓包选项;而后触发下载,下载结束或者打断后,ctrl+c打断抓包,完成一条用例测试。
1、tc命令输入。完整脚本内容可见:tc_command.sh。
case1、case2在客户端执行;其他case在服务端执行。不同规则脚本会先做清理再新增。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[root@iZbp1dkjrwztxfyf6vufrvZ ~]# sh tc_command.sh
================= tc 测试工具菜单 =================
1. 添加客户端延时 2ms
2. 修改客户端延时为 100ms
3. 模拟服务端丢包 1%
4. 修改丢包率为 10%
5. 模拟服务端包重复 1%
6. 修改包重复率为 10%
7. 模拟服务端包损坏 1%
8. 修改包损坏率为 10%
9. 模拟服务端包乱序:1% 乱序,延迟 100ms,相关性 10%
10. 修改乱序率为 20%
11. 限制服务端带宽为 400Mbps (50MBps)
12. 限制服务端带宽为 8Mbps (1MBps)
13. 清除所有规则
0. 退出
==================================================
请输入选项编号:
tc_command.sh部分内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#!/bin/bash
execute_choice() {
case $1 in
1) clear_rules; tc qdisc add dev $DEV root netem delay 2ms;;
2) tc qdisc change dev $DEV root netem delay 100ms;;
3) clear_rules; tc qdisc add dev $DEV root netem loss 1%;;
4) tc qdisc change dev $DEV root netem loss 10%;;
5) clear_rules; tc qdisc add dev $DEV root netem duplicate 1%;;
6) tc qdisc change dev $DEV root netem duplicate 10%;;
7) clear_rules; tc qdisc add dev $DEV root netem corrupt 1%;;
8) tc qdisc change dev $DEV root netem corrupt 10%;;
