并发与异步编程(三) -- 性能分析工具:gperftools和火焰图
异步编程实验,使用 gperftools 和 火焰图 进行性能分析。本篇先介绍工具。
异步编程实验,使用 gperftools 和 火焰图 进行性能分析。本篇先介绍工具。
1. 背景
并发与异步编程(二) – 异步编程框架了解 介绍了几种异步编程框架,现在来完成 并发与异步编程(一) – 实现一个简单线程池 中的TODO,进行异步编程实验,并简单进行分析性能。
- 1、通过 gperftools 采集分析资源消耗情况
- 2、基于 Brendan Gregg 大佬的火焰图(Flame Graphs)采集信息进行可视化展示,包括 On-CPU火焰图、Off-CPU火焰图
本篇先介绍工具,尤其是Off-CPU火焰图(集合)。
2. gperftools工具
gperftools 由 Google 开源,来源于 Google Performance Tools。gperftools集合中包含一个高性能多线程的内存分配器实现(即tcmalloc),并提供了多种性能分析工具。
项目地址:gperftools。
安装:除了源码编译,在CentOS上可以直接yum install gperftools(会同时安装好pprof和其他依赖,如libunwind)
本篇就主要使用其中的工具:支持侵入式和非侵入式进行性能采集,即支持程序代码中不硬编码API也可采集。
1、 CPU分析用法
- 生成函数调用图,统计 CPU 时间消耗,定位热点代码
- 支持按函数、模块或地址分析,输出文本或可视化报告(需配合pprof工具)
1
2
3
4
5
6
1) Link your executable with -lprofiler
2) Run your executable with the CPUPROFILE environment var set:
$ CPUPROFILE=/tmp/prof.out <path/to/binary> [binary args]
3) Run pprof to analyze the CPU usage
$ pprof <path/to/binary> /tmp/prof.out # -pg-like text output
$ pprof --gv <path/to/binary> /tmp/prof.out # really cool graphical output
项目中给的CPU分析示例:
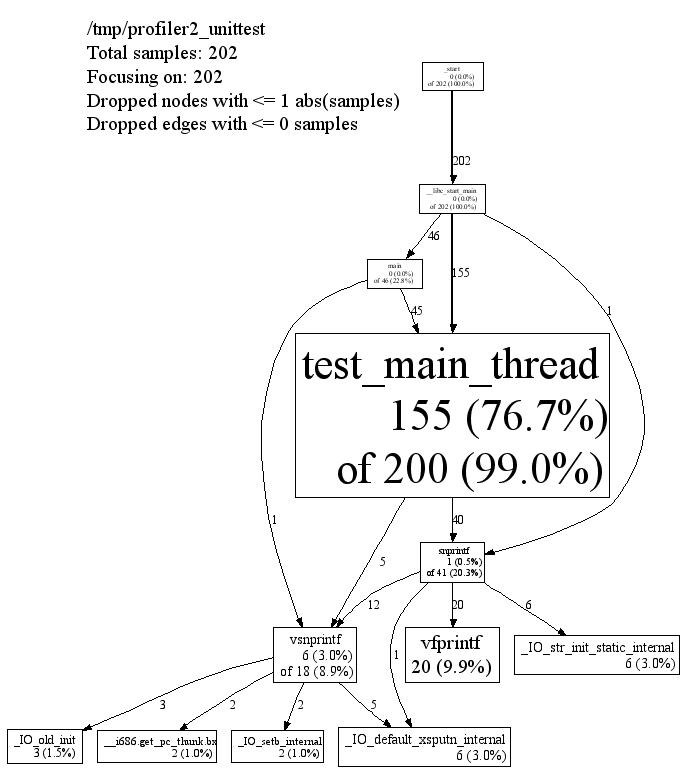
2、 内存分析用法
- 跟踪内存分配和释放,检测内存泄漏或过度分配问题
- 可按时间戳或调用栈统计内存使用情况
1
2
3
4
5
6
7
1) Link your executable with -ltcmalloc
# 如果编译时没有-l链接,也可以在执行时使用 LD_PRELOAD
2) Run your executable with the HEAPPROFILE environment var set:
$ HEAPPROFILE=/tmp/heapprof <path/to/binary> [binary args]
3) Run pprof to analyze the heap usage
$ pprof <path/to/binary> /tmp/heapprof.0045.heap # run 'ls' to see options
$ pprof --gv <path/to/binary> /tmp/heapprof.0045.heap
3. On-CPU火焰图和技巧
3.1. 简要介绍
项目地址:FlameGraph GitHub
Brendan Gregg大佬的火焰图文章合集,都很值得一读:Flame Graphs,包含
- CPU Flame Graphs
- Off-CPU Flame Graphs
- 内存泄漏和增长图:Memory Leak (and Growth) Flame Graphs
- 冷热图集成(即整合CPU和Off-CPU):Hot/Cold Flame Graphs
- 红/蓝差分火焰图(即前后对比):Differential Flame Graphs
- 以及AI相关火焰图介绍:AI Flame Graphs
- PS:大佬22年离开网飞去Intel搞云计算和AI了
3.2. On-CPU火焰图技巧
On-CPU火焰图使用场景最常见,就不多说了,关注大平顶(即采样数,注意颜色只是用暖色调没其他特别含义)。
如果堆栈比较深,影响查找平顶,有个小技巧:使用--inverted查看冰柱型火焰图,并结合--reverse反转堆栈,有时能更直接找到最热的调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
[CentOS-root@xdlinux ➜ FlameGraph git:(master) ]$ ./flamegraph.pl -h
Option h is ambiguous (hash, height, help)
USAGE: ./flamegraph.pl [options] infile > outfile.svg
