容器网络(一) -- 本机网络通信 和 容器网络基础-veth
梳理学习容器网络
1. 引言
Kubernetes学习实践 前几篇中了解了基本的K8s操作,终于可以开始梳理容器网络了,这也是之前的核心出发点之一,本篇来梳理下容器网络相关基础,并澄清说明一下本机网络的基本流程。
本篇主要参考:开发内功修炼 中网络篇的一些文章,后续再在本基础上扩展学习。
- 本机网络通信:本地回环 和
Unix Domain Socket - 容器网络
2. 本机网络通信方式说明
Kubernetes学习实践(一) – 总体说明和基本使用 中搭建环境时提到需要为容器CLI工具crictl新增配置文件(“修复上述警告和crictl命令执行不了的问题”所在小节),其中指定了Unix Domain Socket(UDS)的通信地址:unix:///var/run/containerd/containerd.sock,这里就是指定UDS进行bind时需要用到的文件路径。
此处来介绍下Unix Domain Socket的本机通信方式,并说明其和127.0.0.1回环(loopback)网络通信的差异,以及和跨主机网络通信的差异。
贴一下crictl配置文件相关内容:
1
2
3
4
5
6
cat <<EOF | sudo tee /etc/crictl.yaml
runtime-endpoint: unix:///var/run/containerd/containerd.sock
image-endpoint: unix:///var/run/containerd/containerd.sock
timeout: 10
debug: false
EOF
2.1. 跨主机通信 和 loopback回环网络通信
此处只做总体流程简要说明,进一步细节和代码级流程梳理,可见:127.0.0.1 之本机网络通信过程知多少。
1、先来看下最常规情况下的网络通信:2台机器之间进行基本的TCP socket交互。流程如下:
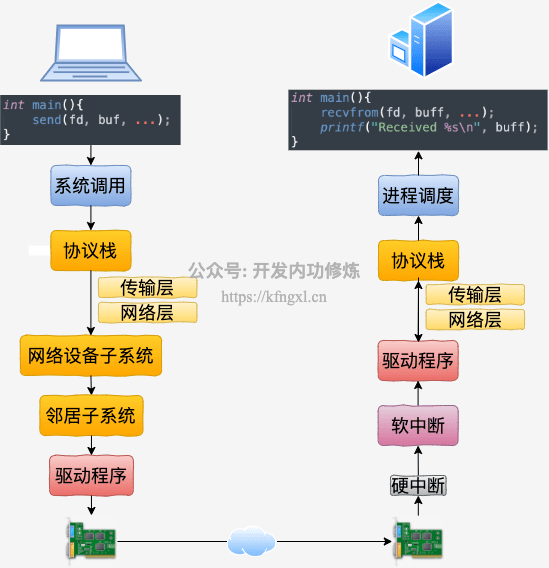
发送方数据经过内核网络协议栈处理,通过邻居子系统发送到驱动程序,而后通过网卡硬件发出。接收方则也通过网卡硬件接收。
之前宿主机网络相关的梳理和实验稍微多一点,可见:TCP发送接收过程 和 TCP半连接全连接。
2、loopback回环网络通信流程
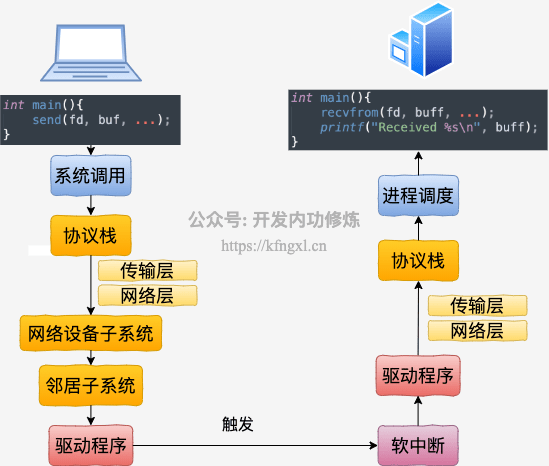
可看到:
127.0.0.1本机回环网络通信时,数据不需要经过网卡,因此即使拔掉网卡,也不影响本机上通过loopback通信- 本机回环网络数据流向:还是 需要经过跨机通信一样(除了网卡硬件)的各流程处理,只是数据不需要经过网卡的
RingBuffer队列,而是通过软中断直接把skb传给接收协议栈(本机回环的驱动程序也是一个纯软件的虚拟程序)。
问题:访问本机Server时,使用127.0.0.1能比使用本机ip(例如192.168.x.x)更快吗?