9) clear_rules; tc qdisc add dev $DEV root netem delay 100ms reorder 99% 10%;;
10) tc qdisc change dev $DEV root netem delay 100ms reorder 80% 10%;;
11) clear_rules; tc qdisc add dev $DEV root tbf rate 400mbit burst 10mbit latency 10ms;;
12) clear_rules; tc qdisc add dev $DEV root tbf rate 8mbit burst 200kbit latency 10ms;;
13) clear_rules;;
0) echo "退出脚本"; exit 0;;
*) echo "无效选项" ;;
esac
}
2、抓包命令输入。完整脚本内容可见:capture.sh。
抓包:客户端执行sh capture.sh cli 1、服务端执行sh capture.sh server 1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[root@iZbp1dkjrwztxfyf6vufrvZ ~]# sh capture.sh
用法: capture.sh <capture_type> <scenario_number>
capture_type: cli 或 server
scenario_number: 1 到 12 的整数,代表以下场景:
--------------------
1. 客户端延时 2ms
2. 客户端延时 100ms
3. 服务端丢包 1%
4. 服务端丢包 10%
5. 服务端包重复 1%
6. 服务端包重复 10%
7. 服务端包损坏 1%
8. 服务端包损坏 10%
9. 服务端包乱序 1%
10. 服务端包乱序 20%
11. 限制带宽 400Mbps (50MBps)
12. 限制带宽 8Mbps (1MBps)
--------------------
capture.sh部分内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#!/bin/bash
# 定义场景与描述的映射关系
declare -A SCENARIOS=(
[1]="delay-2ms"
[2]="delay-100ms"
[3]="loss-1"
[4]="loss-10"
[5]="duplicate-1"
[6]="duplicate-10"
[7]="corrupt-1"
[8]="corrupt-10"
[9]="reorder-1"
[10]="reorder-20"
[11]="bd-400mb"