--title TEXT # change title text
--subtitle TEXT # second level title (optional)
--width NUM # width of image (default 1200)
--height NUM # height of each frame (default 16)
--minwidth NUM # omit smaller functions. In pixels or use "%" for
# percentage of time (default 0.1 pixels)
--fonttype FONT # font type (default "Verdana")
--fontsize NUM # font size (default 12)
--countname TEXT # count type label (default "samples")
--nametype TEXT # name type label (default "Function:")
--colors PALETTE # set color palette. choices are: hot (default), mem,
# io, wakeup, chain, java, js, perl, red, green, blue,
# aqua, yellow, purple, orange
--bgcolors COLOR # set background colors. gradient choices are yellow
# (default), blue, green, grey; flat colors use "#rrggbb"
--hash # colors are keyed by function name hash
--random # colors are randomly generated
--cp # use consistent palette (palette.map)
--reverse # generate stack-reversed flame graph
--inverted # icicle graph
--flamechart # produce a flame chart (sort by time, do not merge stacks)
--negate # switch differential hues (blue<->red)
--notes TEXT # add notes comment in SVG (for debugging)
--help # this message
用stress模拟CPU、sync落盘、内存、write磁盘的压力:
1
2
3
4
5
6
7
8
[CentOS-root@xdlinux ➜ flamegraph_sample git:(main) ✗ ]$ stress --cpu 2 --io 2 --vm 2 --hdd 2 --timeout 5s
stress: info: [33388] dispatching hogs: 2 cpu, 2 io, 2 vm, 2 hdd
stress: info: [33388] successful run completed in 6s
# 另一个终端进行perf采集:
perf record -a -g
# 生成火焰图
perf script -i perf.data| stackcollapse-perf.pl | flamegraph.pl --reverse --inverted > stress_2cpu_2io_2vm_2hdd_icicle.svg
1)默认火焰图:

2)冰柱型且反转堆栈,有时尖刺太多的话会比较有效:

4. Off-CPU火焰图
这里重点说下Off-CPU火焰图,对于非CPU操作,它提供了很实用的采集观测工具,比如Off-CPU、文件IO、block IO、还有线程唤醒的链路追踪,和On-CPU是个很好的互补。具体见:Off-CPU Flame Graphs。
Off-CPU 能够识别的类型包含:阻塞在 I/O、锁、定时器、缺页、swap等 事件上的时间消耗。
注意:
- 使用Off-CPU进行追踪和采样分析时,调度事件会特别频繁,这也是eBPF这种内核态追踪为何如此重要,如果用户态和内核态频繁切换,追踪工具本身会带来很大的性能开销(采集信息很多且写到磁盘文件带来进一步的CPU和IO相关消耗)。
- 作者做了perf和eBPF的 MySQL高压力实验对比:各自进行10s的采集,查看吞吐量(throughput)的下降情况
- perf需要额外35s时间处理数据(处理时13%下降;10s采集了224MB追踪数据),追踪过程9%下降。即 10s引起了持续45s的9-13%性能下降
- eBPF则要额外6s左右处理数据(13%下降),且需要1s初始化eBPF(13%下降),追踪过程6%下降。即 10s引起了持续17s的6-13%性能下降
- 且随着采集时间拉长,比如采集60s:eBPF处理还是只要6-7s时间,perf处理则从35s上升到212s!
- 具体可了解:Off-CPU Analysis