- 结论:两种使用方法在性能上没有啥差别
- 所有
local路由表项内核都会标识为RTN_LOCAL,查找路由表时(__ip_route_output_key),都会路由选择loopback虚拟设备
比如我的环境中的local路由表:
1
2
3
4
5
6
7
8
[root@xdlinux ➜ ~ ]$ ip route list table local
...
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
# 虽然显示enp4s0,实际上所有的`RTN_LOCAL`项,路由还是会选择loopback 虚拟设备
local 192.168.1.150 dev enp4s0 proto kernel scope host src 192.168.1.150
broadcast 192.168.1.255 dev enp4s0 proto kernel scope link src 192.168.1.150
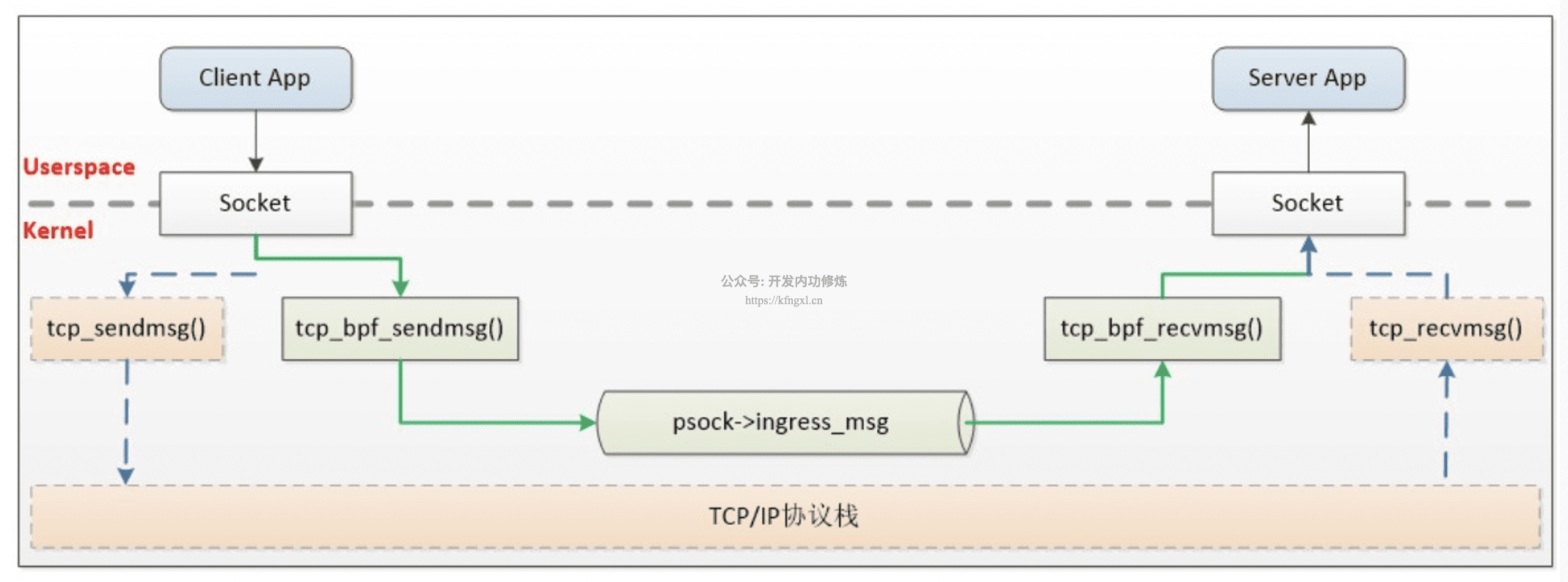
这里也贴下参考链接中提到的,在 边车(sidecar)代理程序 和 本地进程 间通信时,通过eBPF来绕开内核协议栈的开销(后续再梳理展开):
2.2. Unix Domain Socket
Unix Domain Socket(UDS)是一种用于同一主机上进程间通信(IPC)的机制,它不依赖网络协议栈,而是直接通过内核实现进程间的数据传递。相比基于 TCP/UDP的网络Socket,UDS更高效、更安全,是本地进程通信的优选方案之一。
UDS的流程如下,具体详情见参考文章:本机网络IO之Unix Domain Socket与普通socket的性能对比 实验使用源码。
建立连接过程:
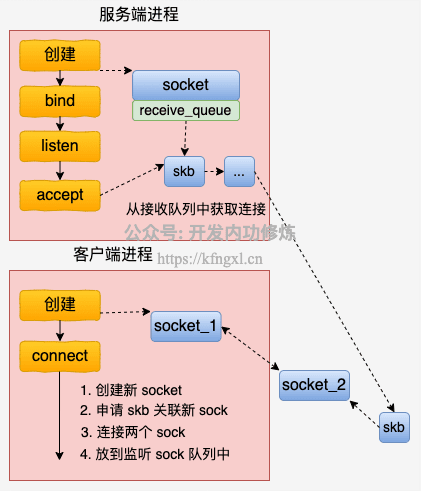
数据收发过程:
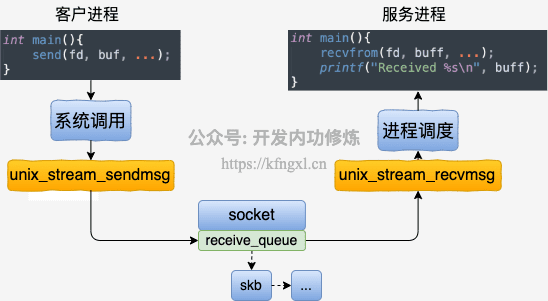
说明:
- 不需要经过网络协议栈,无需像TCP那样的三次握手、全连接半连接等过程
2.2.1. 编程方式
和传统socket类似,区别主要在
- 1)使用的socket地址结构为
sockaddr_un,协议族需要指定AF_UNIXsockaddr_un里的un表示UNIX domain sockets- 传统socket地址是
sockaddr_in结构,Internet domain sockets
- 2)需要指定一个系统文件路径用于通信
普通Socket使用方式:
1
2
3
4
5
6
7
8
// 创建socket
int server_fd = socket(AF_INET, SOCK_STREAM, 0)