[12]="bd-8mb"
)
# 执行抓包命令
echo "开始抓包... (请按 Ctrl+C 停止)"
tcpdump -i any port $PORT -s 100 -v -w $CAPTURE_FILE
4. 实验结果和分析
1、各用例的客户端下载情况,可见:tc_experiment_result.md。
2、抓包文件则可见:ecs_tc_case。
4.1. 结果汇总
说明:
- 下述
RTT是按分布最多区间大概估算的值,仅做对比参考(计算BDP应该动态取指定时间点的RTT)。 - 按上篇所述,实验的带宽按
2Gbps作为基准。 - 下面小节中的多场景对比图均为
svg图片,可在新标签打开查看大图。
暂时只统计客户端侧抓包。
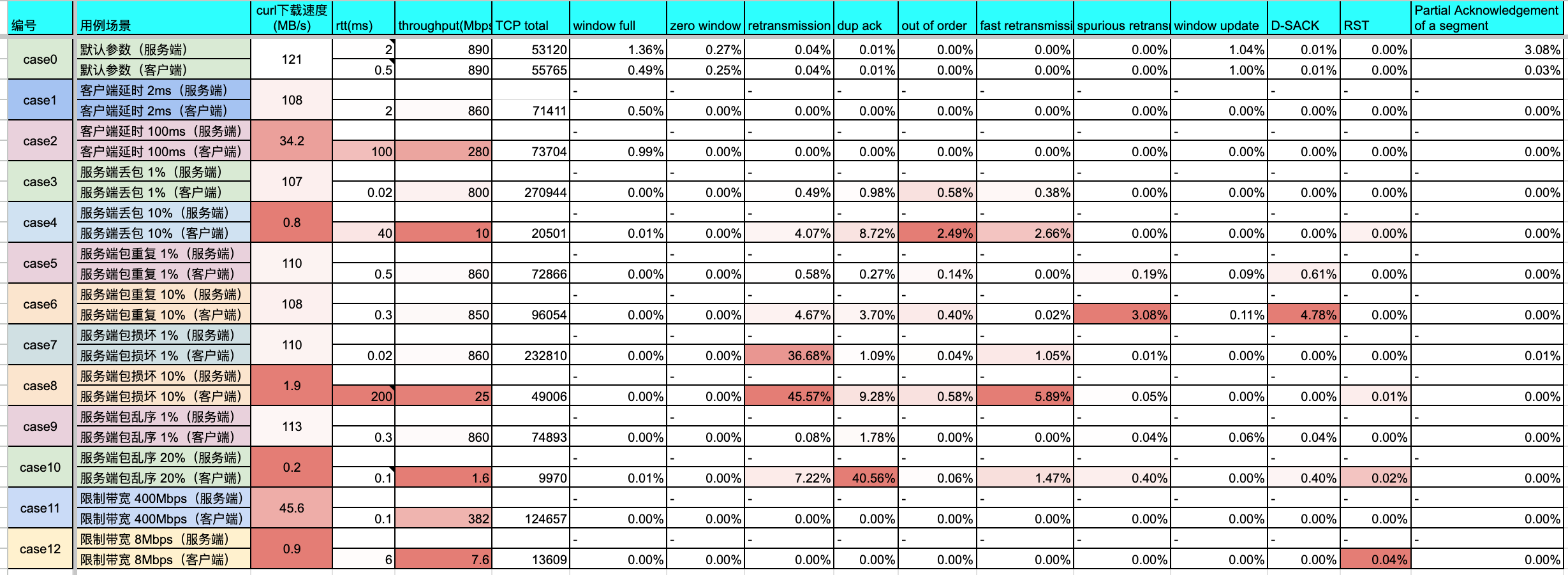
总体分析:
- 1、本实验中,服务端丢包、包损坏、包乱序出现概率高时(如
10%),对客户端下载影响特别大,客户端网络延时影响次之;- 少量异常(
1%)则有轻微速度下滑,TCP能容忍该部分异常。
- 少量异常(
- 2、服务端包重复,对下载影响并不大,就算达到
10%也差不多; - 3、限制服务端带宽能有效限制下载速度(当然)。
4.1.1. RTT对比

分析:
- 按上面表格所统计的,
0.5ms作为基准场景下的延时 - 叠加客户端延时,则基本上是直接对RTT横轴上浮了
2ms和100ms - 服务端丢包严重时,RTT突刺比较多,且突刺达到
40ms - 服务端包重复,对RTT影响不大,基本还是在
0.3~0.5ms - 服务端包损坏严重时,对RTT 影响较大,达到
200ms - 服务端乱序严重时,RTT突刺比较多,且突刺达到
40ms。和丢包严重的表现差不多。 - 限制服务端带宽,限制不太过分(
2Gbps->400Mbps)时RTT还下降了,太过分(8Mbps)则RTT增加(0.5ms->6ms)。
4.1.2. Throughput对比

分析:
- 基准吞吐量为
890Mbps,有效负载(绿线)和吞吐量(棕线)基本是重合的 - 客户端延时大时(
100ms),吞吐量降低不少(890Mbps->280Mbps)且有10%左右抖动 - 服务端丢包对吞吐量影响很明显,
1%丢包吞吐就已经快下降10%了(890Mbps->800Mpbs),到10%丢包时已经没法看了,到了10Mbps。 - 服务端包重复,影响不大
- 服务端包损坏严重时,吞吐量也受到较大影响,
890Mbps->25Mbps - 服务端乱序严重(
20%)时,对吞吐量 影响极大,直接到了1.6Mbps - 限制服务端带宽能有效限制吞吐量,限制在
20%带宽(400Mbps/2Gbps)时,吞吐量降到42%;带宽0.3%,吞吐量则降到0.85%