4.1. bcc eBPF工具集说明
由于Off-CPU相关指标很多都涉及内核层面,perf采样比较耗性能,且perf自身造成的上下文切换会比较影响结果,上面几个工具的指标一般都是基于eBPF采集。
之前 eBPF学习实践系列 中,学习实践了不少eBPF、ftrace相关的一些工具,这里再回顾一下。
1、基于eBPF的bcc工具集(/usr/share/bcc/tools/):
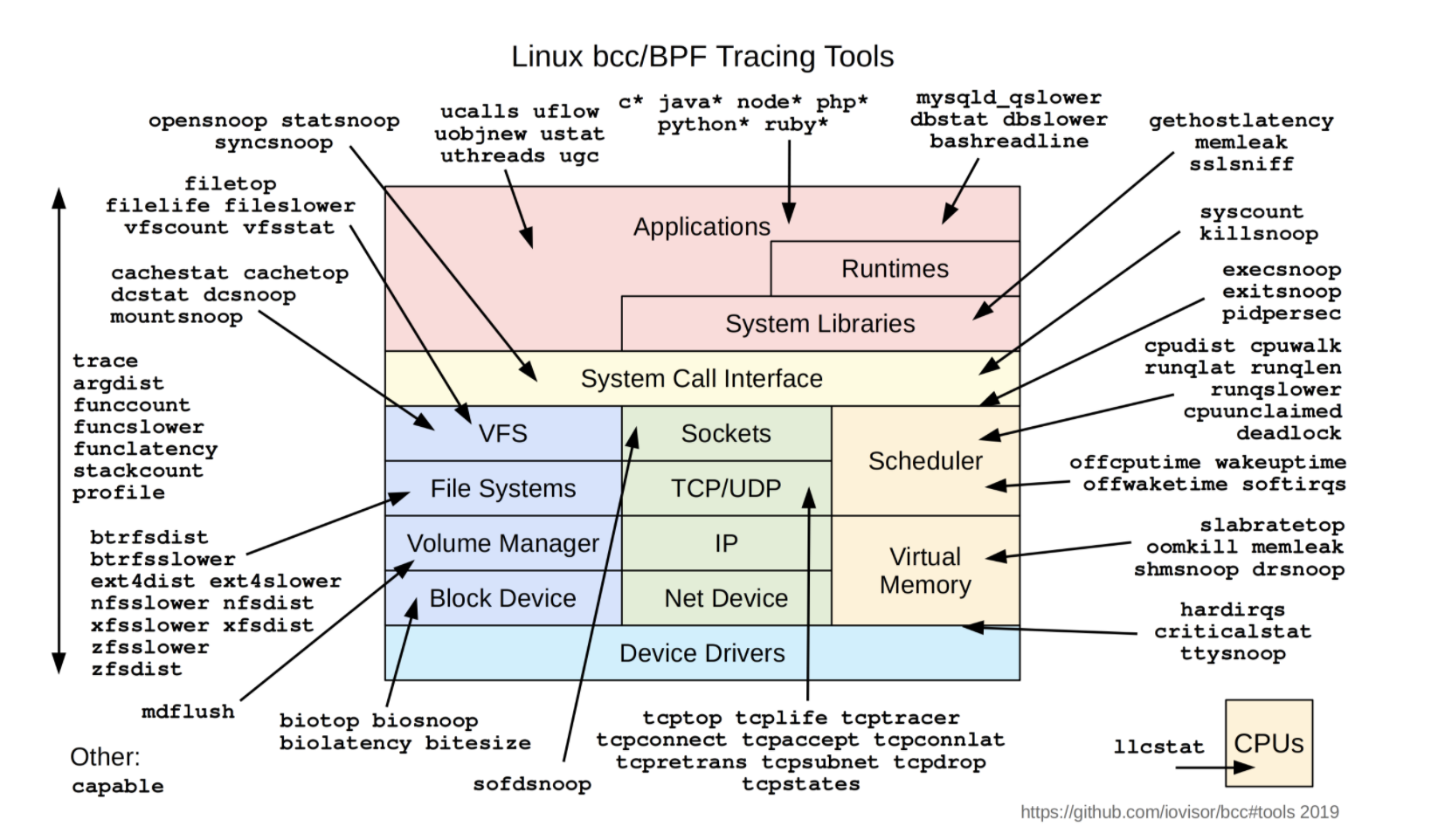
为简化eBPF开发,发展出了bcc、bpftrace。为解决移植性问题,内核提供了BTF、CO-RE(Compile-Once Run-Everywhere)技术,封装在libbpf中。
上面这些工具之前都是基于python写的eBPF工具,作者考虑转用新的libbpf接口进行实现,bcc仓库里的 libbpf-tools 已经有一部分工具了,可看到还在持续更新当中。
Update 04-Nov-2020: The Python interface is now considered deprecated in favor of the new C libbpf interface
详情可查看:Linux Extended BPF (eBPF) Tracing Tools
2、基于perf和ftrace的 perf-tools 工具集
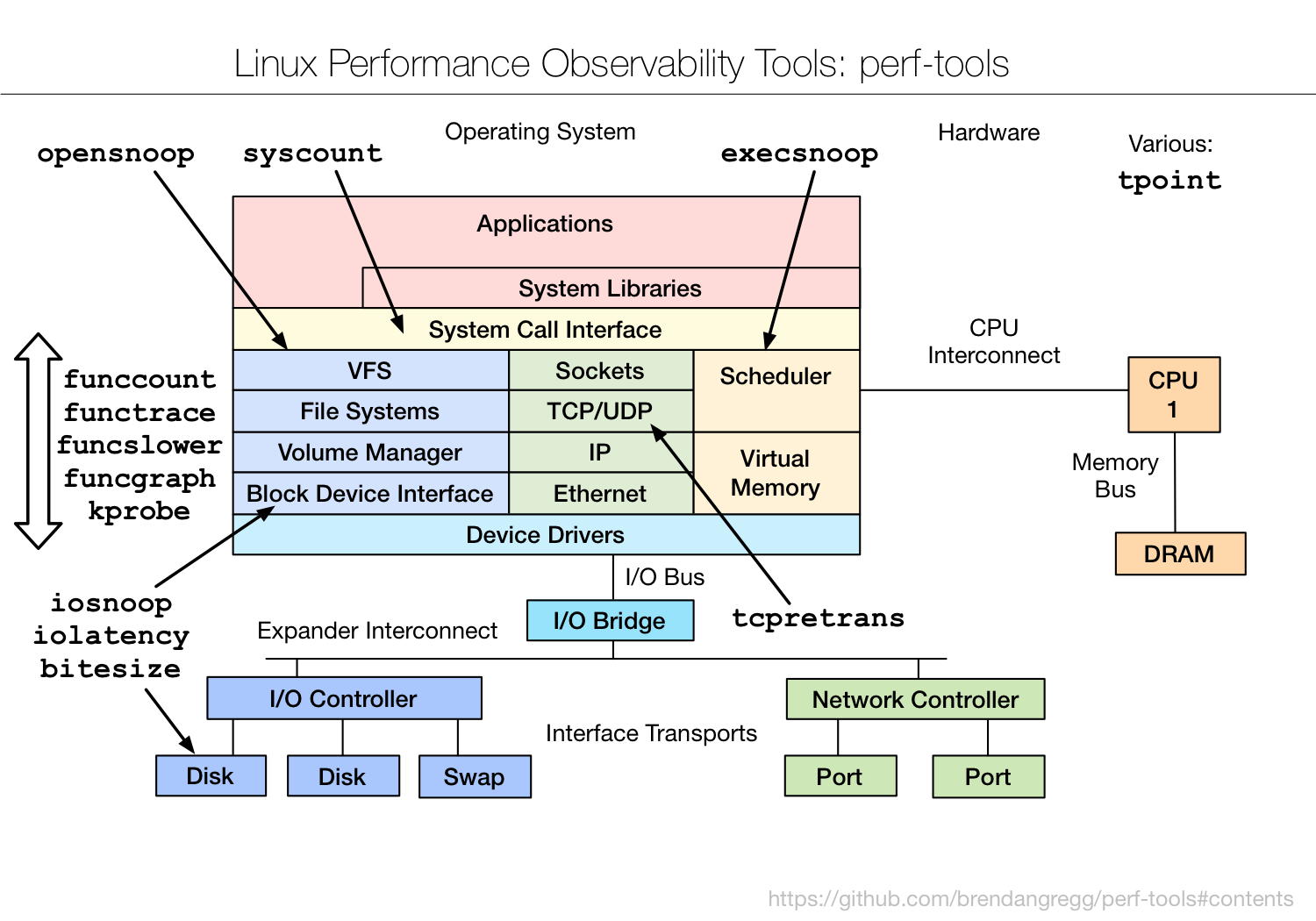
{kind=link}
{kind=link}
其中的funcgraph很方便。结合bpftrace和funcgraph很适合跟踪前后调用栈:
- bpftrace 用来从上到下来跟踪到指定函数,即只能看到谁调用到指定追踪点
- funcgraph 用来从指定函数往下追踪调用栈
可以回顾之前用bpftrace和funcgraph追踪存储栈实践用法:Linux存储IO栈梳理(二) – Linux内核存储栈流程和接口、Linux存储IO栈梳理(三) – eBPF和ftrace跟踪IO写流程
4.2. 工具归档说明
以下面的offcputime工具为例,有两个方式获取:
- bcc tools工具集:
/usr/share/bcc/tools/offcputime,基于python写的eBPF工具 - bcc libbpf-tools(见上面的 bcc eBPF工具集说明,基于libpf,自行编译
- bcc工具中的libbpf-tools一直在更新,可以自行编译
git clone --recurse-submodules https://github.com/iovisor/bcc.git- 其中:src/cc/libbpf、libbpf-tools/blazesym、libbpf-tools/bpftool 都是子模块
自己在 bcc_libbpf-tools_bin_db5b63f 也归档了一份基于bcc编译的libbpf-tools工具进行备用(x86_64,gcc8.5.0),基于bcc commitid:db5b63ff876d3346021871e2189a354bfc6d510e,20250315才提交的,如上所述项目一直在更新,后续按需编译。
5. Off-CPU采集实验
如果机器上的内核没开启eBPF对应特性支持(比如未开启CONFIG_DEBUG_INFO_BTF),那需要重新编译下内核。简要步骤:
make menuconfig,搜索CONFIG_DEBUG_INFO_BTF并设置y保存到.configmake -j6,得到 bzImage,拷贝到/boot/替换vmlinuzxxx,或者只拷贝并在grub里新增一个menuentry项
下面的实验结果,也归档在:flamegraph_sample
5.1. Off-CPU采集和分析
1、bcc tools中的新工具支持了相关堆栈折叠选项,所以可以不用stackcollapse-xxx.pl脚本进行折叠了。
/usr/share/bcc/tools/offcputime参数,具体-h查看:
-d, –delimited 在内核栈和用户栈之间插入分隔符-f, –folded 输出折叠格式-p指定进程、-t指定线程、-U只看用户态堆栈、-K只看内核态堆栈- 后面接数字表示持续时间,秒数,比如
offcputime 5 --state可以指定线程状态(位掩码bitmask)- 0(
TASK_RUNNING)可执行状态- 进程要么正在执行,要么准备执行,涵盖了操作系统层面“运行”和“就绪”两种状态。
- 处于该状态(比如一个进程被创建并准备好执行)的进程会被放置在 CPU 的运行队列(runqueue)中,等待调度器分配CPU时间片
- 1(
TASK_INTERRUPTIBLE)可中断睡眠状态,可被信号唤醒- 进程正在等待某个特定的事件发生(如 I/O 完成、信号到来等),这期间会放弃CPU资源进入睡眠状态
- 内核中,当进程调用某些会导致睡眠的系统调用(如 read、write 等)时,如果所需的资源暂时不可用,进程会将自己的状态设置为 TASK_INTERRUPTIBLE 并加入相应的等待队列
- 2(