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
bind(server_fd, (struct sockaddr *)&address, sizeof(address))
listen(server_fd, BACKLOG)
Unix Domain Socket使用方式:
1
2
3
4
5
6
7
8
struct sockaddr_un server_addr;
// 创建 unix domain socket
int fd = socket(AF_UNIX, SOCK_STREAM, 0);
// 绑定监听
char *socket_path = "./server.sock";
strcpy(serun.sun_path, socket_path);
bind(fd, serun, ...);
listen(fd, 128);
完整demo示例,可见:unix_domain_socket。
服务端监听后,netstat和ss查看状态如下:
- 查看下面的
I-Node,和uds_demo.sock文件的inode号(stat或者ls -i查看)并不相同,多次执行用的还是旧文件的引用?但是重启后发现还是不同,代码里尝试用绝对路径也不同(TODO)
1
2
3
4
5
6
7
8
9
# netstat
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ netstat -anp|grep -E "$(pidof ./server)|UNIX domain|I-Node"
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node PID/Program name Path
unix 2 [ ACC ] STREAM LISTENING 47497885 1835025/./server ./uds_demo.sock
# ss
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ ss -anp |grep -E "$(pidof ./server)|Send-Q"
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
u_str LISTEN 0 5 ./uds_demo.sock 47497885 * 0 users:(("server",pid=1835025,fd=3))
客户端执行(uds_client.c代码):
1
2
3
4
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ ./client
Connected to server.