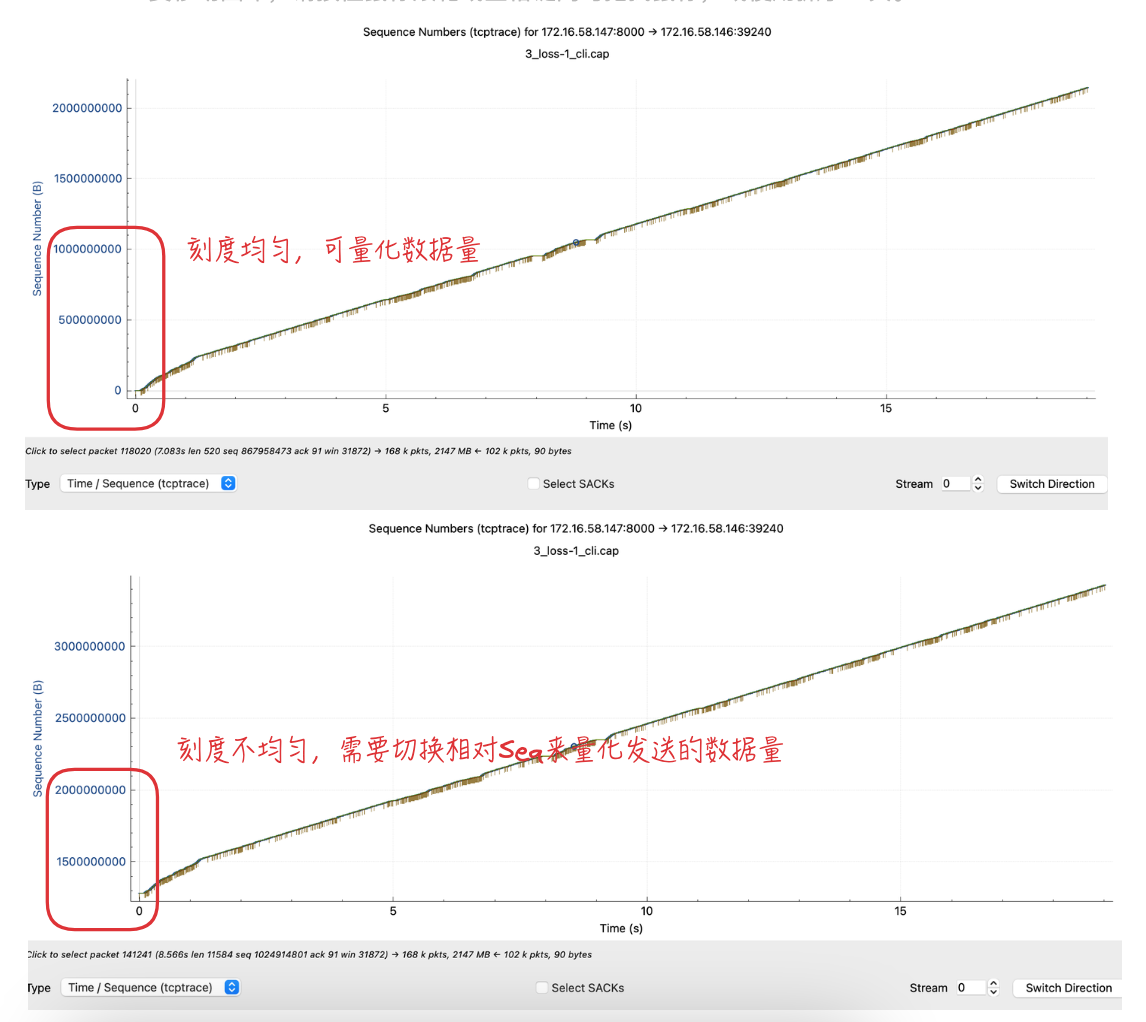
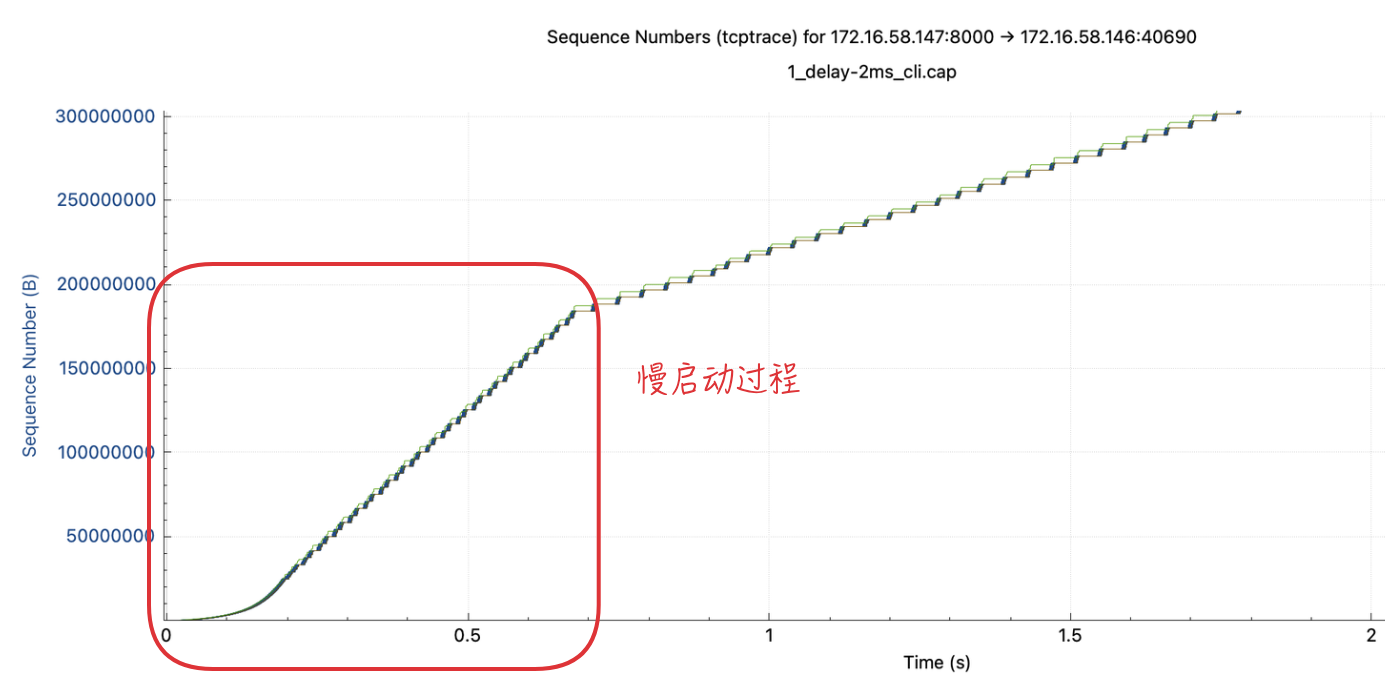
4.1.3. Time/Sequence对比(tcptrace)

分析:
- 从各个用例的
Time/Sequence中,都能看到开始时斜率由高到低,对应慢启动->拥塞避免过程。 - 客户端延时场景,数据发送速度(斜率)受到影响,延时越大斜率越小。
- 从图中可看出,基准场景
10s位置时大概发了1.3GB数据;delay 2ms场景大概1.2GB左右;delay 10ms则只有400MB不到。
- 从图中可看出,基准场景
- 服务端丢包场景
1%场景可看到10s发了2.4GB(嗯?重新打开抓包文件看,只有1.2GB,形状是一样的,只有纵坐标数值不同,TODO待确认)- 同样的情况在
5_duplicate-1_cli.cap包重复场景 里也出现了。 - 经过对比确认:右键切换
Relative/Absolute Sequence Number后,纵坐标有变化,上面总图中的3_loss-1_cli.cap和5_duplicate-1_cli.cap是需要切换到相对Seq才便于查看实际发送数据量。但是相对和绝对Seq从界面没有明显区分,只能以纵坐标从0到第一次数字之间的刻度个数来分辨,两个数字刻度间均匀则为相对Seq。 - 所以10s对应的实际数据量是
1.2GB。
- 同样的情况在
- 丢包
10%时,由于丢包严重,出现了很多水平的棕线,很大一部分原因是由于丢包导致ACK未收到。
- 服务端包重复,
1%和上面丢包场景所述的一样,切换相对Seq后可看到10s发送数据量大概在1.2GB,和基准场景1.3GB相差不大。10%场景从Time/Seq看数据发送速度也差不多。 - 服务端包损坏严重时,ACK线基本水平,Seq也发不动了。
- 服务端乱序,
1%时Seq线比较正常,20%时,10s只发了2MB数据(切换相对Seq查看)。 - 限制服务端带宽,图形比较稳定,接收窗口一直在Seq线的上面。
来放大图形看一些细节。
1)客户端延时 2ms场景,可看下慢启动过程。
2)从客户端延时 100ms场景截取一段来观察下 接收窗口变化。
- 由于客户端加了
delay 100ms,其ACK应答在100.05ms左右,ACK应答之后,客户端的接收窗口才跟着上升- 数据发送受接收窗口限制;作为对比,基准场景的接收窗口则完全足够,绿线都在蓝点上面。
11856和11865号包之间,服务端都没有发送数据(TCP Len为0),都是客户端的ACK,RTT在100ms左右,对应在Time/Seq图则是向上的棕线。