TASK_UNINTERRUPTIBLE)不可中断睡眠状态,不可被信号唤醒- 等待某个特定事件,期间不会响应任何信号,只能等待事件本身发生后才能被唤醒
- 通常用于一些对系统稳定性要求较高的场景,比如与硬件设备交互,例如进程正在
等待磁盘 I/O 操作完成
- 4(
__TASK_STOPPED)停止状态- 进程由于接收到特定的信号(如 SIGSTOP、SIGTSTP 等)而被暂停执行,该状态不会调度到CPU上运行,直到它接收到继续执行的信号(如 SIGCONT)
- 当内核接收到停止进程的信号时,会将进程的状态设置为 TASK_STOPPED,并将其从运行队列中移除
- 还有很多状态,可见:linux-5.10.10/include/linux/sched.h
- 0(
配色选择:--color=io
1
2
3
4
5
6
7
8
9
# stress模拟压力
stress --cpu 2 --io 2 --vm 2 --hdd 2 --timeout 5s
# bcc tools 采集堆栈
/usr/share/bcc/tools/offcputime -df > out.stacks
# 生成火焰图
flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us < out.stacks > offcpu_stress_2cpu_2io_2vm_2hdd.svg
# 冰柱型、反转堆栈
flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us --reverse --inverted < out.stacks > offcpu_stress_2cpu_2io_2vm_2hdd_icicle.svg

分析:
- 上述Off-CPU图中,灰色的”
-“行,对应offcputime -d参数指定的,向内核态和用户态之间插入的分隔符 - 堆栈方向:从下到上,下面是用户态,上面是内核态堆栈。从中可看到用户态程序真正被什么阻塞了
- 比如图中mysqld的
__pthread_cond_timedwait系统调用,依次堆栈是进入内核态调用 ->__x64_sys_futex->do_futex-> … ->finish_task_switch
- 比如图中mysqld的
- 虽然执行了stress,但火焰图中最宽的还是mysqld进程
- 这里mysqld时间占了165秒,原因如 之前 用
perf stat分析线程池开销时所说的,time elapse(也叫墙上时间,Wall Clock Time)是程序开始到结束的时间(此处即这5s左右),是可能比用户时间(user time)和系统时间(sys time)小的,主要是多线程中这些时间是分别累加的。比如两个线程各自sys time是0.03s和0.04s,总的sys time就是0.07s,而time elapse可能只是max(0.03, 0.04, usr time) - 几个多线程服务就会出现这个尴尬的情况,Off-CPU火焰图中,总被这些大宽列影响整体查看。
- 一个解决方式是:过滤感兴趣线程的状态,比如不可中断睡眠状态,
offcputime -df --state 2
- 这里mysqld时间占了165秒,原因如 之前 用
冰柱型如下,各调用分支相同的调用进行了合并,可明显看到热点是上下文切换中的finish_task_switch:

2、libbpf-tools里,offcputime则没有这类选项,用stackcollapse.pl折叠一下(之前perf采集时则用stackcollapse-perf.pl)
1
2
3
4
5
6
# bcc libbpf-tools
# /home/workspace/bcc/libbpf-tools/offcputime
offcputime > out.stacks
stackcollapse.pl < out.stacks | flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us > offcpu_stress2.svg
# 冰柱型、反转堆栈
stackcollapse.pl < out.stacks | flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us --reverse --inverted > offcpu_stress2_icicle.svg
用冰柱型查看,和上面有点出入,没直接找到上下文切换接口。不确定是否为 采集的东西太多、且采集时miss了一些堆栈 的影响。

结论:火焰图场景,还是暂用原来bcc tools的工具比较合适,比如 /usr/share/bcc/tools/offcputime。
Off-CPU的问题是,只能看到程序在等待某个IO或者锁,但是无法知道等待这么长时间时CPU具体在做什么处理,若知晓的话就可以辅助分析这个等待是否合理。于是下面的wekeup火焰图就上场了。
5.2. 线程唤醒者栈追踪(Wakeup)