Received from server: Hello from server!
Client closed.
服务端执行(uds_server.c代码):
1
2
3
4
5
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ ./server
Server listening on ./uds_demo.sock...
Client connected.
Received from client: Hello from client!
Server closed.
2.2.2. unlink 和 rm 对比
上面UDS的示例中,使用unlink进行文件删除,这里对其做下说明。
- 在 Unix/Linux 系统中,
unlink是一个用于删除文件(或特殊文件,如 Unix Domain Socket 创建的 .sock 文件)的系统调用(或同名命令)。它的核心作用是移除文件系统中的目录项(directory entry),并减少文件的链接计数(link count)。- 当文件的链接计数变为
0且没有进程打开该文件时,文件所占用的磁盘空间会被内核回收。
- 当文件的链接计数变为
rm本质上调用unlink实现文件删除,但支持更多功能(如递归删除目录 -r、强制删除 -f 等)unlink一次只能删除一个文件,且不能删除目录;rm可批量删除文件或目录。
文件的inode链接计数,之前在 从1万空文件占用空间大小看Linux文件系统结构 中也做过简单实验,这里再看下,刚touch的文件(未创建soft/hard链接):Links: 1
1
2
3
4
5
6
7
8
9
10
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ touch 111
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ stat 111
File: 111
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd06h/64774d Inode: 25168712 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2025-08-11 07:20:05.473274762 +0800
Modify: 2025-08-11 07:20:05.473274762 +0800
Change: 2025-08-11 07:20:05.473274762 +0800
Birth: 2025-08-11 07:20:05.473274762 +0800
1)unlink命令,调用到unlink接口(int unlink(const char *pathname);):
1
2
3
4
5
6
7
8
9
10
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ touch 111
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ strace -yy unlink 111
execve("/usr/bin/unlink", ["unlink", "111"], 0x7ffc142d35d0 /* 52 vars */) = 0
...
# 调用到 unlink接口
unlink("111") = 0
close(1</dev/pts/0<char 136:0>>) = 0
close(2</dev/pts/0<char 136:0>>) = 0
exit_group(0) = ?
+++ exited with 0 +++
2)rm命令,调用到unlinkat接口(int unlinkat(int dirfd, const char *pathname, int flags);):
- 调用
unlinkat接口的操作表现,和unlink或rmdir接口是一样的,但功能更强。 - 是
unlink的扩展,支持通过相对路径+目录描述符处理路径,更适合在多线程环境或需要动态切换目录的场景中使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ touch 111
[root@xdlinux ➜ unix_domain_socket git:(main) ✗ ]$ strace -yy rm -f 111
execve("/usr/bin/rm", ["rm", "-f", "111"], 0x7ffef209eb68 /* 52 vars */) = 0
...
newfstatat(AT_FDCWD</home/workspace/prog-playground/network/unix_domain_socket>, "111", {st_mode=S_IFREG|0644, st_size=0, ...}, AT_SYMLINK_NOFOLLOW) = 0
# 调用到 unlinkat接口
unlinkat(AT_FDCWD</home/workspace/prog-playground/network/unix_domain_socket>, "111", 0) = 0
lseek(0</dev/pts/0<char 136:0>>, 0, SEEK_CUR) = -1 ESPIPE (Illegal seek)
close(0</dev/pts/0<char 136:0>>) = 0
close(1</dev/pts/0<char 136:0>>) = 0
close(2</dev/pts/0<char 136:0>>) = 0
exit_group(0) = ?