3)服务端丢包 10%场景,看下 丢包图形细节。
- 红色的线表示
SACK(Selective ACK,选择性确认),表示这一段Sequence Number已经收到了,再配合棕色线的ACK,那么发送端就会知道,在中间这段空挡的包丢了(红色线和黄色线纵向的空白)。SACK允许接收方告诉发送方哪些数据块已经成功接收,这样发送方就可以只重传丢失的部分,而不是整个窗口的数据。- 蓝色的线表示又重新传输了一遍,如下图所示。
- 放大查看蓝色方框那部分图形。
红色线SACK和棕色线之间的那部分丢包,SACK机制择机处理重传。- 查看这个重传包对应的具体包信息,可见此处是
fast retransmission。
- 查看这个重传包对应的具体包信息,可见此处是

4)服务端包乱序 20%场景,可看到多次SACK和Dup ACK,如下所示看下 Dup ACK和图形对应关系。
- 看下ACK(
棕线)停滞的那部分图形,中间大概间隔了50ms。有大量SACK红线,但这些红色和ACK线有一段相同的缺口,表示这部分包一直没收到,通知服务端 需要重传。- 红线表示的包,可以看下抓包详情进行对应。
- 高度相同的那些
SACK对应到Dup ACK,每个都有编号,可看到最后是Dup ACK #10,所以1个原始Dup+10个Dup共11个,和图形是一致的。

4.1.4. Window Scaling对比

分析:
- 基准情况下,客户端接收窗口一直在上面,最大有
5MB左右。(蓝线和绿线的比例尺是一致的) - 客户端延时比较大时(
100ms),Byte in fight在途字节数一直较高,没怎么下来过。- 在途数据基本打满客户端接收缓冲区,图上在途数据在
3~4MB左右。 - 上篇提到过
- 网络基准带宽
2Gbps - BDP需要动态计算。若RTT为
101ms则BDP为2Gbps * 101/1000 / 8 = 25MB;若RTT为2ms则BDP为0.125MB。 - 若
在途字节数 > BDP,可能引发拥塞或丢包;若在途字节数 < BDP,链路未充分利用
- 网络基准带宽
- 从上述结果汇总表中可看到,相对于其他场景,
window full的比例0.5%和0.99%还是算高的(基准场景也不低)。
- 在途数据基本打满客户端接收缓冲区,图上在途数据在
- 服务端丢包,接收窗口都不是瓶颈
- 服务端包重复,接收窗口也够用
- 服务端包损坏时,客户端接收窗口
2.2MB,而在途数据量有时在6.5MB~9MB左右,还超出了接收窗口(Why? TODO分析) - 服务端乱序,接收窗口也够用
- 限制服务端带宽,接收窗口也够用,在途数据受限明显
5. 小结
通过tc模拟网络异常实验观察TCP性能和窗口、Buffer的关系,并分析对比了各场景的结果。