用途:线程处于睡眠等待时(off-CPU sleeping),CPU会切换到其他线程,后续该线程再被调度唤醒。Wakeup火焰图可以看到睡眠线程在等待什么、为什么等如此之久。相对于只查看Off-CPU火焰图,唤醒信息(wakeup information)可以解释阻塞(block)的真正原因,对于锁竞争的场景很有帮助。唤醒路径可以揭示是谁持有并最终释放了锁,从而导致了线程的唤醒。(追踪唤醒者的堆栈)
颜色方案:--color=wakeup
1
2
3
4
/usr/share/bcc/tools/wakeuptime -f > out.stacks
flamegraph.pl --color=wakeup --title="Wakeup Time Flame Graph" --countname=us < out.stacks > wakeup_stress_out.svg
# 冰柱型、反转堆栈
flamegraph.pl --color=wakeup --title="Wakeup Time Flame Graph" --countname=us --reverse --inverted < out.stacks > wakeup_stress_out_icicle.svg
虽然用stress --cpu 4 --timeout 5s模拟了压力(会起4个进程不停sqrt()),但看到的系统等待的大头还是mysqld,还是其多线程导致sys time累加很大,从冰柱型中,可看到mysqld占了150s。(这让只跑了5s的采集怎么看?)

分析火焰图之前说下wakeuptime追踪的堆栈结果:
特别注意:用 /usr/share/bcc/tools/wakeuptime 和 bcc_libbpf-tools/wakeuptime 采集的堆栈方向不一样!(可以通过首行的提示快速区分,火焰图以bcc tools为准)
bcc tools采集结果(不-f折叠):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# bcc tools采集,/usr/share/bcc/tools/wakeuptime
[CentOS-root@xdlinux ➜ bin git:(main) ]$ /usr/share/bcc/tools/wakeuptime
Tracing blocked time (us) by kernel stack... Hit Ctrl-C to end.
^C
# 被唤醒者
target: mysqld
# 从上往下,是waker(即swapper/1)经过的堆栈
# 辅助 CPU 启动的函数
ffffffff97a00107 secondary_startup_64_no_verify
# 进一步的 CPU 启动函数,负责启动辅助 CPU 的后续步骤
ffffffff97a5929b start_secondary
# CPU 启动的入口函数,进行一些初始化工作
ffffffff97b22c7f cpu_startup_entry
ffffffff97b22a84 do_idle
ffffffff9814393c cpuidle_enter
ffffffff981435fb cpuidle_enter_state
# 处理APIC定时器中断的函数
ffffffff98401c4f apic_timer_interrupt
# 对称多处理(SMP)环境下的定时器中断处理
ffffffff984026ba smp_apic_timer_interrupt
ffffffff97b7e0f0 hrtimer_interrupt
ffffffff97b7d920 __hrtimer_run_queues
ffffffff97b7d6ee hrtimer_wakeup
# 尝试唤醒一个进程的函数,是唤醒操作的上层逻辑
ffffffff97b1d186 try_to_wake_up
# 最终负责实际唤醒工作的函数
ffffffff97b1c106 ttwu_do_wakeup
# wakeuptime 工具基于 eBPF 技术实现,这是其中跟踪相关的函数
ffffffff97c0dde2 bpf_trace_run1
ffffffffc03a4aa6 exit_misc_binfmt
# 获取 eBPF 堆栈 ID 的函数,用于获取当前堆栈的标识信息,以便进行跟踪和分析
ffffffff97c0fe0e bpf_get_stackid_raw_tp
# 唤醒者,即 swapper/1 唤醒了 mysqld
waker: swapper/1
# waker 调用栈经过的时间,微秒(us)
67523756
libbpf-tools工具采集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 注意这里的堆栈是用bcc libbpf-tools工具采集的,libbpf-tools/wakeuptime
Tracing blocked time (us) by kernel stack
# 被唤醒者
target: mysqld
# 从下往上,是waker(即swapper/9)经过的堆栈。堆栈方向和bcc tools处理后的相反。
ffffffffc03c1d55 __this_module+0x3c55
ffffffff97c0fe0e bpf_get_stackid_raw_tp+0x4e