+++ exited with 0 +++
2.3. 性能对比
Unix Domain Socket相比lo本地回环少了网络协议栈的交互,小包(e.g. 100字节)传输性能基本是lo的2倍多(参考链接中的实验场景),当包足够大的时候,网络协议栈上的开销就显得没那么明显了。
具体见:本机网络IO之Unix Domain Socket与普通socket的性能对比 实验使用源码。
3. 容器网络虚拟化基础 – veth
详情可见参考链接:轻松理解 Docker 网络虚拟化基础之 veth 设备
网络虚拟化:用软件来模拟真实网线的连接,实现数据交互。
- 本机网络IO里的
lo回环设备 也是一个用软件虚拟出来的设备
3.1. 查看当前podman的veth
自己环境里目前安装了K8s和podman,之前的容器都停掉了,启动一下之前的MySQL容器,而后可看到多出来了4和5对应的虚拟接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[root@xdlinux ➜ ~ ]$ docker ps
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3477156f2e93 docker.m.daocloud.io/library/mysql:8.0 --character-set-s... 5 weeks ago Up 2 minutes 0.0.0.0:3306->3306/tcp, 3306/tcp, 33060/tcp mysql-server
[root@xdlinux ➜ ~ ]$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp4s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 1c:69:7a:f5:39:32 brd ff:ff:ff:ff:ff:ff
3: wlp3s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether c8:94:02:4d:2d:01 brd ff:ff:ff:ff:ff:ff
4: podman0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 92:8b:b7:39:c1:c3 brd ff:ff:ff:ff:ff:ff
5: veth0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master podman0 state UP mode DEFAULT group default qlen 1000
link/ether 1e:90:37:9e:56:88 brd ff:ff:ff:ff:ff:ff link-netns netns-1836f023-0e86-8ff4-1416-bfb03e668d95
3.2. 实验:手动添加veth
创建veth:ip link add veth4 type veth peer name veth5,ip a可看到veth是成对出现的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[root@xdlinux ➜ ~ ]$ ip link add veth4 type veth peer name veth5
[root@xdlinux ➜ ~ ]$ ip a
...
8: veth5@veth4: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 9a:2e:ed:06:0c:56 brd ff:ff:ff:ff:ff:ff
9: veth4@veth5: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 22:af:86:d7:d3:73 brd ff:ff:ff:ff:ff:ff
# 或ip link show
[root@xdlinux ➜ ~ ]$ ip link show
...
8: veth5@veth4: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 9a:2e:ed:06:0c:56 brd ff:ff:ff:ff:ff:ff
9: veth4@veth5: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 22:af:86:d7:d3:73 brd ff:ff:ff:ff:ff:ff
为设备添加ip并启动:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 1、添加ip:
ip addr add 192.168.5.1/24 dev veth4
ip addr add 192.168.5.2/24 dev veth5
# 2、可以看到ip了
[root@xdlinux ➜ ~ ]$ ip a
8: veth5@veth4: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 9a:2e:ed:06:0c:56 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.2/24 scope global veth5
valid_lft forever preferred_lft forever
9: veth4@veth5: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 22:af:86:d7:d3:73 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.1/24 scope global veth4
valid_lft forever preferred_lft forever
# 3、启动设备
ip link set veth4 up
ip link set veth5 up
# 4、2个网口设备已启动
8: veth5@veth4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 9a:2e:ed:06:0c:56 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.2/24 scope global veth5
valid_lft forever preferred_lft forever
inet6 fe80::982e:edff:fe06:c56/64 scope link
valid_lft forever preferred_lft forever
9: veth4@veth5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 22:af:86:d7:d3:73 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.1/24 scope global veth4
valid_lft forever preferred_lft forever
inet6 fe80::20af:86ff:fed7:d373/64 scope link
valid_lft forever preferred_lft forever
ping 192.168.5.1可看到网络是通的,不过其实数据走的是192.168.5.1自身对应的lo回环地址:
1
2
3
4
5
6
7
8
9
10
[root@xdlinux ➜ ~ ]$ ping 192.168.5.1
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
64 bytes from 192.168.5.1: icmp_seq=1 ttl=64 time=0.115 ms
64 bytes from 192.168.5.1: icmp_seq=2 ttl=64 time=0.217 ms
# 抓包可看到走的是lo
[root@xdlinux ➜ ~ ]$ tcpdump -i any icmp
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
22:46:50.444245 lo In IP 192.168.5.1 > 192.168.5.1: ICMP echo request, id 21, seq 1, length 64
22:46:50.444259 lo In IP 192.168.5.1 > 192.168.5.1: ICMP echo reply, id 21, seq 1, length 64
3.3. 实验:两个veth通信
上述虽然启用了虚拟设备,但是veth之间(veth4和veth5)的网络是不通的,可-I指定通过veth4向veth5发送数据包查看:
1
2
3
4
5
6
7
8
9
10
# veth5:192.168.5.2; veth4:192.168.5.1,不通
[root@xdlinux ➜ ~ ]$ ping 192.168.5.2 -I veth4
PING 192.168.5.2 (192.168.5.2) from 192.168.5.1 veth4: 56(84) bytes of data.