ffffffffc03c1d55 __this_module+0x3c55
ffffffff97c0dde2 bpf_trace_run1+0x32
ffffffff97b1c106 ttwu_do_wakeup+0x106
# 内核中尝试唤醒指定进程(线程)的核心函数
ffffffff97b1d186 try_to_wake_up+0x1a6
# 高精度定时器相关的唤醒函数,当定时器到期时会触发这个函数
ffffffff97b7d6ee hrtimer_wakeup+0x1e
ffffffff97b7d920 __hrtimer_run_queues+0x100
ffffffff97b7e0f0 hrtimer_interrupt+0x100
ffffffff984026ba smp_apic_timer_interrupt+0x6a
# 定时器中断函数被触发(经过一系列调用,最终调到上面的 try_to_wake_up )
ffffffff98401c4f apic_timer_interrupt+0xf
ffffffff981435fb cpuidle_enter_state+0xdb
ffffffff9814393c cpuidle_enter+0x2c
ffffffff97b22a84 do_idle+0x234
ffffffff97b22c7f cpu_startup_entry+0x6f
ffffffff97a5929b start_secondary+0x19b
# 辅助 CPU 启动的函数
# 堆栈自底向上
ffffffff97a00107 secondary_startup_64_no_verify+0xc2
# swapper/9进程将 mysqld 唤醒的
waker: swapper/9
# 自底向上查看,唤醒者唤醒路径要花费的时间,us
6006204
分析:
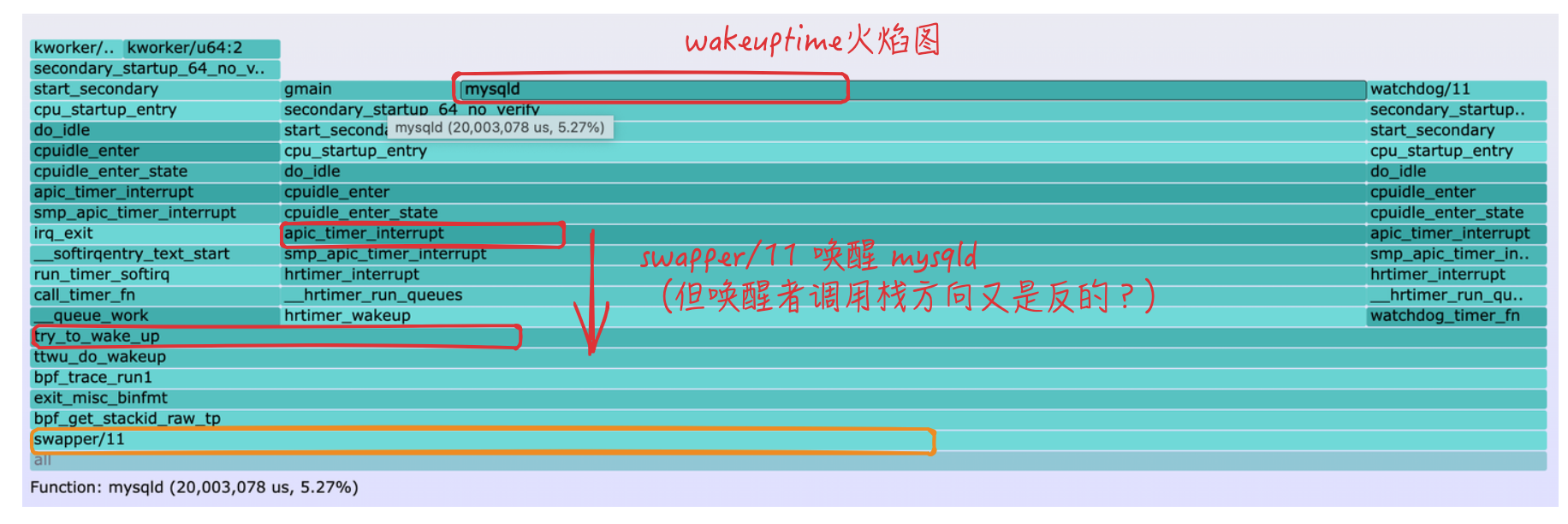
- 查看火焰图时,需要跟bcc tools采集的堆栈结果保持一致
- 火焰图中,最上面是target(被唤醒者),最下面是waker(唤醒者),从上往下是waker的堆栈,经过这些堆栈唤醒了target
- 对于bcc libbpf-tools采集的堆栈,中间自底向上是唤醒过程中内核经过的堆栈 (
存疑?按经过的函数看图里的调用栈好像反了,TODO)- 下面图中的疑问,是对照
libbpf-tools堆栈结果看的,所以以为相反。换成bcc tools堆栈结果,就一一对应了。
- 下面图中的疑问,是对照
冰柱型(貌似此处不大需要,反而增加理解成本):

用libbpf-tools里编译的wakeuptime工具也对比下,追踪的堆栈结果里有地址,但是stackcollapse.pl里没去掉导致火焰图里地址也在接口前面,bcc tools里面的-f是做了处理的。
所以也还是先用bcc tools吧,和火焰图的验证配套更全面一些。
1
2
3
4
# bcc libbpf-tools
# /home/workspace/bcc/libbpf-tools/wakeuptime
wakeuptime > out.stacks
stackcollapse.pl < out.stacks | flamegraph.pl --color=wakeup --title="Wakeup Time Flame Graph" --countname=us > wakeuptime_libpf_stress.svg
5.3. Off-Wake火焰图
Off-Wake火焰图(Off-Wake Flame Graphs)用途:可完整追踪 唤醒者 以及 被唤醒者 的Off-CPU堆栈。
会导致性能开销变大,好处是简化了 Off-CPU 唤醒链理解的复杂性。
工具使用:/usr/share/bcc/tools/offwaketime,libbpf-tools里还没移植这个工具
颜色方案:--color=chain
1
2
/usr/share/bcc/tools/offwaketime -f 20 > out.stacks
flamegraph.pl --color=chain --title="Off-Wake Time Flame Graph" --countname=us < out.stacks > offwaketime_out.svg

同样先来看下offwaketime采集的信息:
- 查看方法(注意和上面不同):
- 从中间的
--分隔符开始,分隔符上方是唤醒者的堆栈(Waker Stack),从上到下看 - 分隔符下方是被唤醒堆栈(Target Stack),被唤醒之前到达阻塞的堆栈,从下到上看
- 从中间的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# bcc tools采集的未折叠堆栈
[CentOS-root@xdlinux ➜ chain git:(main) ✗ ]$ cat not_folded_out.stacks
Tracing blocked time (us) by user + kernel off-CPU and waker stack... Hit Ctrl-C to end.
# 唤醒者
waker: swapper/5 0
b'secondary_startup_64_no_verify'
b'start_secondary'
b'cpu_startup_entry'
b'do_idle'
b'cpuidle_enter'
b'cpuidle_enter_state'
# 定时器中断触发
b'apic_timer_interrupt'
b'smp_apic_timer_interrupt'
# 定时器到期会触发这些函数。高精度定时器(hrtimer)相关函数
b'hrtimer_interrupt'
b'__hrtimer_run_queues'
# 最终通过 hrtimer_wakeup 完成唤醒操作
b'hrtimer_wakeup'
-- --
b'finish_task_switch'
b'__sched_text_start'
# schedule里往上调用__sched_text_start
b'schedule'
# I/O 操作等待
b'read_events'
b'do_io_getevents'
b'__x64_sys_io_getevents'
b'do_syscall_64'
b'entry_SYSCALL_64_after_hwframe'
# mysqld进行系统调用,然后依次往上执行堆栈,即体现的是被唤醒之前的堆栈/如何进入到阻塞状态的堆栈
b'syscall'
# 被唤醒者
target: mysqld 1543
500247
上述offwaketime火焰图的解释/查看方法:唤醒者(顶部)通过什么调用栈唤醒、被唤醒者(底部)之前由于什么堆栈进入阻塞状态
见下图的说明: 
另外试了下提到的Chain Graphs:chaintest.py,自己环境里没采集到堆栈,可能暂时还不可用。
5.4. 文件IO和块设备IO
(此处的实验其实先做,但有点问题,放到最后)
fileiostacks.py不在bcc里,而是在 BPF-tools 老的工具集里:fileiostacks.py
参考链接里的块设备堆栈追踪工具:biostacks.py 也在BPF-tools里面。
1
2
3
4
5
6
# 下面命令以自己的工具路径示例,火焰图路径export PATH
export PATH=$PATH:/home/workspace/prog-playground/flamegraph_sample/tools/BPF-tools/old/2017-12-23/
export PATH=$PATH:/home/workspace/prog-playground/flamegraph_sample/tools/FlameGraph
# 工具执行有点小语法错误,按提示修改即可
fileiostacks.py -f 5 > out.stacks
flamegraph.pl --color=io --title="File I/O Time Flame Graph" --countname=us < out.stacks > fileio_out.svg
stress模拟压力采集的信息比较简单,用sysbench写MySQL来构造数据。
1
2
3
4
5
6
7
8
9
sysbench /usr/share/sysbench/oltp_read_write.lua \
--mysql-host=localhost \
--mysql-port=3306 \
--mysql-user=root \
--mysql-password=test \
--mysql-db=xdtestdb \
--tables=4 \
--table-size=100 \
prepare
但是都没抓到详细堆栈,写了个demo用gcc -g编译也只抓到简单堆栈,暂不去纠结了,后续按需再研究(老工具可能不大适用)。
自己的长这样。。。:

贴一个FlameGraph GitHub里的示例,卖家秀:

6. 红蓝差分火焰图
6.1. 介绍
红蓝差分火焰图,可以对比前后火焰图的函数差异,参考:Differential Flame Graphs。
火焰图步骤和说明:
- 1)采集堆栈1
- 2)再采集堆栈2
- 3)基于堆栈2生成一个火焰图,所有的函数帧都会以堆栈2为准
- 4)根据
堆栈2-堆栈1的差值对上面的火焰图染色,如果2中出现的帧次数更多,则是红色,如果次数更少则是蓝色- 红蓝颜色的饱和度是表示差距大小,颜色越深表示次数相差越大
difffolded.pl为生成差分堆栈的脚本,选项和应用场景说明:
-n格式化第一个堆栈文件中的计数,以和第2个堆栈文件匹配- 如果不加该参数,那么在其他时间采集堆栈时,如果负载不一样,负载增加的话则所有堆栈都会显示红色,负载减少则都会显示蓝色
- 增加
-n参数则会平衡第一个堆栈的采集内容,得到一个更全面的红蓝频谱 - 小结:建议加上
-n
-x有些采集工具会包含十六进制的地址,加该选项会进行兼容- 比如上面用libbpf-tools编译的
wakeuptime,采集结果就是带了地址,而使用bcc tools的python版本则会自行处理这些地址
- 比如上面用libbpf-tools编译的
- 另外,生成火焰图的
flamegraph.pl脚本,--negate参数可以交换颜色,红蓝反过来。使用场景说明:- 当第2次堆栈采集时,如果相比第一次部分业务或者负载没有了,则第2个堆栈里根本没有这部分堆栈,这时以第2个堆栈为准生成差分火焰图时,都不会有这部分蓝色的显示。
- 此时就可以以第一个堆栈文件为准(即生成差分堆栈时,交换文件顺序),然后生成火焰图时调转红蓝颜色,这样生成的火焰图就比较明显了,还是第2个堆栈里函数少则显示蓝色,第2个堆栈多则显示红色。
- 小结:建议两种都生成一把,避免遗漏关键信息
1
2
3
4
5
6
7
8
[CentOS-root@xdlinux ➜ red-blue-diff git:(main) ✗ ]$ difffolded.pl -h
USAGE: /home/workspace/FlameGraph/difffolded.pl [-hns] folded1 folded2 | flamegraph.pl > diff2.svg
-h # help message
-n # normalize sample counts
-s # strip hex numbers (addresses)
See stackcollapse scripts for generating folded files.