From 192.168.5.1 icmp_seq=1 Destination Host Unreachable
# 抓包看veth4找不到哪个网口有192.168.5.2的MAC,ARP包并没有得到veth5的应答
[root@xdlinux ➜ ~ ]$ tcpdump -i veth4
listening on veth4, link-type EN10MB (Ethernet), snapshot length 262144 bytes
22:51:46.306207 ARP, Request who-has 192.168.5.2 tell 192.168.5.1, length 28
22:51:47.328569 ARP, Request who-has 192.168.5.2 tell 192.168.5.1, length 28
涉及到网口对应的rp_filter安全策略,和 accept_local 内核参数:
rp_filter(Reverse Path Filtering,反向路径过滤)- 是一个重要的内核模块,主要用于防止IP地址欺骗攻击,确保网络数据包的来源合法性。通过检查数据包的
源IP地址是否与接收接口的路由表信息一致,来判断数据包是否来自“合理路径”。 - 三种模式:
0(关闭模式)、1(严格模式,默认推荐)、2(松散模式)
- 是一个重要的内核模块,主要用于防止IP地址欺骗攻击,确保网络数据包的来源合法性。通过检查数据包的
accept_local内核参数- 用于控制系统是否接受 源IP地址 为本地地址(本机已配置的IP地址)的数据包,
1(允许)、0(不允许,默认值) - 这一参数的设计初衷是防止本地地址被伪造,但在需要本地地址间通信的场景(如同一主机上的不同服务通过本地IP而非
lo回环地址交互、容器间跨网络通信等)中,需要手动开启。
- 用于控制系统是否接受 源IP地址 为本地地址(本机已配置的IP地址)的数据包,
当前默认参数:
1
2
3
4
5
6
7
8
9
10
[root@xdlinux ➜ ~ ]$ cat /proc/sys/net/ipv4/conf/all/rp_filter
0
[root@xdlinux ➜ ~ ]$ cat /proc/sys/net/ipv4/conf/veth4/rp_filter
1
[root@xdlinux ➜ ~ ]$ cat /proc/sys/net/ipv4/conf/veth5/rp_filter
1
[root@xdlinux ➜ ~ ]$ cat /proc/sys/net/ipv4/conf/veth4/accept_local
0
[root@xdlinux ➜ ~ ]$ cat /proc/sys/net/ipv4/conf/veth5/accept_local
0
需要设置:
1
2
3
4
5
echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/veth4/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/veth5/rp_filter
echo 1 > /proc/sys/net/ipv4/conf/veth4/accept_local
echo 1 > /proc/sys/net/ipv4/conf/veth5/accept_local
再ping就能通了,而且走的是各自的IP,而不是回环地址:
1
2
3
4
5
6
7
8
9
10
11
# 两个veth间ping通了
[root@xdlinux ➜ ~ ]$ ping 192.168.5.2 -I veth4
PING 192.168.5.2 (192.168.5.2) from 192.168.5.1 veth4: 56(84) bytes of data.
64 bytes from 192.168.5.2: icmp_seq=1 ttl=64 time=0.052 ms
64 bytes from 192.168.5.2: icmp_seq=2 ttl=64 time=0.041 ms
# 正常发送了ICMP请求和应答
[root@xdlinux ➜ ~ ]$ tcpdump -i veth4
listening on veth4, link-type EN10MB (Ethernet), snapshot length 262144 bytes
23:24:32.047104 IP 192.168.5.1 > 192.168.5.2: ICMP echo request, id 27, seq 1, length 64
23:24:33.088843 IP 192.168.5.1 > 192.168.5.2: ICMP echo request, id 27, seq 2, length 64
3.4. bpftrace追踪veth接口交互
veth的创建、发送/接收等内核源码过程,具体可见参考链接进行学习,本篇暂只跟踪下数据发送接口:veth_xmit。
追踪内核正反调用栈,还是用bpftrace(也可用perf record -e+perf report) + funcgraph。可了解之前的实践用法:追踪内核网络堆栈的几种方式 和 Linux存储IO栈梳理(三) – eBPF和ftrace跟踪IO写流程,还是得结合场景多实践内化,要不时间一长又弱化了。
perf-tools需要从 GitHub项目主页 下载使用,可以自行本地归档一份,比如我的归档:tools/perf-tools。
查看对应的符号和追踪点:
1
2
3
[root@xdlinux ➜ ~ ]$ bpftrace -l|grep veth_xmit
kfunc:veth:veth_xmit
kprobe:veth_xmit
如下跟踪kprobe,通过ping 192.168.5.2 -I veth4来用veth4向veth5进行发包,可追踪到调用栈:
调用veth_xmit之前的调用栈(谁调用到veth_xmit):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 通过计数控制抓取的个数
[root@xdlinux ➜ ~ ]$ bpftrace -e 'BEGIN { @count = 0; } kprobe:veth_xmit { if (@count < 2) { printf("comm:%s, stack:%s\n", comm, kstack()); @count++; } else { exit(); } }'
Attaching 2 probes...
comm:ping, stack:
veth_xmit+1
dev_hard_start_xmit+136
__dev_queue_xmit+1214
arp_solicit+244
neigh_probe+81
__neigh_event_send+615
neigh_resolve_output+305
ip_finish_output2+401
ip_push_pending_frames+162
ping_v4_sendmsg+1086
__sys_sendto+457
__x64_sys_sendto+32
do_syscall_64+95
entry_SYSCALL_64_after_hwframe+120
调用veth_xmit之后的调用栈,即veth_xmit中的实现流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
[root@xdlinux ➜ bin git:(main) ✗ ]$ funcgraph -H veth_xmit
Tracing "veth_xmit"... Ctrl-C to end.
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
10) | veth_xmit [veth]() {
10) | irq_enter_rcu() {
10) 0.209 us | irqtime_account_irq();
10) 0.676 us | }
# 中断处理
10) | __sysvec_irq_work() {
10) | __wake_up() {
10) 0.190 us | ...
10) 7.999 us | }
10) 8.437 us | }
10) | irq_exit_rcu() {
10) 0.180 us | irqtime_account_irq();
10) 0.179 us | sched_core_idle_cpu();
10) 0.866 us | }
10) 0.179 us | __rcu_read_lock();
10) 0.189 us | skb_clone_tx_timestamp();
10) | __dev_forward_skb() {
10) | __dev_forward_skb2() {
10) 0.209 us | skb_scrub_packet();
10) 0.219 us | eth_type_trans();
10) 0.955 us | }
10) 1.293 us | }
10) | __netif_rx() {
10) | netif_rx_internal() {
10) | ktime_get_with_offset() {
10) | read_hpet() {
10) 1.155 us | read_hpet.part.0();
10) 1.483 us | }
10) 1.851 us | }
10) | enqueue_to_backlog() {
10) 0.179 us | _raw_spin_lock_irqsave();
10) 0.190 us | __raise_softirq_irqoff();
10) 0.179 us | _raw_spin_unlock_irqrestore();
10) 1.264 us | }
10) 3.612 us | }
10) 3.971 us | }
10) 0.179 us | __rcu_read_unlock();
10) + 20.358 us | }
...
4. 小结
梳理说明了本机网络通信方式:lo本地回环和Unix Domain Socket;介绍了容器网络基础中的veth并进行简单跟踪,容器网络基础的其他部分在后续篇幅继续梳理实践。