Also consider flipping the files and hues to highlight reduced paths:
/home/workspace/FlameGraph/difffolded.pl folded2 folded1 | ./flamegraph.pl --negate > diff1.svg
6.2. 实验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 1、采集1
# stress -c 4 -m 2 -i 4
perf record -F 99 -a -g sleep 30
perf script > out.stack1
# 2、采集2
# stress -c 2 -m 6 -i 1
perf record -F 99 -a -g sleep 30
perf script > out.stack2
# 3、折叠采集的两个堆栈
stackcollapse-perf.pl out.stack1 > out.folded1
stackcollapse-perf.pl out.stack2 > out.folded2
# 4、生成差分火焰图(实际使用时建议指定`-n`,时间跨度比较大时生成的对比更全面一点)
# difffolded.pl -n out.folded1 out.folded2 | flamegraph.pl > red-blue-diff-flamegraph_based2.svg
difffolded.pl out.folded1 out.folded2 | flamegraph.pl > red-blue-diff-flamegraph_based2.svg
生成的图如下:

分析:
- 第2次
stress加的压力,CPU更小(-c 2),内存更大(-m 6),io更小(-i 1) - 可看到
- 表示CPU压力的
__random计算是蓝色,说明堆栈2中函数次数减少; - 表示内存的
clear_page_erms处理很深,说明此处增加了不少; - 表示io的sync底部是浅红(应该是要减少的?蓝色?),但上面的 sync_fs_one_sb 是蓝色的(只有一点点,不明显),有减少
- 针对该情况,可使用下面的
--negate,注意传给difffolded.pl两个堆栈文件的顺序是反的
- 针对该情况,可使用下面的
- 表示CPU压力的
1
2
3
4
5
# difffolded.pl 加 -n 选项
difffolded.pl -n out.folded1 out.folded2 | flamegraph.pl > red-blue-diff-flamegraph_based2-n.svg
# flamegraph.pl 加 --negate;且传给 difffolded.pl 的堆栈,第2个在前面!
difffolded.pl out.folded2 out.folded1 | flamegraph.pl --negate > red-blue-diff-flamegraph_based1-negate.svg
red-blue-diff-flamegraph_based2-n.svg,和之前差别不大,因为2次:

red-blue-diff-flamegraph_based1-negate.svg,可以明显看到io相关函数次数的减少了(红蓝还是表示相同含义):

6.3. 应用脚本
将上面的内容提炼为脚本,供平常使用。生成两种差分火焰图,一个是默认方式:以堆栈2为基础,展示变化;一个是以堆栈1为基础,以防止堆栈2(比如代码优化后的程序)删除部分逻辑后,遗漏这部分差别。
利用LLM生成(这部分工作最好基于推理来做,勾选“深度思考”,要不车轱辘话很磨人),完整脚本见:gen_diff_flamegraph。
1
2
3
4
5
6
7
8
9
# 生成主对比图(新版本变化视图)
echo -e "\033[34m▶ 生成主对比图(显示新版本的变化)...\033[0m"
difffolded.pl -n $BASE_FILE $COMPARE_FILE | \
flamegraph.pl --title "Differential $COMPARE_FILE vs $BASE_FILE" > diff_${COMPARE_FILE}_vs_${BASE_FILE}.svg
# 生成互补视图(捕获旧版本特有内容)
echo -e "\033[34m▶ 生成互补视图(避免遗漏基准版本的路径变化)...\033[0m"
difffolded.pl -n $COMPARE_FILE $BASE_FILE | \
flamegraph.pl --negate --title "Complementary $BASE_FILE vs $COMPARE_FILE" > diff_${BASE_FILE}_complement.svg
提示还是比较到位的,效果如下:
7. CPI火焰图
差分火焰图的一个应用场景是 CPI火焰图,可见:CPI Flame Graphs: Catching Your CPUs Napping。
背景:
CPU利用率并不能知道CPU在干嘛,因为CPU可能执行到一条指令就停下来等待资源了。从用户角度看,CPU还是在被使用状态,但是实际上,指令并没有有效地执行,CPU在忙等,这种CPU利用率并不是有效的利用率。- 要发现CPU在 busy 的时候实际上在干什么,最简单的方法就是测量平均
CPI。CPI高说明运行每条指令用了更多的周期。这些多出来的周期里面,通常是由于流水线的停顿周期 (Stalled Cycles) 造成的,例如,等待内存读写。
CPI火焰图,可以基于CPU火焰图,提供一个可视化的基于 CPU利用率 和 CPI指标,综合分析程序CPU执行效率的方案。
具体可了解:用 CPI 火焰图分析 Linux 性能问题,以及 CPU Utilization is Wrong。
CPI 火焰图的生成依赖以下两个关键 CPU 事件:
cpu_clk_unhalted.thread_p:表示 CPU 运行的周期数resource_stalls.any:表示流水线停顿的周期数(如内存访问延迟)- 说明:对于 Intel 处理器,可直接使用这些事件;AMD 处理器需替换为等效事件(如 ex_ret_stall.any)
8. 小结
准备异步demo实验,并进行性能分析,本篇先介绍了 gperftools 和 火焰图。实验了各类火焰图的生成简要分析,回顾了bcc/perf-tools等之前涉及的工具。
留了一个TODO:wakeup火焰图中,关于唤醒者调用方向的问题,后续跟踪梳理CPU进程/线程调度时再打开。 (下篇实践时梳理清楚了,是bcc tools和bcc libbpf-tools采集时结果方向不同,bcc tools里面处理过了。上文已更新。)
经验:火焰图场景,后续保持bcc tools和火焰图一致,不要用自己编译的bcc libbpf-tools,统一方式避免额外的理解成本。
下一步进行异步编程并使用本篇工具分析。